
در دنیای پرشتاب تکنولوژی و هوش مصنوعی، مدلهای پیشبینی زبانی نقش محوری ایفا میکنند. یکی از پیشرفتهترین این مدلها، BERT (Bidirectional Encoder Representations from Transformers) است که توسط گوگل معرفی شده و انقلابی در پردازش زبان طبیعی ایجاد کرده است.
BERT با استفاده از تکنیکهای پیچیده مانند Transformer، توانسته است تا دقت مدلهای مبتنی بر متن را به طرز چشمگیری بهبود ببخشد. اهمیت BERT به حدی است که توسعهدهندگان و پژوهشگران، مدلهای مختلفی را بر پایه آن ایجاد کردهاند تا به بهینهسازی و تخصصیسازی بیشتری در زمینههای متفاوت برسند.
تاریخچه و توسعه BERT
معرفی BERT در سال ۲۰۱۸، به عنوان یک گام بزرگ در پردازش زبان طبیعی بود. این مدل با استفاده از معماری Transformer، که به طور خاص برای تحلیل متون طراحی شده بود، توانست نحوه درک ما از متون را دگرگون سازد. نوآوریهای اصلی این مدل شامل پردازش دوسویه متن (به جای یکسویه) و توانایی درک مفاهیم پیچیدهتر و زمینهای بود. این ویژگیها به BERT اجازه داد تا در وظایف مختلفی مانند ترجمه، خلاصهسازی و تشخیص نامها بسیار موفق عمل کند.
همچنین بخوانید: شبکه BERT چیست و در پردازش زبانهای طبیعی (NLP) چه نقشی دارد؟
مدلهای بر پایه BERT
در این بخش، ده مدل مختلف که از BERT گرفته شدهاند را معرفی میکنیم. هر کدام از این مدلها در زمینههای خاصی بهینهسازی شدهاند تا نیازهای متفاوتی را پوشش دهند. از RoBERTa که با تغییراتی در تنظیمات پیشآموزش بهبود یافته، تا ALBERT که با کاهش حجم مدل به افزایش سرعت و کارایی میپردازد. هر مدل با توجه به خصوصیات خاص خود، کاربردها و مزایای منحصر به فردی دارد.
RoBERTa
RoBERTa یا Robustly Optimized BERT Approach با حذف مرحله Next Sentence Prediction (NSP) و افزایش دادهها و طول آموزش، تواناییهای BERT را بهبود بخشیده است. این تغییرات به RoBERTa اجازه دادهاند تا در فهم متون و درک زمینههای پیچیدهتر بهتر عمل کند، که این امر به بهبود قابلیتهای ترجمه و تحلیل احساسات کمک میکند.
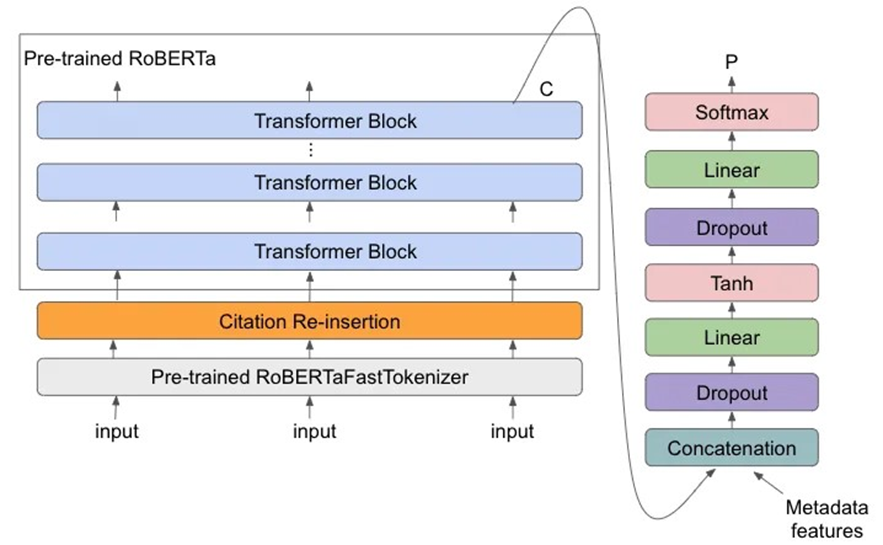
دادههای بیشتر
همانطور که گفته شد، یکی از تفاوتهای کلیدی بین RoBERTa و BERT در این است که RoBERTa با استفاده از دیتاست بسیار بزرگتری آموزش میبیند، که شامل بیش از ۱۶۰ گیگابایت داده متنی است، در حالی که BERT ابتدا با حدود ۱۶ گیگابایت داده متنی آموزش دیده بود. این امر به مدل اجازه میدهد تا از منابع مختلف یاد بگیرد و ظرافتهای زبانی را بهتر درک کند.
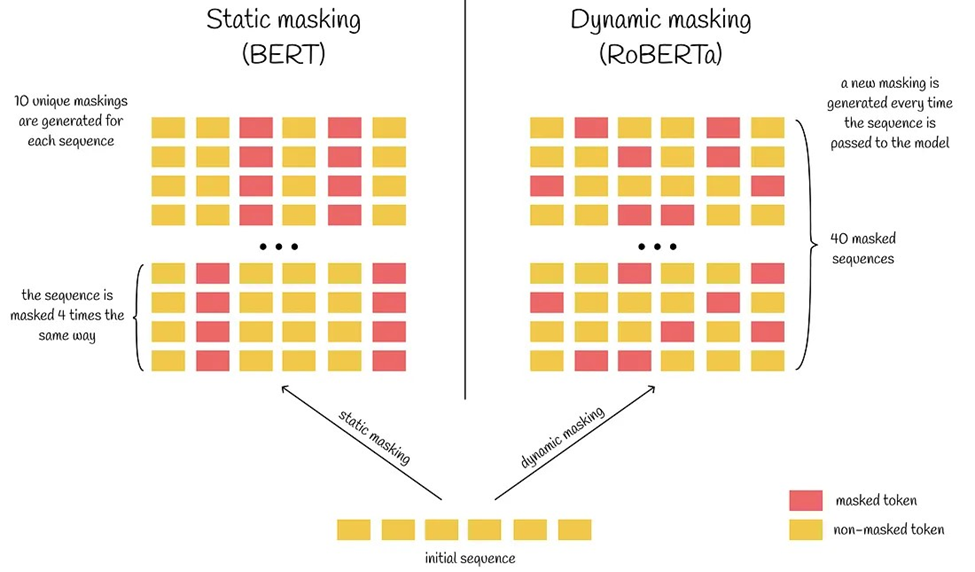
ماسکزنی پویا
تفاوت کلیدی دیگر در این است که روبرتا با استفاده از تکنیکی به نام ماسکزنی پویا (Dynamic masking) آموزش میبیند، که شامل پنهان کردن تصادفی نشانههای مختلف (مثلاً کلمات یا علائم نگارشی) در متن ورودی هنگام آموزش است. این کمک میکند تا مدل روابط بین نشانههای مختلف در یک جمله را بهتر درک کند و عملکرد خود را در وظایف مختلف بهبود بخشد.
برای مثال، بیایید جمله زیر را در نظر بگیرید:
من امروز سفر میکنم.
حال میتوانیم نسخههای مختلفی از همان جمله را باmask کردن کلمات تصادفی در جمله استخراج کنیم:
[mask] امروز سفر میکنم.
من [mask] سفر [mask].
[mask] ام [mask] سفر میکنم.
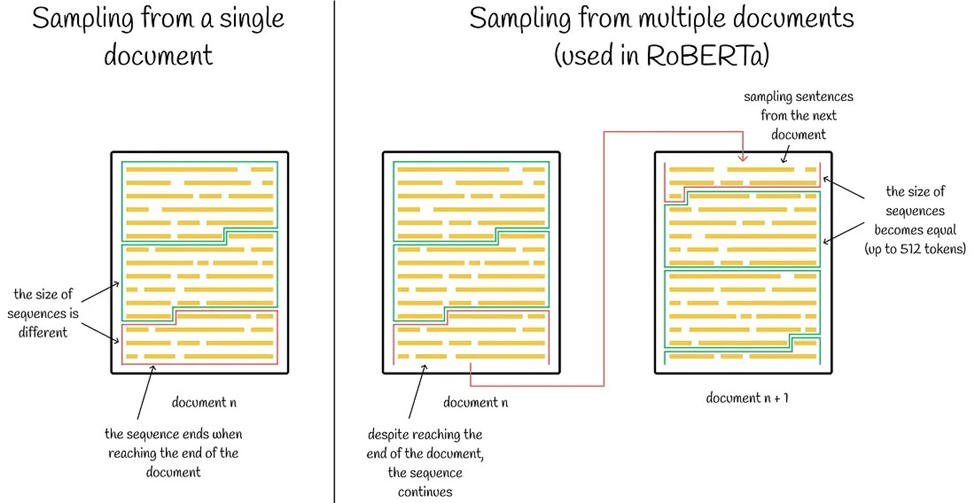
پیشبینی جمله بعدی
پیشبینی جمله بعدی (Next Sentence Prediction) یک وظیفه در مدلهای زبانی مانند BERT است که در آن مدل سعی میکند پیشبینی کند که آیا یک جمله به طور طبیعی پس از جمله دیگری میآید یا خیر.
این کار در طول پیشآموزش انجام میشود، جایی که مدل یاد میگیرد تا رابطه بین دو جمله را درک کند. ایده این است که با یادگیری اینکه آیا جملات مرتبط هستند یا نه، مدل میتواند در وظایفی که نیاز به درک محتوا و توالی ایدهها دارند، بهتر عمل کند. پژوهشگران مدل RoBERTa حین تحقیقات خود به نتایج زیر دست یافتند:
- وقتی loss مربوط به پیشبینی اشتباه جمله بعدی را حذف کردند، متوجه بهبود (جزئی) در عملکرد مدل شدند.
- مدل وقتی که تنها یک جمله به عنوان ورودی به آن داده میشد، عملکرد خوبی نداشت اما زمانی که توالیهایی از چندین جمله داشت، بهتر عمل میکرد. این نشان میدهد که مدلها وقتی میتوانند چگونگی ارتباط جملات در طول یک متن طولانیتر را ببینند، بهتر یاد میگیرند.
رمزگذاری جفت بایت
روبرتا همچنین از تکنیکی به نام رمزگذاری جفت بایت (Byte Pain Encoding) برای Tokenسازی (Tokenization) متن ورودی استفاده میکند. این کار شامل جایگزینی توالیهای پرتکرار کاراکترها با یک نشانه ترکیبی واحد است که اندازه واژگان را کاهش میدهد و به مدل امکان میدهد نمایشهای کارآمدتری را یاد بگیرد.
مقایسه برت و روبرتا
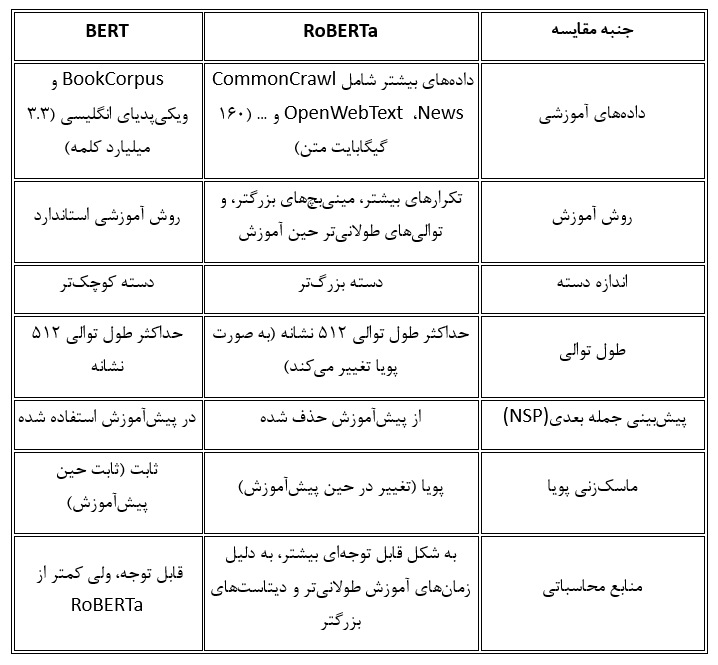
در مجموع، روبرتا نسخهای قدرتمندتر و کارآمدتر از BERT است که با استفاده از تکنیکهای پیشرفته و دیتاست بزرگتر آموزش دیده است. این امر آن را یک انتخاب خوب برای برنامههای کاربردی که نیاز به نمایشهای زبانی با کیفیت بالا دارند، مانند در ترجمه ماشینی یا خلاصهسازی میسازد.
ALBERT
ALBERT که مخفف A Lite Bert میباشد، با کاهش اندازه مدل از طریق به اشتراک گذاری پارامترها در لایههای مختلف، به کاهش نیازهای حافظه و افزایش سرعت آموزش کمک میکند. این مدل با ساختار بهینهسازی شده خود، به ویژه در محیطهایی که دسترسی به منابع محاسباتی محدود است، کارایی بالایی دارد. کاهش پیچیدگی محاسباتی در ALBERT نه تنها به کاهش هزینههای عملیاتی کمک میکند، بلکه امکان دسترسی به تکنولوژی پیشرفتهتر را برای توسعهدهندگان با بودجه محدود فراهم میآورد.
مدل ALBERT، که نسخهی بهبود یافته و سبکتری از BERT است، شامل سه نوآوری اصلی است:
تجزیه پارامترهای تعبیه (Factorized Parameter Embedding)
در این رویکرد، ماتریس بزرگ و سنگین تعبیه (Embedding) کلمات که در BERT مورد استفاده قرار میگیرد، به دو ماتریس کوچکتر تقسیم میشود که حافظه کمتری مصرف میکنند و آموزش آنها منابع کمتری نیاز دارد. به جای داشتن یک ماتریس بزرگ V x H که V اندازه واژگان و H بعد Embedding است، دو ماتریس V x E و E x H استفاده میشود که کل پارامترهای مورد نیاز را کاهش میدهد.
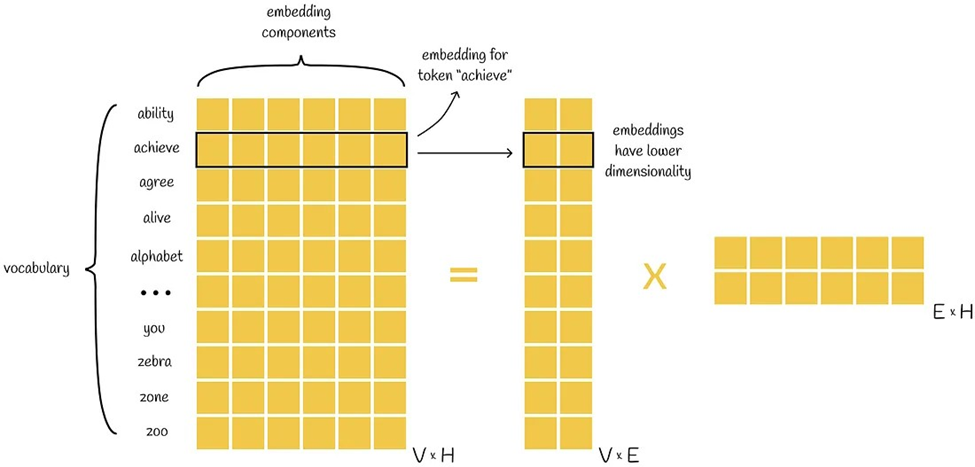
به اشتراک گذاری پارامترها در لایههای مختلف (Cross-layer Parameter Sharing)
در ALBERT، وزنها بین بلوکهای مختلف مدل به اشتراک گذاشته میشوند، به این معنی که تمام بلوکهای ترانسفورمر ساختار یکسانی دارند و همین امر موجب کاهش چشمگیر تعداد پارامترهای مدل میشود. این کار نه تنها حافظه مورد نیاز برای ذخیرهسازی وزنها را کاهش میدهد، بلکه باعث افزایش کارایی در زمان آموزش مدل هم میشود.
پیشبینی ترتیب جملات (Sentence Order Prediction)
در مدل BERT، دو هدف اصلی در زمان آموزش اولیه وجود داشت: مدلسازی زبان پنهان (Masked Language Modeling) و پیشبینی جمله بعدی (Next Sentence Prediction).
در ALBERT، به جای استفاده از NSP، مسئلهی جدیدی به نام پیشبینی ترتیب جملات (Sentence Order Prediction) معرفی میشود که هدف آن پیشبینی این است که آیا دو جمله پشت سرهم، صحیح قرار گرفتهاند یا معکوس. این تغییر با هدف بهبود توانایی مدل در فهم روابط منطقی میان جملات و بهبود عملکرد در کاربردهای پسین انجام شده است.
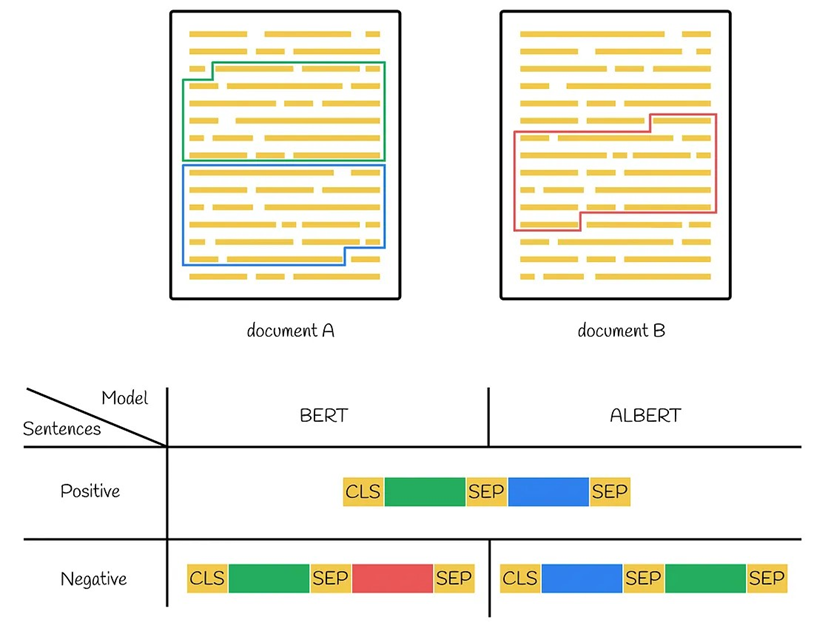
مقایسه ALBERT و BERT
شکل زیر مقایسهای بصری بین مدلهای BERT و ALBERT را ارائه میدهد و تنظیمات مختلف و تأثیرات متقابل آنها بر روی تعداد پارامترها، سرعت و عملکرد را نشان میدهد.
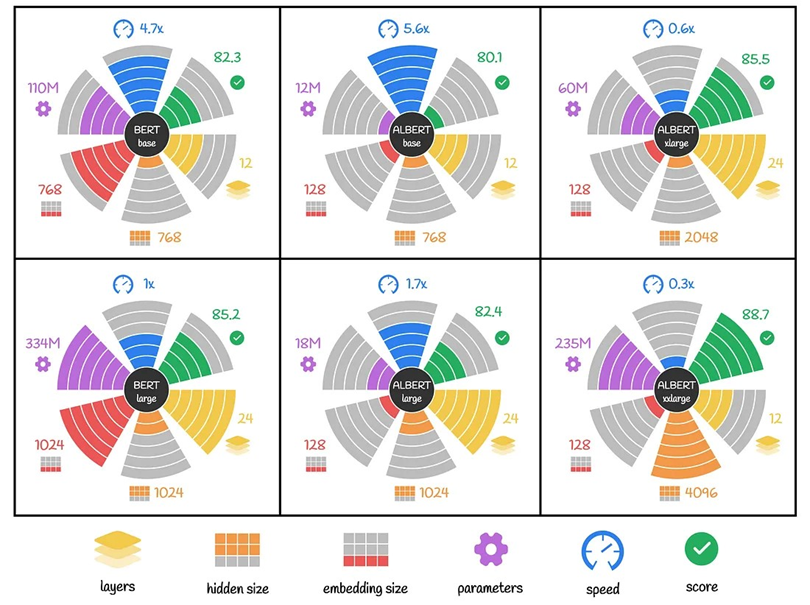
برای مثال در بالا سمت چپ، BERT base قرار دارد که دارای ۱۲ لایه و مجموعا ۱۱۰ میلیون پارامتر است. این مدل به عنوان یک معیار پایه با دقت ۸۲.۳ و سرعت ۴.۷ برابر سرعت BERT large استفاده میشود.
یا در سمت راست آن ALBERT base قرار دارد که با ۱۲ لایه و سایز Embedding کوچکتری به اندازه ۱۲۸ است که منجر به داشتن تنها ۱۲ میلیون پارامتر میشود. این مدل اگرچه دقتش کمتر (۸۰.۱) است، اما به طور قابل توجهی سرعت بیشتری دارد (۵.۶ سریعتر از BERT large).
DistilBERT
DistilBERT از فناوری تقطیر دانش (Knowledge Distillation) استفاده میکند تا یک مدل کوچکتر و کارآمدتر داشته باشد. این مدل با تمرکز بر کارآمدی و کاهش اندازه، امکان استفاده از قابلیتهای BERT را در دستگاههای با منابع کمتر مانند تلفنهای هوشمند و دستگاههای مبتنی بر IoT فراهم میکند. استفاده ازDistilBERT در برنامههای کاربردی موبایل و وب، تجربه کاربری بهتری را از طریق پاسخهای سریعتر و دقیقتر ارائه میدهد. این مدل ۴۰ درصد پارامتر کمتری نسبت به BERT base دارد،۶۰ درصد سریعتر اجرا میشود اما بیش از ۹۵ درصد از دقت BERT را حفظ میکند.

روش تقطیر دانش، به فرایند فشردهسازی و انتقال دانش از یک مدل بزرگ محاسباتی (مدل معلم) به یک مدل کوچکتر (مدل دانشآموز) اشاره دارد که دقت را حفظ میکند. قسمتهای اصلی این تکنیک عبارتند از:
مدل معلم
مدل بسیار بزرگ یا مجموعهای از مدلهای به طور جداگانه آموزش دیده که با استفاده از یک تنظیمکننده قوی مانند dropout میتوانند به عنوان مدل معلم در نظر گرفته شوند.
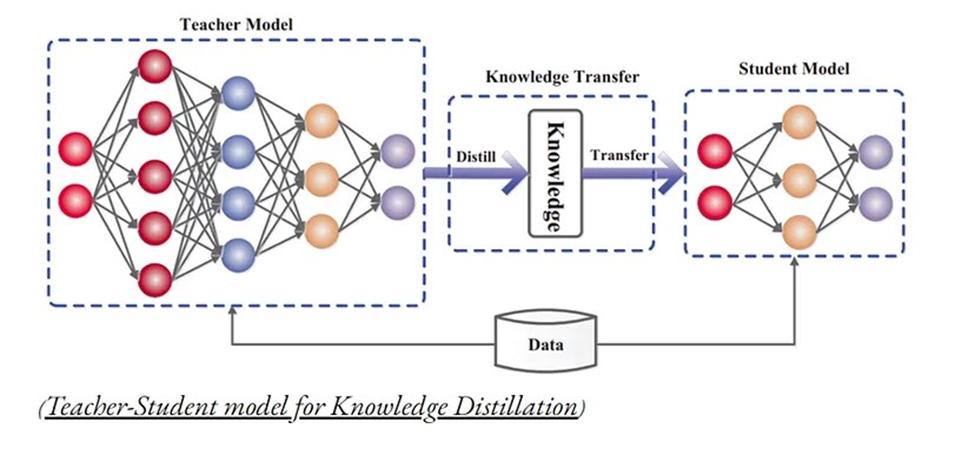
مدل دانشآموز
مدل کوچکی که به دانش تقطیر شده مدل معلم تکیه دارد. این مدل از نوع متفاوتی از آموزش به نام تقطیر برای انتقال دانش از مدل معلم به مدل دانشآموز استفاده میکند. مدل دانشآموز برای استقرار مناسبتر است زیرا سریعتر و کم هزینهتر است و در عین حال دقت نزدیکی با مدل معلم حفظ میکند.
تقطیر دانش چگونه انجام میشود؟
ابتدا یک شبکه معلم و یک شبکه دانشآموز تعریف میشود. شبکه معلم معمولاً میلیاردها/میلیونها پارامتر دارد و شبکه دانشآموز تعداد کمتری پارامتر خواهد داشت. سپس شبکه معلم را کامل آموزش میدهند تا مدل به همگرایی (Convergence) برسد.
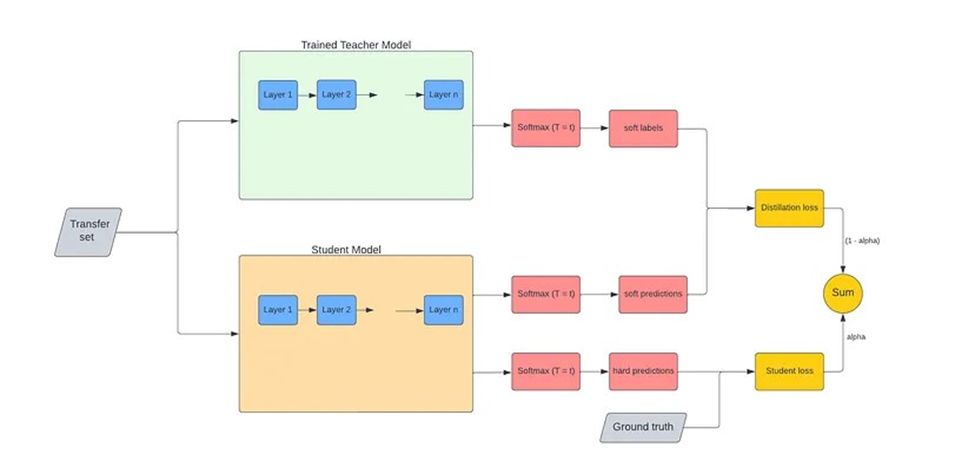
سپس با استفاده از دادههای آموزشی متفاوتی که در آموزش مدل معلم استفاده نشدهاند، عملیات تقطیر دانش را انجام میدهند که در آن گذر به جلو (forward pass) از طریق مدل معلم پیش آموزش دیده (Pretrained) و مدل دانشآموز اجرا شده و خطای آموزش بر اساس آن محاسبه میشود. این روند باعث میشود که مدل دانشآموز بتواند عملکردی مشابه مدل معلم را با استفاده از منابع کمتری از نظر محاسباتی به دست آورد.
ViLBERT
مدل ViLBERT معماری BERT را گسترش داده است تا بتواند به طور همزمان هم دادههای تصویری و هم دادههای متنی را پردازش کند، با ساختار دو جریانه. در ادامه نحوه کار این مدل توضیح داده میشود.

معماری دو جریانه
ViLBERT دارای دو جریان موازی است، یکی برای پردازش تصویری (جریان سبز) و دیگری برای پردازش زبانی (جریان بنفش). هر جریان از بلوکهای ترانسفورمر تشکیل شده است که مشابه بلوکهای استفاده شده در مدل BERT اصلی برای متن هستند.
لایههای ترانسفورمر توجه مشترک (Co-Attentional Transformer Layers)
ویژگی کلیدی ViLBERT، لایههای نوآورانهی ترانسفورمر توجه مشترک آن است. این لایهها به هر جریان (تصویری و زبانی) اجازه میدهند تا به طور مشترک از دادههای جریان دیگر استفاده کنند. برای مثال، در هنگام پردازش تصویر، اطلاعات مربوط به متن میتوانند برای بهبود توجه و فهم تصویر استفاده شوند و بالعکس.
تعامل بین جریانها
تعامل بین دو جریان از طریق لایههای توجه مشترک انجام میشود، که این امکان را فراهم میکند که ویژگیهایی از یک محیط تحت تأثیر ویژگیهای محیط دیگر قرار گیرند. این فرآیند به تعامل و تبادل اطلاعات بین بینایی و زبان کمک میکند.
FinBERT
مدل FinBERT که مخفف Financial Bert نسخهای سفارشیشده از مدل اصلی BERT است که به خصوص برای تجزیه و تحلیل احساسات در حوزه مالی استفاده میشود. به منظور بهبود کارایی BERT در تشخیص لحن و احساسات مربوط به متون مالی، این مدل ابتدا با استفاده از مجموعه دادههای مخصوص به حوزه مالی آموزش دیده است. این آموزش اولیه شامل تغذیه مدل با اصطلاحات تخصصی حوزه مالی بوده تا مدل بتواند با دقت بیشتری به تجزیه و تحلیل احساسات در این حوزه بپردازد. در نهایت، آموزشهای بیشتری برای تنظیم دقیقتر مدل بر روی وظیفه نهایی انجام شده است.
SpanBERT
SpanBERT، یک نسخه بهینهسازی شده از مدل BERT است که با هدف بهبود درک روابط بین و درون دامنههای متنی ایجاد شده است. در طی پیشآموزش، SpanBERT دو نوآوری دارد:
- اول، پوشاندن دنبالههای متوالی از متن (مانند جایگزین کردن چهار Token متوالی با [MASK]) و وظیفه مدل برای پیشبینی این اطلاعات گمشده.
- دوم، معرفی هدف مرز دامنه (Span Boundary Objective یا SBO) که مدل را وادار میکند از نمایشهای Tokenهای در مرز منطقه ماسک شده برای پیشبینی Tokenهای گمشده استفاده کند. همچنین، SpanBERT هدف پیشبینی جمله بعدی (NSP) را حذف کرده و تنها بر روی ورودیهای تکجملهای آموزش میبیند.
ERNIE
ERNIE از دانش ژرف زبانی و دانش عرفی برای فهم بهتر متون بهره میبرد. این مدل تواناییهای BERT را با ادغام دانش خارجی و ساختاری تقویت کرده است. ERNIE، با استفاده از مدلهای ساختاری و عرفی، به شناسایی مفاهیم پیچیده و ایجاد ارتباطات دقیق بین جملات و مفاهیم در متون بلند میپردازد، که این امکان را به توسعهدهندگان میدهد تا برنامههای کاربردی دقیقتر و حساستری را طراحی کنند.
ELECTRA
ELECTRA با هدف افزایش کارآیی آموزش BERT آموزش دیده است. در اینجا، ایده کلیدی استفاده از تشخیص Token جایگزین شده است. برای اجرای این مرحله، به دو مدل ترانسفورمر نیاز داریم: ۱) تولیدکننده و ۲) تشخیصدهنده.
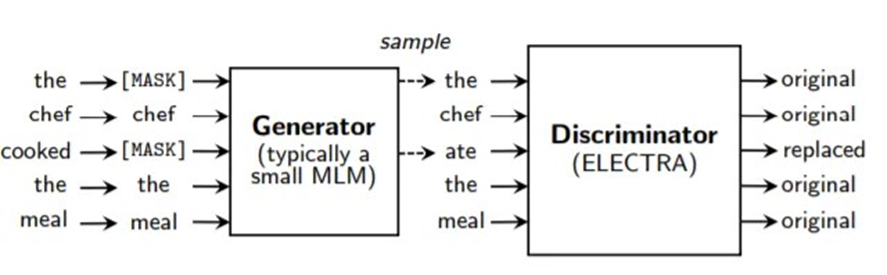
ابتدا، تعدادی از Token های ورودی را Mask میکنیم و تولیدکننده آنها را پیشبینی میکند. سپس، تشخیصدهنده (که نوآوری کلیدی در Electra است) باید تصمیم بگیرد که کدام ورودیها واقعی و کدامها مصنوعی هستند.
این روش به دلیل اینکه به جای محاسبه loss فقط بر روی Tokenهای Mask شده (همانند آنچه در BERT انجام میشود)، باید ضرر را بر روی تمام Tokenهای ورودی محاسبه کنیم، بسیار کارآمدتر است. این امر استفاده بهتری از منابع را فراهم میکند و امکان آموزش سریعتر مدل BERT را میدهد.
DeBERTa
DeBERTa که مخفف Decoding-enhanced BERT with disentangled attention است، یک پیشرفت در مدلهای BERT و RoBERTa است که از دو تکنیک نوآورانه استفاده میکند:
مکانیزم توجه مجزا
در این روش، هر کلمه با دو بردار نمایش داده میشود که یکی محتوای کلمه و دیگری موقعیت آن را رمزگذاری میکند. وزنهای توجه بین کلمات با استفاده از ماتریسهای مجزا برای محتویات و موقعیتهای نسبی آنها محاسبه میشود.
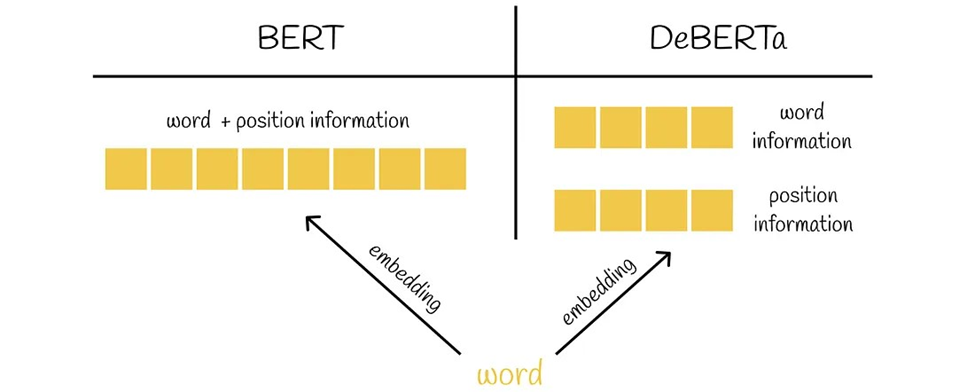
مکانیزم توجه مجزا در DeBERTa تنها به محتوا و موقعیت نسبی توجه میکند و اطلاعات موقعیت مطلق را نادیده میگیرد که ممکن است در پیشبینی نهایی تأثیرگذار باشد. به عنوان مثال، جملهای داده میشود که کلمات فروشگاه و مرکز خرید در آن Mask شدهاند. اگرچه این کلمات معنی مشابهی دارند، نقشهای متفاوتی در جمله ایفا میکنند. بدون دانستن موقعیت دقیق این کلمات، بازسازی دقیق جمله دشوار میشود. این موضوع نشان میدهد که چرا درک موقعیتهای مطلق برای مدل ضروری است، زیرا تأثیر مستقیمی بر توانایی مدل برای بازیابی صحیح اطلاعات دارد. DeBERTa در لایههای ترانسفورمر خود پس از هر لایه و قبل از اعمال لایه Softmax، موقعیت مطلق را در نظر میگیرد، که نشان داده شده است باعث بهبود عملکرد مدل میشود.
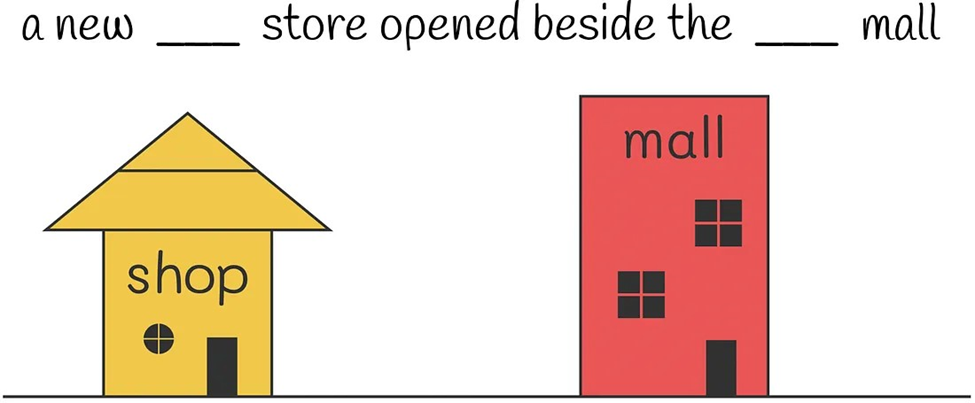
یک مثال برای درک بهتر
برای درک بهتر این مشکل، تصور کنید که میدانید در واقعیت ابتدا مرکز خرید و سپس فروشگاه افتتاح شده است. حال شما باید جملهای را که کلمات آن ماسک شدهاند، تکمیل کنید: «یک فروشگاه جدید در کنار یک مرکز خرید جدید افتتاح شد.» به عنوان یک فرد فارسیزبان، میدانید که هر چیزی که بعد از عبارت «افتتاح شد در کنار» قرار دارد، به لحاظ دستوری نشاندهنده این است که اول افتتاح شده است. در عین حال، هر چیزی که قبل از این کلمات قرار دارد، بعدتر افتتاح شده است. بنابراین، به راحتی و با اطمینان کلمات فروشگاه و مرکز خرید را به ترتیب مینویسید. چرا این کار برای شما آسان بود؟ زیرا به عنوان یک انسان، شما به طور طبیعی موقعیتهای مطلق کلمات ماسکشده را در نظر میگیرید.
حال تصور کنید که هیچ اطلاعی درباره موقعیتهای مطلق کلمات ماسکشده نداشتید. در این صورت، شما نمیتوانستید از اشارههای داده شده درباره ترتیب دستوری کلمات در اطراف ساختار «افتتاح شد در کنار» استفاده کنید. در نتیجه، با وجود دانستن معانی کلمات و زمینه محلی آنها، باز هم قادر به دادن پاسخ صحیح نخواهید بود. این موقعیت مشابه با موقعیتی است که مدل در آن قرار دارد، زمانی که به موقعیتهای مطلق دسترسی ندارد.
تقویت دهندههای رمزگشایی
تقویت دهندههای رمزگشایی در مدل DeBERTa تکنیک دیگری است که به بهبود توانایی مدل در درک زمینه و پیچیدگیهای متنی کمک میکند. در این رویکرد، اطلاعاتی که از بردارهای محتوا و موقعیت به دست میآیند، به صورت دینامیکی و با توجه به نیازهای مخصوص به هر سناریو ترکیب میشوند. این امر امکان میدهد که مدل بتواند تعاملات پیچیده بین کلمات را درک کند و به تبع آن، تفسیر دقیقتر و عمیقتری از متن ارائه دهد.
کاربرد DeBERTa
این مدل در رتبهبندی مسائل پیچیدهتر زبانی مانند استدلال علی به خوبی عمل میکند. DeBERTa، با استفاده از تکنیکهای پیشرفته در تفکیک و تحلیل عناصر زبانی، به تقویت قابلیتهای فهم ماشین کمک میکند و در نتیجه، امکان میدهد تا برنامههای کاربردی نوین در حوزههایی مانند فهم متون قانونی و تحلیل متون علمی ارتقاء یابند.
TinyBERT
TinyBERT یک نسخه بسیار کوچکتر و کارآمدتر از BERT است که با هدف اجرا در دستگاههای با منابع محدود طراحی شده است. با وجود اندازه کوچکتر، این مدل همچنان توانایی حفظ بخش عظیمی از عملکرد مدل اصلی BERT را دارد.
TinyBERT، با بهینهسازی برای دستگاههای کمقدرت مانند تلفنهای همراه و تبلتها، امکان دسترسی به تکنولوژی پیشرفتهی پردازش زبان طبیعی را به جامعهی وسیعتری میدهد. این مدل به دلیل کاربردی بودن در محیطهای با محدودیت منابع، به افزایش دسترسی به فناوریهای نوین کمک شایانی میکند و در عین حال، کیفیت پردازش و فهم زبانی را در سطح بالا حفظ میکند.
جمعبندی
بر اساس سند ارسالی، BERT به عنوان یک نقطه عطف در پردازش زبان طبیعی تأثیر گذار بوده است. این مدل با بهرهگیری از تکنیکهای نوین و معماری Transformer، دقت مدلهای متنی را به طور چشمگیری افزایش داده است. نوآوریهای اصلی BERT شامل پردازش دوطرفه متن و توانایی درک مفاهیم پیچیدهتر است که در وظایف مختلف نظیر ترجمه، خلاصهسازی، و تشخیص نامها بسیار موفق بوده است. BERT پایهای برای توسعه مدلهای بهینهسازی شده مانند RoBERTa و ALBERT بوده که هر کدام بهبودهای خاصی را در زمینههای متفاوت ارائه دادهاند.

سوالات متداول
BERT چیست؟
BERT (نمایشهای دوطرفه رمزگذار از ترانسفورمرها) یک مدل پردازش زبان طبیعی است که توسط گوگل ایجاد شده و قابلیت درک زمینهای و پیچیدگیهای زبانی را دارد.
چرا BERT برای NLP مهم است؟
BERT به دلیل استفاده از معماری Transformer و پردازش دوسویه متن، قابلیت درک مفاهیم پیچیدهتر را فراهم میآورد و بهبود قابل توجهی در وظایف مختلف NLP ایجاد کرده است.
RoBERTa چگونه از BERT متفاوت است؟
RoBERTa، یک نسخه بهبودیافته از BERT است که با حذف پیشبینی جمله بعدی و استفاده از دادههای آموزشی بیشتر و طول آموزش طولانیتر، دقت بیشتری در درک متون دارد.
ALBERT نسبت به BERT چه مزایایی دارد؟
ALBERT با کاهش تعداد پارامترها از طریق به اشتراک گذاری پارامترها و تجزیه پارامترهای تعبیه، حافظه کمتری مصرف میکند و سرعت آموزش را افزایش میدهد.
چه نوع کاربردهایی برای مدلهای مبتنی بر BERT وجود دارد؟
مدلهای مبتنی بر BERT در ترجمه ماشینی، تشخیص نامها، خلاصهسازی متون، تحلیل احساسات، و بسیاری از وظایف دیگر NLP کاربرد دارند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: