
شبکه عصبی DenseNet که مخفف شبکه کانولوشنال چگال (Dense Convolutional Neural Network) است یک نوع شبکه عصبی پیچشی است. این شبکه عصبی بهمنظور افزایش کارایی در زمینههای بینایی ماشین و تجزیهوتحلیل تصویر بهینهسازی شده است. این مدل در سال ۲۰۱۷ معرفی شده و بهدلیل تواناییهای خود در کاهش مشکلات مربوط به محوشدن گرادیان و بهبود کارایی آموزشی بهسرعت موردتوجه قرار گرفته است. این ویژگیها به شبکه عصبی DenseNet اجازه میدهند تا با دقت بالایی در شناسایی و تجزیهوتحلیل تصویرهای مورداستفاده قرار گیرد که این امر برای کاربردهای پیچیده در حوزه بینایی ماشین ایدهآل است.
- 1. ایده اصلی شبکه عصبی DenseNet چیست؟
- 2. مزایای استفاده از شبکه عصبی DenseNet
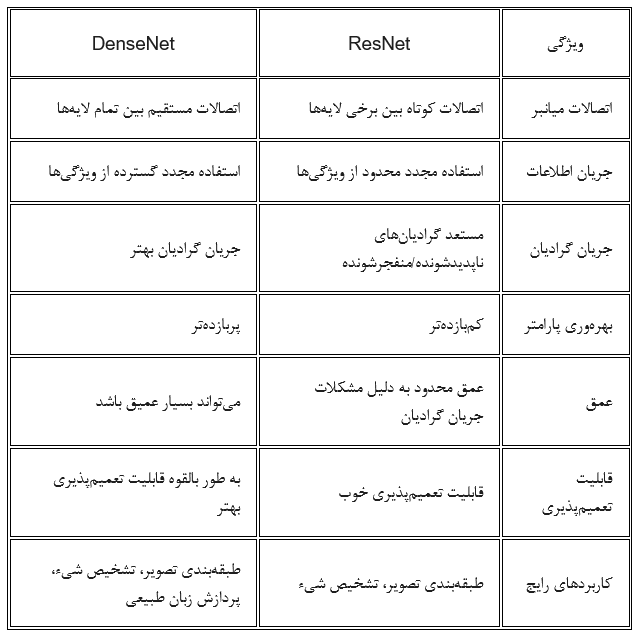
- 3. مقایسه ResNet و DenseNet
- 4. معماری شبکه عصبی DenseNet
- 5. نمای کلی از معماری DenseNet
- 6. پیادهسازی شبکه عصبی DenseNet در پایتون
- 7. کاربردهای DenseNet
- 8. آینده و پیشرفتهای احتمالی در DenseNet
- 9. جمعبندی
-
10.
پرسشهای متداول
- 10.1. چه تفاوتهای اصلی میان DenseNet و دیگر معماریهای شبکههای عصبی مانند ResNet وجود دارد؟
- 10.2. DenseNet چگونه مشکل ناپدیدشدن گرادیان (Gradient Vanishing) را حل میکند؟
- 10.3. در چه زمینههایی استفاده از DenseNet مفید است و چرا؟
- 10.4. چگونه میتوان کارایی DenseNet را در پلتفرمهای با منابع محاسباتی محدود بهینهسازی کرد؟
- 10.5. پیشرفتهای اخیر در معماری DenseNet بر توسعه فناوریهای آینده چه تأثیری میگذارد؟
- 11. یادگیری ماشین لرنینگ را از امروز شروع کنید!
ایده اصلی شبکه عصبی DenseNet چیست؟
ایده اصلی شبکه عصبی DenseNet ایجاد اتصالات مستقیم میان تمامی لایههای مختلف شبکه است. این اتصالات مستقیم به این میانجامد که اطلاعات و گرادیانها بهراحتی در کل شبکه جریان یابند و از مشکلاتی مانند ناپدیدشدن گرادیان و انفجار گرادیان جلوگیری میکنند.
این رویکرد در طراحی شبکههای عصبی به افزایش چشمگیر در دقت و کارایی آموزش کمک کرده است که این بهنوبه خود، تأثیرات مثبتی بر روی عملکرد کلی شبکه دارد.
مزایای استفاده از شبکه عصبی DenseNet
یکی از بزرگترین مزایای شبکه عصبی DenseNet کارایی بالای آن در شرایط مختلف تصویربرداری است. این مدل توانایی تجزیهوتحلیل تصاویر با دقت بالا را دارد، حتی در شرایطی که دادهها نویز یا اختلالات دارند. این قابلیتها DenseNet را به گزینهای ایدهآل برای استفاده در زمینههایی نظیر پزشکی تبدیل کرده است، جایی که دقت بالا در تشخیص و تجزیهوتحلیل تصویرها حیاتی است. در کل DenseNetها، بهدلیل معماری منحصربهفرد خود، مزایای متعددی در مقایسه با دیگر شبکههای عصبی عمیق دارند:
جریان اطلاعات و گرادیان بهتر
اتصالات مستقیم میان لایهها جریان اطلاعات و گرادیانها را در سراسر شبکه تسهیل میکند. این امر به هر لایه اجازه میدهد تا از ویژگیها و دانش لایههای قبلی بهطور مؤثر استفاده کند و بهنوبه خود، به یادگیری دقیقتر و جامعتر میانجامد.
غلبه بر مشکلات ناپدیدشدن و انفجار گرادیان
DenseNetها، با کمک به حفظ گرادیانها در طول فرایند آموزش، مشکل ناپدیدشدن گرادیان را که در شبکههای عمیق رایج است حل می کنند. این امر، بهنوبه خود، از انفجار گرادیان نیز جلوگیری میکند که می تواند به ناپایداری و افت عملکرد بینجامد.
کارایی پارامتر
DenseNetها بهطور کلی از نظر پارامتر کارآمدتر هستند، بهاین معنی که برای دستیابی به دقت مشابه به تعداد کمتری از پارامترها در مقایسه با دیگر معماریهای شبکه های عمیق نیاز دارند. این امر به مدلهای کوچکتر و قابل مدیریتتر میانجامد که به محاسبات کمتری نیاز دارند و میتوانند بهطور بالقوه، روی دستگاههای با توان پردازشی محدود اجرا شوند.
عمق شبکه
DenseNetها میتوانند بهطور چشمگیری عمیقتر از دیگر شبکههای عصبی عمیق باشند. این عمق به آنها امکان میدهد تا مدلهای پیچیدهتری را یاد بگیرند و در وظایف چالشبرانگیزتر مانند تشخیص تصویر و پردازش زبان طبیعی عملکرد بهتری داشته باشند.
قابلیت تعمیمپذیری
DenseNetها بهطور کلی از نظر قابلیت تعمیمپذیری بهتر هستند، بهاین معنی که میتوانند روی مجموعه دادههای جدید بدون نیاز به تنظیم دقیق زیاد آموزش ببینند. این امر آنها را برای کاربردهای دنیای واقعی که اغلب با دادههای محدود یا برچسبگذاریشده با کیفیت پایین مواجه هستند مناسبتر میکند.
پیشنهاد میکنیم همچنین درباره معماری U-Net مطالعه کنید.
مقایسه ResNet و DenseNet
در شبکههای عصبی عمیق با افزایش عمق شبکه، مشکلاتی مانند ناپدیدشدن گرادیان و انفجار گرادیان نیز پدیدار میشوند. این مشکلات مانع از آموزش مؤثر شبکههای بسیار عمیق میشوند.

دو معماری قدرتمند ResNet و DenseNet تلاش کردهاند تا بر این چالش غلبه کنند و به عمق و کارایی بالاتر در شبکههای عصبی دست یابند. هر یک از این دو رویکرد منحصربهفردی را برای دستیابی به این هدف اتخاذ کردهاند که در ادامه آنها را بررسی کردهایم:
ResNet و میانبر برای عبور از موانع
ResNet از اتصالات کوتاه (skip connections) برای میانبرزدن میان لایهها استفاده میکند. این اتصالات به گرادیانها اجازه میدهد تا بهراحتی ازطریق شبکه جریان یابند و از مشکلات ناپدیدشدن یا انفجار آنها جلوگیری کنند. ResNet با این ترفند توانست شبکههای بسیار عمیق بسازد و به نتایج قابلتوجهی در زمینههای مختلف دست یابد.
برای آشنایی دقیق با مدل ResNet میتوانید مقاله شبکه عصبی رزنت (ResNet) چیست و چگونه مشکل ناپدید شدن گرادیان در شبکههای بسیار عمیق را حل کرده است؟ را مطالعه کنید.
شبکه عصبی DenseNet و اتصالات مستقیم برای جریان بهتر اطلاعات
DenseNet یک رویکرد جسورانه را در پیش میگیرد. در شبکه عصبی DenseNet هر لایه مستقیماً به همه لایههای بعدی متصل میشود. این اتصالات مستقیم کمک میکند تا اطلاعات و گرادیانها بهراحتی در کل شبکه جریان یابند و از مشکلات مربوط جلوگیری شود. DenseNet همچنین بهدلیل استفاده مجدد گسترده از ویژگیها در لایههای مختلف از نظر پارامتر کارآمدتر است.
کدامیک برنده است؟
ResNet و DenseNet معماریهای قدرتمندی هستند که مزایا و معایب خاص خود را دارند. انتخاب میان آنها به عوامل مختلفی مانند اندازه مجموعه داده، وظیفه مدنظر و منابع محاسباتی در دسترس بستگی دارد، اما بهطور کلی، شبکه عصبی DenseNet بهدلیل عمق بیشتر و کارایی بالاتر در پارامتر، برای وظیفههای چالشبرانگیزتر و مجموعه دادههای بزرگتر، انتخابی جذاب به نظر میرسد.
معماری شبکه عصبی DenseNet
معماری شبکههای کانولوشنی تراکمی (DenseNet) یک ساختار پیشرفته شبکه عصبی است که به چالشهای مواجهشده توسط شبکههای کانولوشنی معمولی، بهویژه زمانی که بسیار عمیق هستند، پرداخته است. در اینجا چگونگی کارکرد شبکه عصبی DenseNet را بهصورت دقیق توضیح میدهیم. برای اینمنظور لازم است با برخی مفاهیم موجود در این معماری که در مقاله اصلی آن، به آنها اشاره شده است، آشنا شوید:
اتصال مستقیم لایهها
در معماری شبکه عصبی DenseNet هر لایه بهطور مستقیم به تمامی لایههای بعدی متصل میشود؛ این بهآن معناست که خروجی هر لایه بهعنوان ورودی برای تمامی لایههای بعدی استفاده میشود. این امر به بهبود جریان اطلاعات و گرادیانها در شبکه میانجامد و مشکل محوشدن گرادیان را کاهش میدهد.
واحدهای تراکمی
شبکههای DenseNet شامل واحدهای تراکمی (Dense Blocks) هستند که در آنها هر لایه به تمامی لایههای بعدی متصل میشود. میان این بلوکها، لایههای انتقالی قرار دارند که اندازه نقشههای ویژگی را تغییر میدهند.
نرخ رشد
در DenseNet، نرخ رشد تعریف میشود که تعداد ویژگیهای تولید شده توسط هر لایه را مشخص میکند. این نرخ کمک میکند تا تعادل بین کارایی و عمق مدل حفظ شود.
حال که با مفاهیم اولیه این معماری آشنا شدید، میتوانید نحوه عملکرد این شبکه عصبی را بهخوبی بفهمید. در ادامه بهبررسی شیوه کارکرد هر یک از قسمتهای این معماری را توضیح خواهیم داد.
واحدهای تراکمی چطور کار میکنند؟
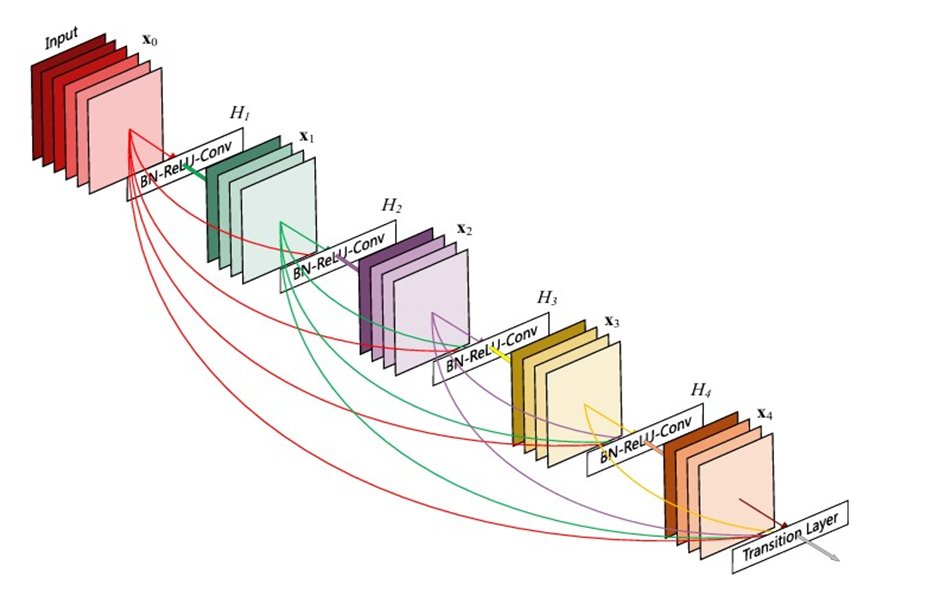
بیایید کمی دقیقتر عملکرد هر واحد تراکمی را که در شکل زیر مشخص شده است بررسی کنیم. فرض کنید یک عکس با نماد X0 داریم که قرار است بهعنوان ورودی به واحد تراکمی داده شود. هر واحد تراکمی از L لایه تشکیل شده که در شکل ما این عدد برابر ۴ است. هر لایه ترکیبی از Batch Normalization تابع فعالساز ReLU و یک کانولوشن ۳x۳ است که برای لایه ILم آن را HL و خروجی لایه ام را XL مینامیم.
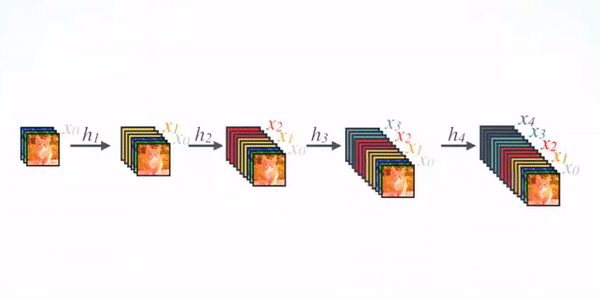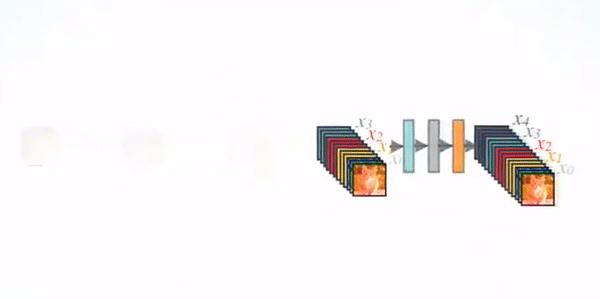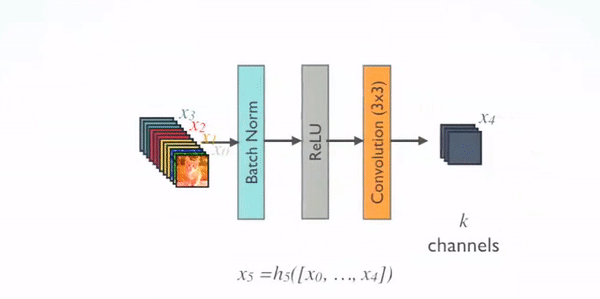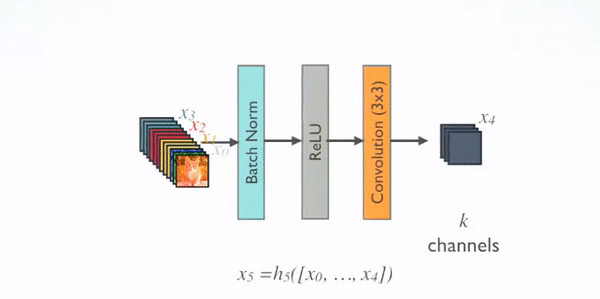
همانطور که در مقاله ResNet توضیح دادیم، در این مدل خروجی هر لایه به عنوان ورودی به لایه بعدی داده میشود که معادله آن در اینجا بهصورت XL = HL(XL-1) + XL-1 در میآید. این واحدها در رزنت بهعنوان واحد باقیمانده یا Residual block نام برده شده است. این کار باعث رفع مشکل محوشدگی گرادیان میشود. همین اتفاق در DenseNet با استفاده از واحدهای تراکمی میافتد، با این تفاوت که در ResNet ورودی هر واحد باقیمانده با خروجی همان واحد جمع جبری میشود که ممکن است جریان اطلاعات در شبکه را مختل کند، اما محققان معماری DenseNet برای بهبود بیشتر جریان اطلاعات میان لایهها، الگوی اتصالی متفاوتی را پیشنهاد کردند: اتصالات مستقیم از هر لایه به تمامی لایههای بعدی.
شکل زیر، بهصورت شماتیک، طرح حاصل از شبکه عصبی DenseNet را نشان میدهد؛ همانطور که مشخص است، لایه ILم Feature map تمامی لایههای قبلی را بهعنوان ورودی دریافت میکند: XL = HL([X0, … , XL-1])
جایی که [X0, … , XL-1] به اتصالات تراکمی اشاره میکند که به این معماری شبکه کانولوشنی تراکمی یا DenseNet میگوییم. برای سادگی در پیادهسازی ورودیهای حاصل از لایههای قبلی HL را در معادله بهجای جمع، با یکدیگر ادغام (Concatenate) میکنیم.

لایههای انتقالی چطور ابعاد نقشه ویژگی را کاهش میدهند؟
نکته اینجاست که عملیات ادغامی که در این معادله استفاده میشود، زمانی که اندازه Feature mapها تغییر کند، قابلاستفاده نیست. بااینحال یکی از بخشهای ضروری شبکههای کانولوشنی لایههای Down sampling هستند که اندازه Feature map را تغییر میدهند. برای مثال، در مرحلههایی از شبکه که میخواهیم پیچیدگی مدل را کاهش دهیم یا میخواهیم فیلترهای بیشتری را به Feature map اضافه کنیم، باید اندازه Feature map را کوچکتر کنیم.
برای حل این مشکل، معماری شبکه عصبی DenseNet را به واحدهای مختلف تقسیم میکنیم که هر واحد شامل چندین لایه متصلبههم است. میان این واحدهای تراکمی لایههایی را قرار میدهیم که آنها را لایههای انتقالی (transition layers) مینامیم. این لایههای انتقالی عملیات Down sampling را انجام میدهند، یعنی اندازه Feature mapها را کوچکتر میکنند تا بتوانیم به تجزیهوتحلیلهای بیشتری در لایههای عمیقتر برسیم.
در مدلهایی که نویسندگان مقاله DenseNet از آنها استفاده کردهاند، لایههای انتقالی از یک لایه Batch Normalization، سپس یک لایه کانولوشنی ۱x۱ و سپس یک لایه Average Pooling با اندازه ۲x۲ تشکیل شدهاند تا اندازه ویژگیها را بهصورت موثر کاهش دهند. با این کار وظیفه کاهش بعد بر عهده لایههای انتقالی خواهد بود، اما در هر واحد تراکمی، اندازه هر Feature map ثابت میماند تا عملیات Concatenation با مشکل مواجه نشود.
نرخ رشد چه تاثیری در افزایش کارایی این معماری دارد؟
نرخ رشد در DenseNet که با K نمایش داده میشود، تعداد Feature mapهایی است که توسط هر لایه اضافه میشود؛ برای مثال، اگر نرخ رشد K باشد و لایه ورودی K0 کانال داشته باشد، لایه Iام شبکه ورودیهایی معادل با: K0 + K(I-1) فیلتر خواهد داشت که شامل Feature mapهای تولیدشده توسط تمامی لایههای پیشین است؛ این بهآن معناست که هر لایه جدید ویژگیهای تمامی لایههای قبل از خود را بهعنوان دانش موجود دریافت میکند و علاوهبراین، ویژگیهای جدید خود را نیز اضافه میکند.
یکی از جنبههای منحصربهفرد DenseNet نسبت به معماریهای دیگر این است که لایههای آن میتوانند بسیار باریک باشند، بهاین معنی که به تعداد کمتری فیلتر یا کانال در هر لایه نیاز دارند تا همان دانش را منتقل کنند. این امر به کاهش تعداد پارامترهای موردنیاز و افزایش کارایی شبکه کمک میکند. نتایج آزمایشها نشان دادهاند که حتی با نرخ رشد نسبتاً کوچک، شبکه عصبی DenseNet میتواند نتایج رقابتی و برجستهای را در مجموعه دادههای مختلف به دست آورد.
این موضوع نشاندهنده این است که شبکه بهطور مؤثری از دانش مشترک تمامی لایهها استفاده میکند و به هر لایه اجازه میدهد تا از اطلاعات و ویژگیهای کشفشده توسط همهی لایههای قبلی بهرهمند شود. بهاین ترتیب، اطلاعات موردنیاز برای تصمیمگیری یا دستهبندی در لایههای آخر شبکه حاصل جمع دانش جمعآوریشده از کل شبکه است و به تکرار ویژگیها در هر لایه نیازی نیست. این امر خود به کاهش بار محاسباتی و بهینهسازی استفاده از منابع میانجامد.
فشردهسازی چه نقشی در کاهش پیچیدگی مدل دارد؟
در معماری شبکه عصبی DenseNet یکی از تکنیکهای مهم برای بهبود کارایی و کاهش پیچیدگی مدل، فشردهسازی نقشههای ویژگی در لایههای انتقالی است. این تکنیک با کاهش تعداد نقشههای ویژگی که از بلوکهای تراکمی (Dense Blocks) به یکدیگر منتقل میشوند کار میکند. بهطور خاص، عامل فشردهسازی مشخص میکند که چه درصدی از نقشههای ویژگی در لایه انتقالی حفظ شود.
اگر θ = 1 باشد، تعداد Feature mapها در لایههای انتقالی بدون تغییر باقی میماند، یعنی هیچ فشردهسازی اعمال نمیشود و تمامی ویژگیها از واحد قبلی به واحد بعدی منتقل میشوند.
اگر θ کمتر از ۱ باشد، تعداد نقشههای ویژگی کاهش مییابد؛ برای مثال، اگر θ برابر ۰.۵ باشد، فقط نیمی از Feature mapها از بلوک قبلی به بلوک بعدی منتقل خواهند شد. این کار مزایایی دارد که در ادامه آنها را بررسی میکنیم:
- کاهش پیچیدگی محاسباتی: با کاهش تعداد Feature mapها، محاسبات کمتری برای پردازش لازم است که به بهبود سرعت آموزش و پردازش کمک میکند.
- کاهش خطر بیشبرازش (Overfitting): با کمترکردن ویژگیهایی که به شبکه داده میشود، احتمال یادگیری نویز و جزئیات غیرضروری کاهش مییابد.
- افزایش کارایی استفاده از حافظه: با کاهش تعداد Feature mapها، حافظه کمتری مصرف میشود. این امر در پلتفرمهایی با منابع محدود مانند دستگاههای موبایل و سیستمهای تعبیهشده (Embedded) بسیار مفید است.
نمای کلی از معماری DenseNet
حال که با نحوه عملکرد بخشهای مختلف معماری DenseNet آشنا شدید، بیایید با کنار هم قراردادن آنها، یک معماری کامل DenseNet را ببینیم:

در شکل بالا که یک نمای کلی از معماری DenseNet را نشان میدهد، تصویر یک اسب بهعنوان ورودی به مدل داده شده است.
سپس این عکس از یک لایه کانولوشنی اولیه با سایز ۳x۳ رد میشود تا ویژگیهای اولیهاش استخراج گردد.
بعد از این لایه، اولین واحد تراکمی را میبینیم. همانطور که گفتیم واحدهای تراکمی شامل چندین لایه هستند که به طور مستقیم به یکدیگر متصل شدهاند و ویژگیهای استخراج شده از لایههای قبلی را دریافت میکنند. در این تصویر، از سه واحد تراکمی استفاده شده است.
همچنین بین واحدهای تراکمی، لایههای انتقالی قرار دارند که شامل Batch Normalization، کانولوشن ۱x۱ و AveragePooling هستند. این لایهها اندازه Feature mapها را کاهش میدهند و پیچیدگی مدل را تنظیم میکنند.
پس از آخرین واحد تراکمی، یک لایه Pooling و سپس یک لایه Fully Connected قرار میگیرد که وظیفه کلاسبندی تصویر ورودی را برعهده دارد.
پیادهسازی شبکه عصبی DenseNet در پایتون
در این بخش پیادهسازی معماری DenseNet را در فریمورک کراس خواهید دید.
طراحی تابع HL
در ابتدا لازم است نحوه پیادهسازی تابع ترکیبی HL را ببینیم:

همانطور که در کد میبینید، برای ساخت یک تابع HL ابتدا ورودی را از Batch Normalization رد میکنیم. سپس از تابع فعالساز ReLU استفاده کرده و ابعاد خروجی حاصل را با Zero Padding یک واحد از هر طرف افزایش میدهیم؛ زیرا در لایه بعدی میخواهیم از کانولوشن ۳x۳ استفاده کنیم که ابعاد ورودی را یک واحد کم میکند، بنابراین نیاز است از قبل با Zero Padding یک واحد به ابعاد ورودی اضافه کنیم تا شاهد تغییر بعد نباشیم.
درنهایت، برای جلوگیری از بیشبرازش (Overfitting) از Dropout استفاده میکنیم. تعداد فیلترهایی را هم که میخواهیم Feature map خروجی داشته باشد بهعنوان ورودی تحت متغیر num_filters به تابع میدهیم.
طراحی واحد تراکمی
در قسمت بعد لازم است ساخت یک واحد تراکمی را ببینیم:

در این تابع ابتدا به تعداد num_layers (یا همان L) که در ورودی هر واحد مشخص میشود، تابع H را فراخوانی میکنیم و در هر مرحله، خروجی تابع H را با ورودی ادغام میکنیم و سپس به عنوان ورودی لایه بعدی از آن استفاده میکنیم. این همان ایده اصلی DenseNet برای استفاده مستقیم از خروجی هر لایه در لایه بعدی است. بعد از ریختن Feature mapهای تولید شده در متغیر input (برای لایه بعدی) تعداد فیلترها را به اندازه نرخ رشد زیاد میکنیم تا خروجی تابع H لایه بعدی، فیلترهای بیشتری داشته باشد و در نتیجه ظرفیت یادگیری افزایش پیدا کند. درواقع بعد از اتمام اجرای یک واحد تراکمی، تعداد فیلترهای اولیه (num_filters) بهاندازه growth_rate* num_layers زیاد میشود.
طراحی لایه انتقال
در کد زیر میتوانید نحوه پیادهسازی لایه انتقالی که بعد از هر واحد تراکمی قرار میگیرد و نقش کمکردن ابعاد را دارد ببنید:

compression_factor یا نرخ تراکم یک عدد میان ۰ و ۱ است که وظیفه کمکردن تعداد کرنلهای Feature map را دارد. این کار با کفگرفتن از حاصلضرب نرخ تراکم در تعداد کرنلهای ورودی تابع انتقالی (یا همان خروجی واحد تراکمی قبلی) و تنظیم عدد حاصل (طبیعتاً کمتر از تعداد کرنلهای ورودی است) بهعنوان تعداد فیلترهای کانولوشن ۱x۱ پیشرو انجام میشود. در پایان بعد از Dropout، لایه Average Pooling با سایز ۲x۲ ابعاد Feature mapها را نصف میکند.
طراحی کامل یک معماری DenseNet
حال که بخشهای مختلف معماری DenseNet را طراحی کردیم، میتوانیم یک نمونه کامل از این معماری را بسازیم:
لایه ورودی
برای این منظور ابتدا لازم است یک لایه ورودی با ابعاد مشخص که با input_shape تعریف میشود، ایجاد کنیم. این لایه دادههای ورودی را دریافت میکند:

لایه کانولوشن اولیه
سپس لایه کانولوشن اولیه را روی این لایه اعمال میکنیم:

این لایه، یک کانولوشن دو بعدی با تعداد فیلترهای مشخص (num_filters) و سایز کرنل ۳x۳ ایجاد میکند. در این کانولوشن از he_normal برای مقداردهی اولیه وزنها و از L2 برای منظمسازی (regularization) استفاده میشود.
قراردادن واحدهای تراکمی
در قسمت بعد باید واحدهای تراکمی و لایههای انتقالی بینشان را که از قبل آنها را طراحی کردهایم، قراردهیم:
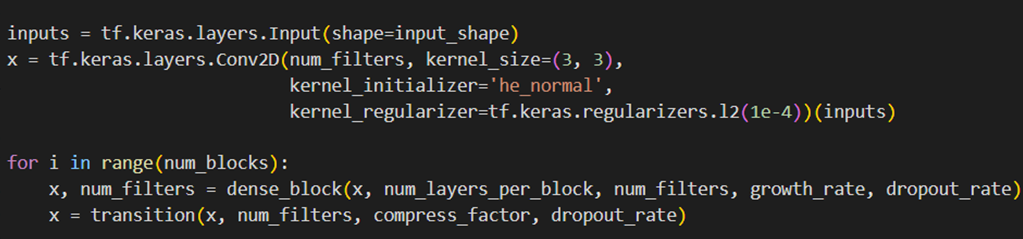
این بخش شامل یک حلقه است که به تعداد num_blocks واحد تراکمی و لایه انتقالی ایجاد میکند. در هر واحد:
- تابع dense_block یک واحد تراکمی ایجاد میکند که شامل چندین لایه کانولوشنی به هم متصل است.
- تابع transition یک لایه انتقالی ایجاد میکند که اندازه Feature mapsها را کاهش میدهد و پیچیدگی مدل را تنظیم میکند.
- متغیر num_filters تعداد فیلترهای بهروزشده بعد از هر واحد تراکمی را ذخیره میکند. بهاینترتیب تعداد فیلترهایی که برای اولین لایه واحد تراکمی بعدی استفاده میشود، برابر تعداد فیلترهایی است که در واحد قبلی بهاندازه growth_rate* num_layers زیاد شده است.
لایههای پایانی
بعد از قراردادن واحدهای تراکمی، حال نوبت به ساخت لایههای پایانی و انجام کلاسبندی تصویر ورودی است. خروجی آخرین لایه انتقال به یک GlobalAveragePooling2D وارد میشود:

این لایه از همه کرنلهای Feature mapی که دریافت میکند، میانگین میگیرد. این کار باعث کاهش ابعاد داده و تبدیل آن به یک بردار بهاندازه تعداد کرنلهای آن Feature map میشود. به عبارت دیگر، GlobalAveragePooling2D به جای اعمال عملیات Pooling با اندازه پنجرههای کوچکتر (مثل ۲x۲)، میانگین تمامی عناصر یک کرنل را میگیرد.
سپس لایه Dense را قرار میدهیم. این لایه یک لایه کاملاً متصل (Fully Connected) است که تعداد نورونهای آن برابر با تعداد کلاسهای مورد نظر (num_class) است. در پایان نیز با استفاده از تابع فعالساز Softmax احتمال تعلق عکس ورودی به هر یک از کلاسهای مسئله را مشخص میکنیم:

کاربردهای DenseNet
شبکه عصبی DenseNet، بهدلیل ویژگیهای برجستهای که دارد، در زمینههای متعددی گسترش یافته است. این مدل به ویژه در حوزههایی که نیاز به تجزیهوتحلیل دقیق تصویر وجود دارد بسیار مؤثر است؛ برای مثال، در پزشکی DenseNet برای تشخیص دقیقتر بیماریهایی مانند سرطان پستان، آسیبهای پوستی و تغییرات پاتولوژیکی در تصاویر پزشکی، مانند MRI و CT Scan، به کار رفته است. توانایی این مدل در درک بهتر ساختارهای پیچیده و ویژگیهای باریک تصویر، امکان تشخیص زودهنگام بیماریها را فراهم و به پزشکان کمک میکند تا تصمیمهای درمانی بهتری اتخاذ کنند.
تشخیص اشیا
در حوزه تشخیص اشیا DenseNet بهدلیل قابلیتهای یادگیری عمیق و تجزیهوتحلیل دقیق ویژگیها، به شناسایی و دستهبندی اشیا در تصویرها و ویدئوها با دقت بالا کمک میکند. این توانایی در برنامههایی مانند نظارت تصویری، سیستمهای امنیتی خودکار و اتوماسیون صنعتی کاربرد فراوان دارد.
تشخیص چهره
از دیگر کاربردهای مهم شبکه عصبی DenseNet میتوان به تشخیص چهره اشاره کرد. در این زمینه DenseNet، بهعلت دقت بالا در تحلیل ویژگیهای چهره، قادر است تشخیص چهره را حتی در شرایط نوری نامطلوب یا با چهرههایی که جزئیات کمی دارند بهخوبی انجام دهد. این خصوصیت در برنامههایی مانند سیستمهای تشخیص هویت و کنترل دسترسی امنیتی بسیار مهم است.
تجزیهوتحلیل تصاویر ماهوارهای و سیستمهای خودروهای خودران
علاوه بر اینها، DenseNet در تجزیهوتحلیل تصاویر ماهوارهای و همچنین در سیستمهای کمکی خودروهای خودران برای درک بهتر محیط و تصمیمگیریهای لحظهای استفاده میشود. توانایی این شبکه در کار با تصویرهای با وضوح بالا و جزئیات دقیق، کاربردهای آن را در بخشهای مختلف صنعتی و تحقیقاتی گستردهتر میکند.
آینده و پیشرفتهای احتمالی در DenseNet
پیشرفتها در فناوریهای سختافزاری و تکنیکهای یادگیری ماشین میتوانند آینده و کاربرد شبکه عصبی DenseNet را بهشکل قابلتوجهی تحتتأثیر قرار دهند. انتظار میرود که با بهبود پردازندهها و واحدهای پردازش گرافیکی (GPU)، آموزش مدلهای پیچیدهتر و عمیقتر DenseNet در زمان کمتری امکانپذیر شود. این امر میتواند به توسعه سیستمهایی بینجامد که قادر به تحلیل تصاویر با وضوح بسیار بالا یا دادههای سهبعدی با جزئیات دقیقتر هستند و کاربردهایی در پزشکی پیشرفته، شبیهسازیهای علمی و مهندسی مواد دارند.
علاوهبراین، توسعه در روشهای شبکههای عصبی که به بهبود جریان گرادیان و پایداری آموزش کمک میکنند میتواند به حل مشکلات موجود در شبکههای عمیقتر بپردازد. مطالعات اخیر نشان دادهاند که تکنیکهای نوآورانه مانند یادگیری عمیق تقویتی بیشتر میتوانند بر این زمینه مؤثر باشند.
در نهایت، توجه بیشتر به اخلاق و شفافیت در مدلهای یادگیری ماشین، به ویژه در حوزههایی که مستقیماً بر روی سلامت و امنیت انسانها تأثیر میگذارند، ضروری است. اطمینان از اینکه مدلهای DenseNet به شیوهای اخلاقی و مسئولانه استفاده میشوند، میتواند به حفظ اعتماد عمومی و پذیرش گستردهتر این فناوریها کمک کند.
جمعبندی
در این مقاله شبکه عصبی DenseNet را بررسی کردیم، معماری پیشرفتهای از شبکههای عصبی کانولوشنال که برای کارآمدی خود در پردازش تصاویر در زمینههایی مانند تصویربرداری پزشکی و تشخیص اشیا شناخته شده است. با ایجاد اتصالات مستقیم میان تمامی لایهها، DenseNet جریان روان اطلاعات و گرادیانها را در سراسر شبکه تسهیل میکند، بهاین ترتیب، مسائلی مانند محو شدن گرادیان را کاهش میدهد و بازدهی پارامتری بهتری در مقایسه با دیگر معماریهای شبکههای عمیق فراهم میکند.
طراحی منحصربهفرد شبکه عصبی DenseNet به آن امکان میدهد با استفاده از تعداد پارامترهای کمتر به عمق بیشتر و عملکرد بهتری دست یابد. این امر آن را حتی در سختافزارهایی با قدرت محاسباتی محدود بسیار مؤثر میکند. پتانسیل برای کاربردهای گستردهتر در زمینههای مختلف نشاندهنده استحکام و انعطافپذیری آن است، بهویژه در وظایفی که نیازمند تجزیهوتحلیل دقیق و طبقهبندی تصویرها هستند.
با پیشرفت فناوری و الگوریتمهای یادگیری ماشین، آینده DenseNet بسیار امیدوارکننده به نظر میرسد، آنهم با امکان بهبودهای بالقوه در معماری شبکه و کارایی آموزش. این پیشرفتها میتوانند به توسعه شبکههای عمیقتر با قابلیتهای دقیقتر بینجامند و امکانات جدیدی برای کاربردهای نوآورانه در علم، پزشکی و صنعت فراهم آورند. توسعه مستمر شبکه عصبی DenseNet بدون شک به پیشرفتهای قابلتوجهی در زمینه یادگیری عمیق خواهد انجامید و به حل مسائل پیچیده دنیای واقعی با استفاده از بینایی ماشین کمک خواهد کرد.

پرسشهای متداول
چه تفاوتهای اصلی میان DenseNet و دیگر معماریهای شبکههای عصبی مانند ResNet وجود دارد؟
تفاوت اصلی میان DenseNet و دیگر شبکهها مانند ResNet در نحوه اتصال لایههاست. در DenseNet هر لایه بهصورت مستقیم به تمامی لایههای بعدی ازطریق اتصالات مستقیم متصل میشود. این امر به جریان بهتر اطلاعات و گرادیانها کمک میکند و مشکلات مربوط به ناپدیدشدن گرادیان را کاهش میدهد. همچنین ResNet از اتصالات کوتاه (Skip Connections) استفاده میکند که لایهها را فقط به چند لایه جلوتر متصل میکند. این دو رویکرد به بهبود کارایی آموزش کمک میکنند، اما DenseNet بهخصوص در حفظ و استفاده مجدد از ویژگیها در تمامی لایهها مؤثرتر است.
DenseNet چگونه مشکل ناپدیدشدن گرادیان (Gradient Vanishing) را حل میکند؟
DenseNet، با ایجاد اتصالات مستقیم میان همه لایهها، اطمینان حاصل میکند که گرادیانها میتوانند بهراحتی در طول شبکه جریان یابند. این روش جریان بهتر گرادیانها را تضمین میکند و به هر لایه اجازه میدهد تا از دادهها و گرادیانهای مربوط به لایههای قبل استفاده کند. این امر به کاهش مشکل ناپدیدشدن گرادیان کمک میکند و بهبود قابل توجه در کارایی و دقت آموزش را رقم میزند.
در چه زمینههایی استفاده از DenseNet مفید است و چرا؟
شبکه عصبی DenseNet به ویژه در زمینههایی که نیاز به تجزیهوتحلیل دقیق تصویر وجود دارد مفید است؛ برای مثال، در پزشکی DenseNet برای تشخیص دقیقتر بیماریهایی مانند سرطان و تغییرات پاتولوژیک در تصاویر پزشکی مانند MRI و CT Scan استفاده میشود؛ علاوهبراین در زمینه تشخیص اشیاء و تحلیل تصاویر ماهوارهای، قابلیتهای عمیق یادگیری DenseNet امکان شناسایی و دستهبندی دقیقتر اشیا را فراهم میکند که در نظارت تصویری و برنامههای امنیتی بسیار مفید است.
چگونه میتوان کارایی DenseNet را در پلتفرمهای با منابع محاسباتی محدود بهینهسازی کرد؟
بهینهسازی DenseNet در دستگاههای با منابع محدود میتواند ازطریق تکنیکهای کاهش پیچیدگی مدل مانند فشردهسازی مدل و استفاده از الگوریتمهای کارآمدتر برای تراکم دادهها و کاهش ابعاد ویژگیها صورت گیرد. این تکنیکها به کاهش تعداد عملیات محاسباتی لازم و حافظه موردنیاز کمک میکنند که امکان استفاده از DenseNet را روی پلتفرمهای موبایل و دیگر دستگاههای با توان پردازشی محدود فراهم میآورد.
پیشرفتهای اخیر در معماری DenseNet بر توسعه فناوریهای آینده چه تأثیری میگذارد؟
پیشرفتها در معماری چه شبکه عصبی DenseNet بهویژه در زمینههای بهینهسازی و فشردهسازی مدل میتوانند تأثیر قابلتوجهی بر توسعه فناوریهای آینده چشمگیری بگذارند. این پیشرفتها امکان ساخت مدلهایی را فراهم میآورند که قادر به تحلیل دادههای با حجم و پیچیدگی بالا هستند که در زمینههای مانند شبیهسازیهای علمی، مهندسی مواد و حتی در سیستمهای خودران کاربرد دارد که نیازمند تصمیمگیریهای سریع و دقیق هستند. این پیشرفتها به ساخت نسل جدیدی از سیستمهای هوش مصنوعی کمک میکنند که با سرعت و دقت بیشتری عمل میکنند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده شما را برای فرصتهای شغلی بسیاری مناسب میکند. شما، فارغ از رشته تحصیلی و پیشزمینه شغلیتان، میتوانید یادگیری این دانش را همین امروز شروع کنید و آن را از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
خوندن این مقاله واقعا لذت بخش بود. ممنون
سلام و عرض ادب،
خوشحالیم که مطلب براتون مفید بوده و نظرتون رو با ما به اشتراک گذاشتین.