
علم داده یا دیتا ساینس (Data Science) حوزه مطالعاتی است که با بهکارگیری ابزارها و تکنیکهای مدرن حجم گستردهای از دادهها را برای یافتن الگوهای پنهان در دادهها، استخراج اطلاعات معنادار از آنها و استفاده از آنها در تصمیمگیریهای تجاری به کار میبرد. Data Science از الگوریتمهای پیچیدهی یادگیری ماشین (Machine Learning) برای ساخت مدلهای پیشبینی استفاده میکند. این دادههای مورداستفاده برای تجزیهوتحلیل میتوانند از منابع مختلف باشند و فرمهای مختلفی نیز داشته باشند.
امروزه با توجه به تولید انبوه دادهها، علم داده یا دیتا ساینس (Data Science) بخشی مهم و اساسی در هر صنعت محسوب میشود. درواقع علم داده یکی از بحثبرانگیزترین موضوعات این روزها در صنایع است.
محبوبیت آن طی سالها افزایش یافته است و شرکتها برای رشد تجارت خود و افزایش رضایت مشتری، شروع به اجرای تکنیکهای علم داده کردهاند. در این مقاله با علم داده و اهمیت آن در صنعت و زندگی روزمره بیشتر آشنا خواهیم شد؛ میبینیم که یک محقق داده چه وظایفی دارد و درنهایت چند کاربرد علم داده یا دیتا ساینس را بررسی میکنیم.
- 1. علم داده یا دیتا ساینس (Data Science) چیست؟
- 2. محقق علم داده یا دیتا ساینس (Data Scientist) چه وظایفی دارد؟
- 3. چرا علم داده (Data Science) اهمیت دارد؟
- 4. نقشه راه یادگیری علم داده
- 5. برخی مفاهیم آماری مورد نیاز برای علم داده
- 6. علم داده با پایتون
- 7. کاربرد دیتا ساینس (Data Science) چیست؟
- 8. کاربردهای علمداده در حوزههای مختلف
- 9. دیتا ساینس برای شرکتها
- 10. یادگیری علم داده یا دیتا ساینس در کافهتدریس

علم داده یا دیتا ساینس (Data Science) چیست؟
علم داده یا دیتا ساینس (Data Science) رشتهای است که از روشها، فرایندها، الگوریتمها و سیستمهای علمی برای استخراج دانش و بینش از دادههای ساختاریافته و غیرساختاریافته استفاده میکند؛ سپس این دانش و بینش عملی از دادهها را در طیف وسیعی از دامنههای کاربردی به کار میبرد.
علم داده مفهومی متشکل از آمار (Statistics)، تجزیهوتحلیل دادهها (Data Analysis)، انفورماتیک (Informatics) و روشهای مربوط به آن بهمنظور درک و تجزیهوتحلیل پدیدههای واقعی با استفاده از داده است. این علم از تکنیکهای مختلف درزمینهی ریاضیات، آمار، علوم کامپیوتر و علوم اطلاعات استفاده میکند.
تا اینجا مفهوم دیتا ساینس را متوجه شدیم، اما ممکن است این سؤال در ذهنمان مطرح شود که یک محقق دیتا ساینس دقیقاً چه کاری انجام میدهد؟ در ادامه با وظایف یک محقق داده آشنا میشوید.
محقق علم داده یا دیتا ساینس (Data Scientist) چه وظایفی دارد؟
محقق داده دادهها را تجزیه وتحلیل میکند تا بینش معناداری را از آنها استخراج کند؛ بهعبارت دیگر، یک محقق داده ازطریق مراحلی، به سازمانها کمک میکند تا مشکلات خود را حل کنند. این مراحل میتواند این موارد را شامل باشد:
- برای درک مشکل سؤالات درستی را مطرح میکند؛
- دادهها را از چندین منبع جمعآوری میکند؛
- دادههای خام را پردازش و به فرم مناسب برای تجزیهوتحلیل تبدیل میکند.
- دادهها را به سیستم تحلیلی، مانند یک الگوریتم یادگیری ماشین(Machine Learning) یا یک مدل آماری میکند.
- نتایج و بینشها را برای بهاشتراکگذاشتن با ذینفعان آماده میکند.
برای آشنایی با یادگیری ماشین (Machine Learning) این مطلب را مطالعه کنید:
یادگیری ماشین (Machine Learning) چیست و چگونه کار میکند؟

چرا علم داده (Data Science) اهمیت دارد؟
در دنیای کنونی تولید و استفاده از اطلاعات موجود در دادهها یک فعالیت بسیار مهم و حیاتی در حوزهی تجارت محسوب میشود. علم داده شرکتها را قادر میکند تا دادههای عظیم را از چندین منبع بهطور کارآمد تحلیل کنند و از بینشهای ارزشمندی که از تحلیل آنها به دست میآورند برای تصمیمگیریهای هوشمند مبتنی بر آن دادهها استفاده کنند.
دیتا ساینس (Data Science) شرکتها را قادر میکند تا عملکرد خود را برای تسهیل تصمیمگیریهای آینده بسنجند. آنها میتوانند با استفاده از تحلیل دادهها برای تعامل بهتر مشتریان، افزایش عملکرد شرکت و افزایش سودآوری تصمیمهای هوشمندانهتری را اتخاذ کنند. علم داده بهطور گستردهای در حوزههای مختلف صنعت ازجمله بازاریابی، مراقبتهای درمانی، امور مالی، بانکداری، سیاست و موارد دیگر استفاده میشود.
همانطور که اشاره شد علم داده در حوزههای مختلف صنعت کاربرد بسزایی دارد. بیایید با هم به برخی از کاربردهای آن نگاهی بیندازیم تا بیشتر این موضوع را درک کنیم.
نقشه راه یادگیری علم داده
اگر تصمیم به دنبال کردن حرفه ای در حوزه علم داده دارید، بیایید در این بخش به نقشه راه یادگیری برای تبدیل شدن به یک دانشمند داده بپردازیم. یک دانشمند داده مفاهیم مهندسی نرم افزار، آمار و دنیای کسب و کار را گرد هم می آورد تا داده ها را برای استخراج بینش های ارزشمند بررسی کند. ما در این بخش چند گام را فهرست کردهایم که به شما کمک میکند مهارتهای مورد نیاز برای تبدیل شدن به یک دانشمند داده را بیاموزید و بر این حوزه تسلط پیدا کنید. این مراحل بر اساس پیچیدگی های موجود، منحنی یادگیری خاص خود را دارند. بنابراین، یادگیری و تسلط بر هر مرحله زمان های مختلفی را می طلبد. بهتر است این موارد را با توجه به شرایط خود پیش ببرید. ممکن است لازم باشد برای تسلط بر برخی از مراحل چند مرحله را به شکل همزمان پیش ببرید و این البته راه بهتری است و زودتر پیشرفت خواهید کرد.
پایتون را یاد بگیرید!
شغل هر دانشمند داده نیاز به تخصص در یکی از زبانهای برنامه نویسی برای انجام وظایف مختلف علم داده دارد. رایجترین زبانهایی که دانشمندان داده استفاده میکنند Python و R هستند. اگر مبتدی هستید، یادگیری Python برای Data Science نسبت به هر زبان برنامه نویسی دیگری به شدت توصیه میشود. یکی از اصلیترین دلایلی که Python به طور گسترده مورد استفاده قرار میگیرد و محبوبترین در جامعه Data Science است، سهولت استفاده و نحو (سینتکس) ساده آن است که یادگیری و تطبیق آن را برای افراد بدون پیشزمینه مهندسی آسان میکند. همچنین، میتوانید برای زبان پایتون تعداد زیادی کتابخانه منبع باز به همراه اسناد آنلاین برای اجرای وظایف مختلف علم داده مانند یادگیری ماشین، یادگیری عمیق، تجسم داده و غیره پیدا کنید.
اکنون که میدانید چرا باید پایتون را به عنوان اولین گام برای تبدیل شدن به یک دانشمند داده یاد بگیرید، بیایید به موضوعات برنامهنویسی خاصی بپردازیم که باید در نقشه راه یادگیری خود بگنجانید.
- ساختارهای داده (انواع داده های مختلف، لیست ها، تاپل ها، دیکشنری، آرایه، مجموعهها، ماتریس ها، بردارها و غیره)
- تعریف و نوشتن توابع تعریف شده توسط کاربر
- انواع حلقهها و دستورات شرطی مانند If، else، و غیره.
- الگوریتم های جستجو و مرتب سازی
- مفاهیم SQL – Join، Aggregations، Merge و غیره.

کتابخانه های پایتون را برای علم داده بیاموزید!
یکی از دلایل محبوبیت پایتون در جامعه علم داده این است که کتابخانههای متعددی برای اجرای هر نوع تسک مرتبط با علم داده فراهم میکند. تعدادی از رایج ترین کتابخانههای مورد استفاده توسط دانشمندان داده عبارتند از:
NumPy
NumPy کتابخانهای است که روشها و توابع مختلفی را برای مدیریت و پردازش آرایههای بزرگ، ماتریسها و جبر خطی ارائه میدهد و مخفف عبارت Numerical Python است. این کتابخانه برداری از جبر خطی مختلف و توابع ریاضی مورد نیاز برای کار بر روی ماتریسها و آرایههای بزرگ را فراهم میکند و بردارسازی توابع را قادر میسازد تا بدون نیاز به حلقه زدن و عمل بر روی هر آیتم، عملیات را بر روی تمام عناصر یک بردار اعمال کنند، و در نتیجه سرعت اجرا و عملکرد افزایش مییابد.
Pandas
Pandas محبوبترین کتابخانه پایتون در میان دانشمندان داده است. این کتابخانه بسیاری از توابع داخلی مفید را برای انجام دستکاری و تجزیه و تحلیل داده ها بر روی مقادیر زیادی از دادههای ساخت یافته ارائه میدهد. Pandas یک ابزار عالی برای بحث در مورد دادههاست و از دو ساختار داده – Series و Dataframe پشتیبانی میکند.
سری (Series) یک آرایه تک بعدی است و قادر به نگهداری دادهها از هر نوع (اعداد صحیح، string، float، object و غیره) است. یک Dataframe در Pandas یک ساختار داده دو بعدی ناهمگن است، یعنی دادهها به شکل جدولی در ردیفها و ستونها مانند صفحه گسترده اکسل یا جدول SQL تراز میشوند. Pandas DataFrame قادر به داشتن ستونهایی با انواع دادههای متعدد است.
Matplotlib
تجسم دادهها یکی از مراحل کلیدی در اجرای هر راه حل Data Science است. Matplotlib یک کتابخانه مفید است که روشها و عملکردهایی را برای تجسم دادهها به شکل نمودارهای مختلف ارائه میکند.
Seaborn
این یکی دیگر از کتابخانههای تجسم پایتون است که بسیاری از توابع داخلی را برای روشهای تجسم داده مختلف مانند هیستوگرام، نمودار میلهای، نقشه حرارتی، نمودار چگالی و غیره فراهم میکند. استفاده از آن در مقایسه با matplotlib بسیار سادهتر است و ارقام زیباییشناختی جذابی را ارائه میدهد.
SciPy
شما به عنوان یک دانشمند داده باید تحلیلهای آماری زیادی انجام دهید، مانند انجام EDA بر روی دادهها با استفاده از روشهای آماری مانند میانگین، انحراف استاندارد، z-score، آزمون p-value و غیره. SciPy انواع مختلفی از روشها و توابع برای اجرای مفاهیم آماری و ریاضی مورد نیاز در علم داده را در اختیار شما قرار میدهد.
Scikit-Learn
این یک کتابخانه Python یادگیری ماشین است که پیادهسازی ساده، بهینه و سازگار را برای طیف وسیعی از تکنیکهای یادگیری ماشین ارائه میکند.
برای مطالعه بیشتر دربارهی کتابخانههای مختلف پایتون برای علمداده روی لینک زیر کلیک کنید:
با کتابخانههای پرکاربرد پایتون آشنا شوید!
درباره آمار و ریاضیات کاربردی بیاموزید!
آمار و ریاضیات جزء لاینفک علم داده و هر الگوریتم یادگیری ماشین (Machine Learning) هستند. برای یک دانشمند داده، داشتن درک صحیح از مفاهیم مختلف آماری و ریاضی درگیر در علم داده ضروری است. البته این را در نظر داشته باشید که لازم نیست یک ریاضیدان باشید تا علم داده یا دیتا ساینس را یاد بگیرید، تنها آشنایی با برخی از مفاهیم اصلی برای درک بهتر نحوه عملکرد الگوریتمهای این حوزه کفایت میکند.
درباره یادگیری ماشین و عمیق بیاموزید!
هنگامی که درک عمیقتری از تمام مفاهیم ذکرشده در بالا به دست آوردید، میتوانید به یادگیری و درک الگوریتمهای یادگیری ماشین ادامه دهید.
از مفاهیمی که لازم است با آنها آشنا شوید:
یادگیری نظارت شده (Supervised Learning): این الگوریتمها الگوی دادهها را بر اساس متغیر هدفی که در اختیارشان قرار میگیرد، یاد میگیرند که شامل تکنیکهای رگرسیون (Regression) و طبقهبندی (Classification) است. شما باید الگوریتمهای محبوب ML مانند رگرسیون خطی، رگرسیون لجستیک، درخت تصمیم، جنگل تصادفی، XGBoost، Naive Bayes، KNN و غیره را در نقشه راه یادگیری خود داشته باشید.
یادگیری بدون نظارت (Unsupervised Learning): این الگوریتمها زمانی استفاده میشوند که هیچ متغیر هدفی در دسترس نباشد. لازم است مواردی مثل K-Means Clustering، PCA، Association Mining و غیره را در این دسته مطالعه کنید.
یادگیری عمیق (Deep Learning): زیرشاخهای در حوزه یادگیری ماشین است که دادهها را با استفاده از شبکههای عصبی مدل میکند. شبکههای عصبی چیزی جز مدلهای ریاضی که از مغز انسان تقلید میکنند، نیستند. یادگیری عمیق دانشمندان داده را قادر به پردازش و مدلسازی دادههای پیچیده مانند تصاویر، متون و غیره کرده است.
برای مطالعه بیشتر درباره یادگیری ماشین و یادگیری عمیق روی لینک زیر کلیک کنید:
ماشین لرنینگ چیست و چگونه کار میکند؟
برخی مفاهیم آماری مورد نیاز برای علم داده
علم داده یا دیتا ساینس به نوعی وابسته به آمار است. به عبارت دیگر، دیتاساینس بر پایهی آمار شکل گرفته است. بنابراین یادگیری برخی از مفاهیم آماری مرتبط برای شخصی که قصد دارد وارد این حوزه شود، ضروری است. در این بخش به معرفی برخی از معروفترین مفاهیم آماری برای علمداده میپردازیم.
متغیرهای تصادفی (Random Variables) مفهوم متغیرهای تصادفی سنگ بنای بسیاری از مفاهیم آماری را تشکیل می دهد. هضم تعریف رسمی ریاضی آن ممکن است سخت باشد، اما به بیان ساده، یک متغیر تصادفی راهی برای ترسیم نتایج فرآیندهای تصادفی، مانند انداختن سکه یا انداختن تاس، به اعداد است. به عنوان مثال، ما میتوانیم فرآیند تصادفی پرتاب یک سکه را با متغیر تصادفی X تعریف کنیم که در صورت شیر بودن، مقدار 1 و اگر نتیجه خط باشد، مقدار 0 را میگیرد.
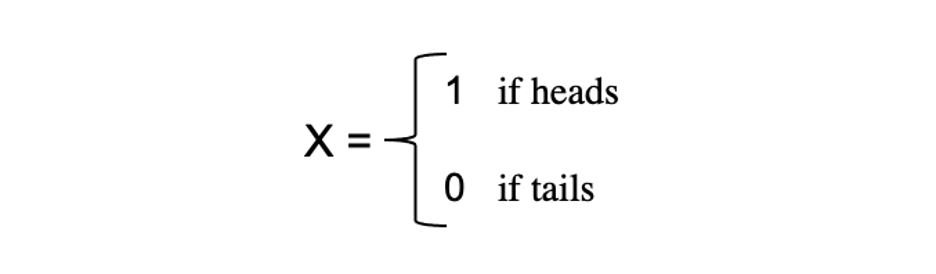
در این مثال، ما یک فرآیند تصادفی از پرتاب یک سکه داریم که در آن این آزمایش میتواند دو نتیجه ممکن را ایجاد کند: {0،1}. این مجموعه از تمام نتایج ممکن، فضای نمونه آزمایش نامیده میشود. هر بار که فرآیند تصادفی تکرار میشود، به عنوان یک رویداد شناخته میشود. در این مثال، پرتاب یک سکه و خط آوردن به عنوان یک نتیجه از یک رویداد است. شانس یا احتمال وقوع این رویداد با یک نتیجه خاص را احتمال آن رویداد میگویند. احتمال یک رویداد احتمال این است که یک متغیر تصادفی مقدار خاصی از x را بگیرد که با P(x) قابل توصیف است. در مثال پرتاب سکه، احتمال شیر یا خط یکسان است، یعنی ۰.۵ یا ۵۰%. بنابراین داریم:
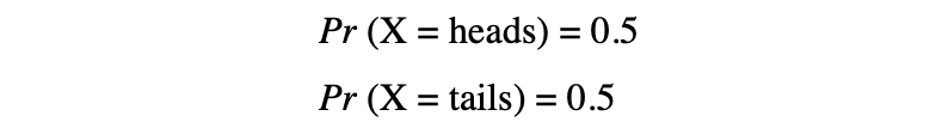
میانگین، واریانس، انحراف معیار
برای درک مفاهیم میانگین(Mean) ، واریانس و بسیاری از موضوعات آماری دیگر، یادگیری مفاهیم جامعه و نمونه مهم است. جامعه مجموعه ای از همه مشاهدات (افراد، اشیاء، رویدادها یا رویهها) است و معمولاً بسیار بزرگ و متنوع است، در حالی که یک نمونه زیرمجموعه ای از مشاهدات از جمعیت است که در حالت ایده آل یک بازنمایی واقعی از جمعیت است.
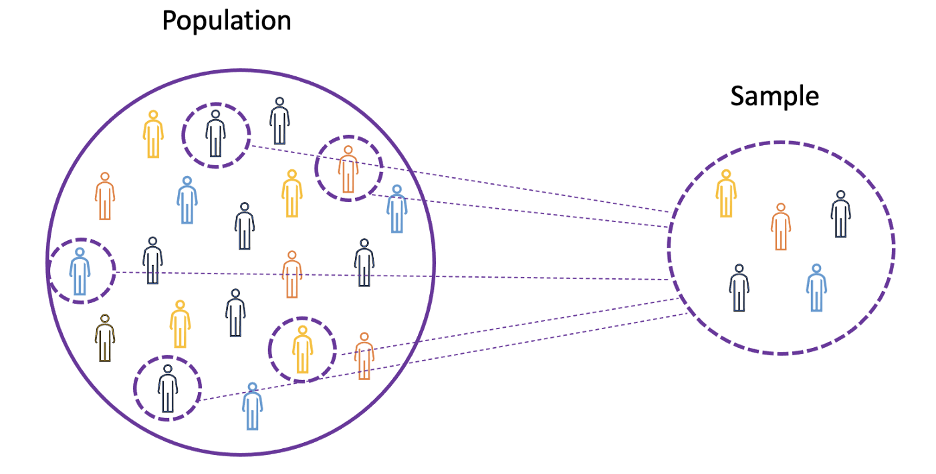
با توجه به اینکه آزمایش با کل جمعیت یا غیرممکن است یا بسیار پرهزینه است، محققان یا تحلیلگران از نمونهها به جای کل جمعیت در آزمایشهای خود استفاده میکنند. برای اطمینان از اینکه نتایج آزمایشی قابل اعتماد است و برای کل جمعیت قابل استفاده است، نمونه باید نماینده واقعی جامعه باشد. یعنی نمونه باید بی طرفانه باشد. برای این منظور میتوان از تکنیکهای نمونهگیری آماری مانند نمونهگیری تصادفی(Random Sampling) ، نمونهگیری سیستماتیک(Systematic Sampling) ، نمونهگیری خوشهای(Clustered Sampling) ، نمونهگیری وزنی(Weighted Sampling) و نمونهگیری طبقهای(Stratified Sampling) استفاده کرد.
میانگین (Mean)
میانگین، همچنین به عنوان میانگین شناخته میشود، یک مقدار مرکزی از یک مجموعه محدود از اعداد است. فرض کنید یک متغیر تصادفی X در داده دارای مقادیر زیر است:
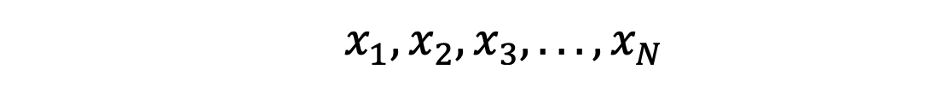
که در آن N تعداد مشاهدات یا نقاط داده در مجموعه نمونه یا به عبارت دیگر فرکانس داده است. میانگین نمونه که با μ، نمایش داده میشود، اغلب برای تقریب میانگین جامعه استفاده میشود، میتواند به صورت زیر بیان شود:
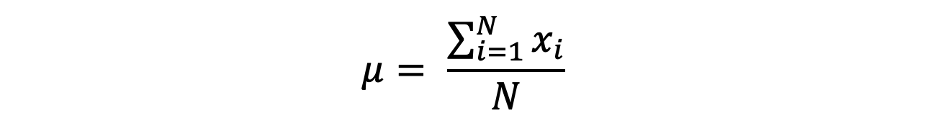
واریانس (Variance)
واریانس اندازهگیری فاصله نقاط داده از مقدار متوسط است و برابر است با مجموع مجذور تفاوت بین مقادیر داده و میانگین (Mean). علاوه بر این، واریانس جمعیت را میتوان به صورت زیر بیان کرد:
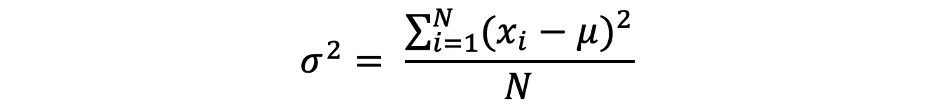
انحراف معیار
انحراف معیار به سادگی جذر واریانس است و میزان تفاوت دادهها از میانگین آن را اندازهگیری میکند. انحراف معیار تعریف شده توسط سیگما را میتوان به صورت زیر بیان کرد:
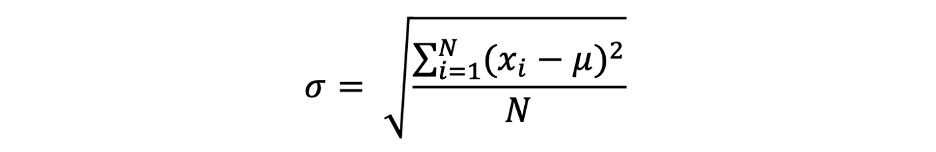
کوواریانس (Covariance)
کوواریانس معیاری برای نشان دادن تغییر مشترک دو متغیر تصادفی است و رابطه بین این دو متغیر را توصیف میکند و به عنوان مقدار مورد انتظار حاصل ضرب انحراف دو متغیر تصادفی از میانگین آنها تعریف میشود. کوواریانس بین دو متغیر تصادفی X و Z را میتوان با عبارت زیر توصیف کرد که در آن E(X) و E(Z) به ترتیب میانگین X و Z را نشان میدهند.
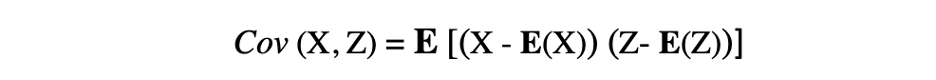
کوواریانس میتواند مقادیر منفی یا مثبت و همچنین مقدار 0 را داشته باشد. مقدار مثبت کوواریانس نشان میدهد که دو متغیر تصادفی تمایل به تغییر در یک جهت دارند، در حالی که یک مقدار منفی نشان میدهد که این متغیرها در جهت مخالف تغییر میکنند. در نهایت، مقدار 0 به این معنی است که آنها با هم متفاوت نیستند.
همبستگی(Correlation)
همبستگی نیز معیاری برای رابطه است وهم قدرت و هم جهت رابطه خطی بین دو متغیر را اندازه گیری میکند. اگر همبستگی تشخیص داده شود به این معنی است که بین مقادیر دو متغیر هدف رابطه یا الگویی وجود دارد. همبستگی بین دو متغیر تصادفی X و Z برابر است با کوواریانس بین این دو متغیر تقسیم بر حاصل ضرب انحراف معیار این متغیرها که با عبارت زیر قابل توصیف است.
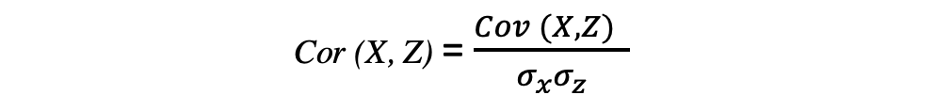
مقادیر ضرایب همبستگی بین -1 و 1 است. به خاطر داشته باشید که همبستگی یک متغیر با خودش همیشه 1 است، یعنی Cor(X, X) = 1. نکته دیگری که باید در هنگام تفسیر همبستگی در نظر داشت این است که آن را با علیت اشتباه نگیرید، با توجه به اینکه همبستگی علیت نیست. حتی اگر بین دو متغیر همبستگی وجود داشته باشد، نمیتوانید نتیجه بگیرید که یک متغیر باعث تغییر در متغیر دیگر میشود. این رابطه میتواند تصادفی باشد یا عامل سوم ممکن است باعث تغییر هر دو متغیر شود.
توابع توزیع احتمال(Probability distribution Functions)
تابعی که تمام مقادیر ممکن، فضای نمونه و احتمالات مربوطه را که یک متغیر تصادفی میتواند در محدوده معینی که بین حداقل و حداکثر مقادیر ممکن محدود شده است توصیف کند، تابع توزیع احتمال (pdf) یا چگالی احتمال نامیده میشود.
هر تابع توزیع احتمال باید دو معیار زیر را داشته باشد:
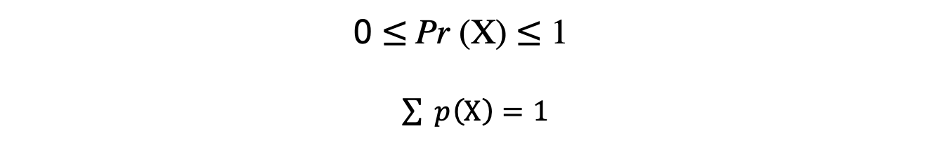
که در آن معیار اول بیان میکند که همه احتمالات باید اعدادی در محدوده [0,1] باشند و معیار دوم بیان میکند که مجموع همه احتمالات ممکن باید برابر با 1 باشد.
توابع احتمال معمولاً به دو دسته گسسته و پیوسته طبقهبندی میشوند. تابع توزیع گسسته فرآیند تصادفی را با فضای نمونه قابل شمارش توصیف میکند، مانند نمونهای از پرتاب یک سکه که تنها دو نتیجه ممکن دارد. تابع توزیع پیوسته فرآیند تصادفی را با فضای نمونه پیوسته توصیف میکند. نمونههایی از توابع توزیع گسسته عبارتند از: برنولی(Bernoulli) ، دو جملهای(Binomial) ، پواسون(Poisson) ، یکنواخت گسسته(Discrete Uniform) . نمونههایی از توابع توزیع پیوسته عبارتند از: نرمال (Normal)، یکنواخت پیوسته (Continuous Uniform)، کوشی (Cauchy).
رگرسیون خطی
رگرسیون خطی (Linear Regression) روشی آماری برای یافتن رابطهی میان متغیرهای مستقل (Dependent Variables) و وابسته (Independent Variables) است. این روش در یادگیری ماشین با ناظر (Supervised Machine Learning) بسیار کاربرد دارد. البته این تعریف درواقع تعریفی کتابی است؛ اگر بخواهیم سادهتر بگوییم، میتوانیم رگرسیون را اینگونه تعریف کنیم: یافتن بهترین خط مناسب یا معادلهی رگرسیون با استفاده از رابطهی میان متغیرها که میتواند برای پیشبینی استفاده شود.
برای مطالعه بیشتر دربارهی رگرسیون خطی روی لینک زیر کلیک کنید:
علم داده با پایتون
یکی از مهمترین مهارتهایی که در حوزه علمداده یا دیتاساینس، برنامهنویسی است. به عنوان شخصی که قصد دارد با دادهها کار کند، لازم است حداقل با یک زبانبرنامهنویسی آشنایی داشته باشید و بتوانید با استفاده از آن زبان، به پاکسازی، پردازش و تجسم داده بپردازید. درواقع میتوان گفت علم داده بدون داشتن مهارت کدنویسی معنا پیدا نمیکند. حال در بین زبانهایی که معمولا در این حوزه توسط دانشمندان داده و افراد فعال در حوزه دیتا استفاده میشود می توان به زبان برنامهنویسی پایتون (Python)، R و SQL اشاره کرد. از بین این سه زبان برنامهنویسی محبوبترین آنها زبان پایتون است. دلایل زیادی هم برای این موضوع وجود دارد.
در این بخش به برخی از دلایل محبوبیت پایتون در حوزه دیتاساینس میپردازیم:
۱. Python زبان نسبتاً سادهایست و یادگیری آن آسان است!
یکی از مزیتهای اصلی پایتون این است که بصری و ساده است و این موضوع بسیار مهم است زیرا آن را برای هر کسی که میخواهد به جای گم شدن در بین هزاران خط کد، به نتیجهی دلخواه برسد، دوستداشتنی میکند.
Python همچنین بسیار خوانا و آسان برای یادگیری است، به این معنی که در مقایسه با سایر زبانهای برنامه نویسی مانند R، Java، یا ++C، به زحمت کمتری برای شروع برنامهنویسی نیاز دارد. پایتون بیار به زبان انسان ( انگلیسی) نزدیک است و این موضوع به راحتی درک و یادگیری آن کمک میکند. شاید بتوان گفت این سادگی و راحت بودن یادگیری یکی از برترین مزیتهای این زبان محسوب میشود. به همین دلیل است که اکثر دورههای علمداده با زبان پایتون پیش میروند.
۲. ابزارها و کتابخانههای زیادی برای علمداده دارد!
یکی از کارهای اولیه دانشمندان داده، تجزیه و تحلیل دادهها است و در دنیای واقعی، دادهها به اشکال مختلف در میآیند. آنها اغلب خام هستند و برای اجرای انواع تجزیه و تحلیل مناسب نیستند. از این رو انواع پردازشهای مختلف داده بر روی آن اعمال میشود. پاکسازی و تبدیل دادهها به شکلی که بتوان آنها را برای ایجاد و استخراج بینش مناسب، تجزیه و تحلیل و مدلسازی کنید، فرآیندی دشوار است.
زبان برنامهنویسی پایتون در اینجا به دانشمندان داده کمک میکند. این زبان با بسیاری از کتابخانههای پایتون منبع باز ارائه میشود که میتواند تمام این وظایف را برای دانشمندان داده انجام دهد. این کتابخانهها به طور مرتب به روز میشوند مانند NumPy، Pandas، MatPlotLib، و غیره، و تنها کاری که باید انجام دهید این است که از آنها در اسکریپتهای پایتون خود استفاده کنید. بنابراین با زبان پایتون شما بهترین ابزارها را هم برای تجزیه و تحلیل دادهها و هم برای تجسم دادهها دارید.
با داشتن این کتابخانهها و ابزارها برای اینکه بتوانید دادههای خود را تمیز کنید، برخی فرمولهای ریاضی را اعمال کنید، معادلهای آماری را اجرا کنید که از آن راضی هستید، تنها چیزی که باید یاد بگیرید این است که چگونه یک ماژول پایتون را وارد کنید. این درواقع تنها کاریست که لازم است یاد بگیرید. این کتابخانهها تا حد زیادی کار را برایتان راحت میکنند و نیازی نیست که زحتم زیادی را متحمل شوید. اگر کنجکاو هستید که از کدام ماژول پایتون برای چه شغلی استفاده کنید، فقط آن را در گوگل جستجو کنید، پاسخهای خود را پیدا خواهید کرد. أصلا لازم نیست به خاطر بسپارید که از کدام کتابخانههای پایتون استفاده کنید.
در واقع، پس از کار با چند اسکریپت، به طور خودکار با کتابخانههای ضروری Python برای دانشمندان داده مانند NumPy که مخفف Numerical Python است، Pandas که حیاتیترین ابزار برای پاکسازی و تجزیه و تحلیل دادهها است و MatPlotLib برای تجسم دادهها، ایجاد نمودارهای مختلف و ایجاد بینش از دادهها آشنا میشوید.
شما همچنین TensorFlow، Sci-Kit، PyTorch را دارید که برخی از قابلیتهای علمی و یادگیری ماشین (Machine Learning) را ارائه میدهند و بهطور مداوم توسط افراد با استعداد در سراسر جهان بهبود داده شده و به روز میشوند. به عنوان مثال، فیسبوک (Facebook) قابلیت یادگیری ماشین زیادی را در PyTorch اضافه کرده است.
به عنوان یک دانشمند داده و علاقهمند به یادگیری ماشین، لازم نیست نگران بهروزرسانی کتابخانهها، افزودن قابلیتهای جدید و غیره باشید، زیرا شخص دیگری این کار را برای شما انجام میدهد. شما فقط باید از کتابخانه برای انجام کار خود استفاده کنید.
برای آشنایی با کتابخانههای پرکاربرد پایتون برای علمداده روی لینک زیر کلیک کنید:
مقاله کتابخانههای پرکاربرد پایتون
۳. Jupyter Notebook
دلیل دیگری که چرا دانشمندان داده زبان برنامهنویسی پایتون را دوست دارند، نوت بوک Jupyter است که به شما امکان میدهد با استفاده از یک مرورگر وب، کدنویسی کنید و با سایر دانشمندان داده همکاری کنید.
از آنجایی که کار بر روی خط فرمان (command line)برای همه آسان نیست، آنها یک رابط وب قدرتمند برای پایتون ایجاد کردند و نام آن را Jupyter Notebook گذاشتند.
Jupyter Notebook ابزاری فوقالعاده قدرتمند برای توسعه و ارائه پروژههای علم داده (Data Science) است.
به دلیل قابلیت های چشمگیرش، نوت بوک Jupyter در بین دانشمندان داده بسیار محبوب است و یکی از ابزارهای ضروری برای آنهاست. اکثر افراد فعال در حوزه دیتا با Jupyter Notebook کار میکنند.
۴. حمایت از سمت انجمن پایتون
دلیل دیگری که در پس محبوبیت پایتون در بین افرادی که علم داده را یاد میگیرند، وجود دارد انجمن فعال آن است. از آنجایی که پایتون یک انجمن فعال دارد و بسیاری از افراد در حال انجام پروژههای مختلف علم داده با استفاده از پایتون هستند، شما در حال حاضر به یک انجمن فعال دسترسی دارید که در صورت گیر افتادن و برخوردن به مشکل خاص میتوانید از آن استفاده کنید. از آنجایی که بیشتر چیزها به شکل منبع باز (open source) در انجمن پایتون به اشتراک گذاشته میشوند، سود بسیار زیادی خواهید برد. بسیاری از سازمانهای بزرگ مانند گوگل (Google) و فیسبوک (Facebook) به ایجاد و بهبود TensorFlow و PyTorch که برخی از محبوبترین کتابخانههای پایتون برای علم داده و یادگیری ماشین هستند، کمک کردهاند.
کاربرد دیتا ساینس (Data Science) چیست؟
- در صنعت مراقبتهای پزشکی پزشکان از علم داده یا دیتا ساینس برای تحلیل دادههای بهدستآمده از ردیابهایی که بیماران همراه دارند استفاده میکنند تا از سلامت بیماران خود اطمینان حاصل کنند؛ بهاین ترتیب، آنان میتوانند در مواقع لزوم تصمیمهای درست و بهموقعی را بگیرند؛ علاوهبراین علم داده یا دیتا ساینس (Data Science) میتواند به مدیران بیمارستانها این امکان را بدهد که زمان انتظار بیمار را کاهش دهند. همچنین شرکتهای مراقبتهای پزشکی با استفاده از علم داده ابزارهایی را برای شناسایی و درمان بیماریها میسازند.
- شرکتهای خردهفروشی از علم داده برای بهبود تجربه مشتری و همچنین حفظ مشتریان خود استفاده میکنند؛ برای مثال، وبسایت آمازون براساس علایق مشتریان به آنان اجناس مختلف را توصیه میکند.
- علم داده بهطور گستردهای در بانکها و مؤسسات مالی برای کشف کلاهبرداری و همچنین مشاوره مالی شخصی استفاده میشود.
- شرکتهای ساختمانی با ردیابی فعالیتها، ازجمله متوسط زمان برای انجامدادن کارهای مختلف، هزینههای مواد مصرفی و موارد دیگر، از علم داده برای تصمیمگیری بهتر استفاده میکنند.
- علم داده این امکان را میدهد تا با استفاده از محتوای شبکههای اجتماعی الگوهای محتوایی مورداستفادهی کاربران را بیابیم. این الگوها کمک میکنند تا برای هر کاربر محتوای اختصاصی تولید کنیم؛ همچنین محتوای مرتبط را به کاربر پیشنهاد کنیم.
- بازیهای ویدئویی و رایانهای اکنون با کمک دیتا ساینس ساخته میشوند و همین امر تجربهی بازی را به سطح بالاتری رسانده است.
کاربردهای علمداده در حوزههای مختلف
علم داده در بازاریابی دیجیتال
دیجیتال مارکتینگ شامل تمام تلاشهای آنلاین با هدف بازاریابی یک برند است که میتواند یک شخص، کسب و کار، محصولات، خدمات و غیره باشد. اکنون بخشهای مختلفی از بازاریابی دیجیتال وجود دارد که شامل مدیریت رسانههای اجتماعی، سئو، بازاریابی ایمیلی، بازاریابی محتوا و غیره هستند.
اکنون میتوان از علم داده در بازاریابی دیجیتال برای بهبود روش انجام آن استفاده کرد. روشهایی که علم داده در بازاریابی دیجیتال مفید است، به شرح زیر است:
- بازاریابی دیجیتال از بینشهای علم داده برای انتخاب کانال دیجیتال مناسب برای هدف استفاده میکند. این موضوع به دستیابی به مخاطب مناسب کمک میکند.
- همچنین، علم داده به شما کمک میکند تا بدانید مخاطب هدف شما چه میخواهد. با این کار میتوانید تاکتیکهای بازاریابی ایجاد کنید که به شما کمک کند آن خواستهها را برآورده کنید.
- علم داده به بازاریابان دیجیتال بینشی در مورد فرم محتوای مناسب میدهد. همچنین باعث میشود سازمانها زمان مناسب برای ارسال پست، نحوه افزایش تعامل مشتریان و غیره را بدانند.
علم داده در ورزش
آمار و پیش بینیهای بسیاری در صنعت ورزش وجود دارد. در حال حاضر قبل از مسابقه ورزشی افراد زیادی با در نظر گرفتن عوامل و اطلاعات مختلف سعی در پیشبینی نتیجه بازی دارند و اغلب اوقات، این پیشبینیها ممکن است درست باشند. با این حال، این موضوع بستگی به دقت اطلاعات مورد استفاده در پیش بینی دارد. این یک حوزه حیاتی در ورزش است که علم داده در آن کاربرد دارد.
- در ورزش، بینش علم داده به پیشبینی نتیجه بازی کمک میکند که در آن دادههای جمعآوری شده در مورد نقاط ضعف و قوت بازیکنان، عملکرد گذشته و غیره نقش دارند.
- علاوه بر این، ذینفعان از علم داده برای اتخاذ تصمیمات انتخاب بازیکن استفاده میکنند. این کار برای تعیین این است که آیا یک بازیکن برای یک تیم دارایی بزرگی خواهد بود یا خیر. آنها از علم داده برای جمعآوری و تجزیه و تحلیل دادهها در مورد عملکرد گذشته بازیکن، سلامت فعلی و آینده، سازگاری فردی با تیم و غیره استفاده میکنند.
- مربیان همچنین از علم داده برای به دست آوردن اطلاعات در مورد نحوه آموزش بازیکنان برای دستیابی به عملکرد مطلوب استفاده میکنند.
علم داده در آموزش
آموزش و پرورش بستر هر جامعه و فرآیند انتقال دانش به دیگران است. حوزه آموزش از علم داده به روشهای زیر استفاده میکند:
- کارشناسان آموزش از علم داده برای بهبود یادگیری استفاده میکنند و به هر دانش آموز کمک میکنند تا به روش منحصر به فرد خود بیاموزند. درواقع به نوعی یادگیری را شخصیسازی میکنند.
- همچنین، علم داده به ارزیابی روشهای تدریس معلمان برای کمک به بهبود، نقاط قوت و ضعف این روشهای آموزشی کمک میکند.
- علاوه بر این، آموزش افراد را به دانشی برای حل مشکلات در دنیای واقعی مجهز میکند و از آنجایی که در زمانهای مختلف ترندهای مختلفی در جهان مطرح میشوند، به روز رسانی منظم برنامه درسی اهمیت دارد. برای این کار، کارشناسان از بینشهای علم داده برای پیشبینی روندهای آینده و تقویت برنامه درسی آموزشی برای تناسب با آن ترندها استفاده میکنند.
علم داده در پزشکی
بهداشت و درمان یکی از بخشهای مهم جامعه است و البته حوزهای است که در آن کاربرد علم داده برای حل مشکلات زندگی واقعی بسیار زیاد است. در مراقبتهای بهداشتی، علم داده بینشهای عملی را ارائه میدهد که برای تصمیم گیریهای مرتبط با سلامت استفاده میشود و به پیشگیری از بیماری و مرگ کمک میکند.
- کارشناسان از بینشهای علم داده برای نظارت و پیشگیری از مشکلات سلامتی استفاده میکنند. این کار از طریق جمعآوری دادهها در مورد الگوهای خواب، سطح گلوکز خون، فعالیت مغز و غیره است. پس از آن، متخصصان، دادهها را تجزیه و تحلیل میکنند تا تغییرات را بررسی کنند و اختلالات یا مشکلات سلامتی احتمالی را تشخیص دهند.
- همچنین، علم داده به بهبود دقت تشخیص کمک میکند. علم داده به ساخت الگوریتمهای یادگیری کمک میکند که بتوانند دادههای تصویربرداری را بخوانند و آنها را تجزیه و تحلیل کنند. پس از آن، آنها نتایج داده شده را با یک پایگاه داده موجود از گزارشهای بالینی مقایسه میکنند.
- درمان بیماریهای کشندهای مانند سرطان، ابولا، کووید-۱۹ و غیره را میتوان با استفاده از بینشهای علم داده پیدا کرد.
علم داده در حمل و نقل و تدارکات
حمل و نقل و تدارکات مربوط به جابجایی افراد، حیوانات، کالاها و غیره از یک مکان به مکان دیگر است و بخش حمل و نقل و لجستیک برای علم داده ارزش زیادی قائل است. در زمان های گذشته، صنعت حمل و نقل و لجستیک برای انجام کارها صرفاً به فرآیندهای دستی متکی بود و این منجر به اتلاف، تاخیر در بهرهوری و نارضایتی مشتری میشد. در حال حاضر، با علم داده می توان این مشکلات را برطرف کرد.
- علم داده بر اساس روندهای اخیر بازار و پیشبینیها خواستههای مردم را انجام میدهد.
- علاوه بر این، صنعت حمل و نقل و لجستیک از بینشهای علم داده برای تخمین و پیشبینی زمان ورود و خروج استفاده میکند.
- کارشناسان از علم داده برای تعیین کوتاهترین مسیر ممکن برای رسیدن به یک مکان استفاده میکنند که از اتلاف وقت و انرژی جلوگیری میکند.
- کارشناسان از بینشهای علم داده در انجام ارزیابی ریسک و پیشبینی اختلالات در صنعت حمل و نقل استفاده میکنند. این کار همچنین برای اطلاع دادن به ذینفعان مربوطه از هرگونه مشکلی که در تسهیلات حمل و نقل آنها با آن مواجه است استفاده میشود.
علم داده در کشاورزی
کشاورزی یک حوزه بسیار مهم در جهان امروز است. از ابتدای پیدایش جهان به این شکل بوده و خواهد بود. کشاورزی شامل تولید انواع مختلف محصولات زراعی و پرورش حیوانات برای مصارف انسانی و صنعتی است. اکنون حوزه کشاورزی از علم داده به روش های زیر استفاده میکند:
کارشناسان از علم داده برای مبارزه با کمبود مواد غذایی استفاده میکنند. این کار از طریق تجزیه و تحلیل دادههای مربوطه است که بینش عملی در مورد چگونگی مبارزه با کمبود مواد غذایی در جهان ارائه میدهد.
- علم داده همچنین بینشی در مورد انواع و کمیت آفات و بیماریهای زراعی که بر محصولات آنها تأثیر میگذارند به کشاورزان میدهد.
- علم داده همچنین در بخش کشاورزی برای کمک به کشاورزان برای مقابله با تغییرات آب و هوایی مفید است. این کار به آنها کمک میکند تا چرخه کشاورزی خود را مطابق با پیشبینیهای انجام شده با روشهای مختلف علم داده برنامهریزی کنند.
- همچنین میتوان از علم داده برای پیشبینی بازده استفاده کرد. این کار به کشاورزان کمک میکند تا بدانند قبل از زمان برداشت چه انتظاراتی باید داشته باشند.
علم داده در حوزه مالی
یکی از رشتههای سطح بالا در جهان صنعت مالی است. صنعتی که تمام جنبههای زندگی ما را در بر میگیرد. امور مالی شامل بانکداری، سرمایه گذاری، مدیریت ریسک، مالیات و غیره است. علمداده در این حوزه هم نقش مهمی ایفا میکند.
- کارشناسان در صنعت مالی از علم داده برای انجام تجزیه و تحلیل ریسک استفاده میکنند. این کار به آنها کمک میکند تا سطح ریسک مرتبط با تصمیم گیریهای مالی را بدانند.
- همچنین، علم داده و ابزارهای تحلیلی آن به جلوگیری و کشف تقلب در بخش مالی کمک میکند.
- کارشناسان مالی میتوانند با استفاده از بینشهای علم داده، خدمات مالی شخصیسازی شده را برای مشتریان ایجاد کنند.
علم داده در محیط زیست
علم داده نقش مهمی در حفظ محیط زیست دارد. درواقع علم داده زمین (Earth Data Science) یک رشته در حوزه علم داده است. در این رشته کارشناسان از تکنیکهای علم داده برای مطالعه فرآیندهای زمین و مقابله با مشکلات زیست محیطی استفاده میکنند.
- علم داده به پیش بینی دقیق تغییرات آب و هوا، رویدادهای شدید آب و هوایی و غیره کمک میکند.
- علم داده همچنین وقوع بلایای طبیعی و حوادث در محیط را پیش بینی میکند.
علم داده در تولید و ساخت
تولید و ساخت شامل تبدیل مواد خام به محصولات یا کالاهای نهایی است که از نیروی انسانی، ماشین آلات و سایر تجهیزات برای بدست آوردن محصولات تصفیه شده از مواد خام استفاده میکند. برخی از کاربردهای علمداده در این حوزه عبارتند از:
- در صنعت تولید، ما از بینشهای تجزیه و تحلیل داده برای نظارت بر ماشینها و تجهیزات به شکل بلادرنگ استفاده میکنیم. این کار برای جلوگیری از خرابی ماشین آلات و کشف دلایل احتمالی خرابی آنها در آینده است.
- علم داده همچنین میتواند بینشی در مورد بهترین و مقرون به صرفهترین تجهیزاتی که تولیدکنندگان میتوانند خریداری کنند، ارائه دهد که به بازگشت سرمایه کمک میکند.
- همچنین، علم داده به پیشبینی تغییرات بازار کمک میکند که به تولیدکنندگان این امکان را میدهد تا تصمیمات تولیدی مهمی را متناسب با نیازهای بازار اتخاذ کنند.
دیتا ساینس برای شرکتها
در این مطلب علم داده را معرفی کردیم و دیدیم که کاربردهای آن بسیار گسترده است. دادهها عنصر اصلی موردنیاز شرکتها در دهههای آینده هستند. با گنجاندن تکنیکهای علم داده در تجارت، شرکتها اکنون میتوانند رشد آینده را پیشبینی کنند و در صورت وجود تهدیدهای احتمالی آنها را بررسی و برای مقابله آماده شوند.
برای آشنایی بیشتر با علم داده این مطلب را مطالعه کنید:
ورود به علم داده یا دیتاساینس از کجا شروع میشود؟
یادگیری علم داده یا دیتا ساینس در کافهتدریس
کافهتدریس کلاسهای آنلاین جامع آموزش علم داده را برگزار میکند. این کلاسها بهصورت کاملاً تعاملی و مبتنی بر کار روی پروژههای واقعی علم داده برگزار میشود و به شما امکان میدهد در هر نقطهی جغرافیایی به بهروزترین آموزش علم داده و دیتا ساینس دسترسی داشته باشید.
برای آشنایی با دیتا ساینس و مشاوره رایگان برای شروع یادگیری و مسیر شغلی روی این لینک کنید:
این خیلی معلومات مفید بود بر مه در کل ویب سایت این معلومات حیلی کامل بود ممنون از خدمت شما
خوشحالیم که براتون مفید بوده.
هفت خوان پلاس
علم داده (Data Science) شرکتها را قادر میکند تا عملکرد خود را برای تسهیل تصمیمگیریهای آینده بسنجند. آنها میتوانند با استفاده از تحلیل دادهها برای تعامل بهتر مشتریان، افزایش عملکرد شرکت و افزایش سودآوری تصمیمهای هوشمندانهتری را اتخاذ کنند.
پاسخ سوال:
به سازمانها کمک میکند تا مشکلات خود را حل کنند. این مراحل میتواند این موارد را شامل باشد:
برای درک مشکل سؤالات درستی را مطرح میکند؛
دادهها را از چندین منبع جمعآوری میکند؛
دادههای خام را پردازش و به فرم مناسب برای تجزیهوتحلیل تبدیل میکند.
دادهها را به سیستم تحلیلی، مانند یک الگوریتم یادگیری ماشین(Machine Learning) یا یک مدل آماری میکند.
نتایج و بینشها را برای بهاشتراکگذاشتن با ذینفعان آماده میکند.
استاد شکرزاد در رابطه با در آمدهای دیتاساینتیست ها در یک وبینار صحبت کردند ممنون میشم لینکش رو ارسال کنید
یکی از وبینارهایی که ایشون در این مورد توضیحاتی رو ارائه کردن، وبینار ۲: پیادهسازی ماشینلرنینگ در علوم مختلفه.
لینک وبینار:. http://ctdrs.ir/dsw002
افرادی که دوره علم داده مقدماتی و پیشرفته رو با کلاس پیش میرن و دوره رو به اتمام می رسونند این امکان رو دارن که جذب بازار کار بشن ؟
بله قطعا. اگه محتوای دوره ها رو دیده باشین، متوجه میشین که تمام مباحث کاربردی و به روز هستن. علاوه بر این تو دورهها پروژه های عملی هم به شکل گروهی انجام میدین و درواقع هدف دوره اینه که در نهایت یه رزومه خوب بتونین برای خودتون بسازین و آمادهی ورود به بازارکار بشین.
برای تبدیل شده به یک آنالیزو داده نیازی به یادگیری آکادمیک نیست ؟
لزوما خیر. اگه علاقه داشته باشید، میتونین شروع به یادگیری کنین و در نهایت وارد بازارکار بشین.
من خیلی به علم داده علاقه دارم اما نمی تونم از کجا شروع کنم ؟
بهترین کار شروع یادگیری با یه دورهست. چون علم داده هنوز کمی مبهمه و میتونه وظایف و مهارتهای زیادی رو شامل بشه، شرکت در یه دوره خوب میتونه شروع مناسبی باشه.
سلام من تا ارشته کارشناسیم حسابداری بوده و هیچ دیدی از برنامه نویسی ندارم به نظرتون می تونم علم داده رو یاد بگیرم ؟
بله، بیشتر از اینکه رشته تحصیلی ملاک باشه، علاقه شما برای یادگیری ملاکه.
ممنون میشم اگر مقاله ای در باب یادگیری ماشین هم به همین شیوایی بیان تهیه کنید
تو این مقاله دربارهی یادگیری ماشین صحبت کردیم: http://ctdrs.ir/ds0002
ممنون از سایت و کانال خوبتون. وبینار ۴ برنامه ریزی عملی برای شروع یادگیری علم داده خیلی خوب بود، ممنون میشم استاد شکرزاد step های یادگیری رو با جزییات بیشتری در وبینارهای آینده توضیح بدن. برای من که در این مسیر یک ساله قرار گرفتم وبینارهاتون خیلی کمکم میکنه. ممنون
سپاس از توجه شما
در وبینار ۳ هم مفصل درباره ی این step ها و تبدیل شدن به یک data player صحبت شده، پیشنهاد میکنیم حتما این وبینار رو ببینین.
به ویدیوی وبینار اقای رضا شکرزاد چطوری میتونم دسترسی داشته باشم؟
کافیه وارد لینک زیر بشین و تو بخش ویدئوهای آموزشی به ویدئوی وبینارهای قبلی دسترسی پیدا کنین.
https://cafetadris.com/datascience
سلام خسته نباشید، کلاس علم داده شما برای اپلای میتونه کمکم کنه؟ من دانشجوی سال آخر کامپیوتر هستم لیسانس
سلام، وقتتون بخیر
بله قطعاً دوره های علم داده کافهتدریس میتونه برای اپلای بهتون کمک کنه، داشتن دانش علم داده و یادگیری ماشین بخصوص در رشته شما امتیاز خیلی خوبی محسوب میشه. در دوره های ما هم به شکل تئوریکال و هم به شکل عملی (Practical) علم داده و مفاهیم یادگیری ماشین و یادگیری عمیق رو یاد میگیرین.
از رشته مهندسی نرم افزار هم در این رشته بطور حرفهای کار میکنن؟ یا بهتره از همون رشتههای ریاضی کاربردی و آمار وارد شد؟
نمیخوام فعالیت دیگر رشتهها رو کلا رد کنم قاعدتا حتما میتونن کار کنن. میخوام بدونم اونها موفقتر میشن و آیا جنس کار بیشتر به اون موضوعات مرتبط هست یا خیر؟
بنظرتون مهندسهای کامپیوتر در دیگر حوزههای مرتبط با خودشون که علاقه دارن وارد بشن بیشتر موفق نمیشن؟
اتفاقاً رشته مهندسی کامپیوتر اصلیترین رشته برای ورود به یادگیری ماشین و علم دادهست. یعنی بیشتر افرادی که دارن تو این زمینه کار میکنن رشته تحصیلیشون مهندسی نرمافزار بوده. بنابراین یادگیری ماشین و علم داده کاملاً با رشتهشون مرتبطه و بحث علاقهم که کاملاً جداست. قطعاً هرکاری با علاقه پیش بره، موفقیت همراهشه.
سلام وقت بخیر
من میخواستم بدونم در حال حاضر تو ایران دانشگاهی برای ارشد رشته دیتاساینس برگزار می کنه؟
یا اگه نمیکنه نزدیک ترین رشته کدومه؟
با تشکر
با سلام،
در حال حاضر این دانشگاه ها رشته Data Science رو در مقطع کارشناسی ارشد دارن:
رشته ریاضی کاربردی گرایش علوم داده:
دانشگاه شهید باهنر کرمان، دانشگاه شهید بهشتی تهران، دانشگاه صنعتی اصفهان، دانشگاه صنعتی خواجه نصیرالدین طوسی تهران، دانشگاه فردوسی مشهد، دانشگاه گیلان رشت، دانشگاه شاهد تهران، دانشگاه تربیت مدرس تهران و دانشگاه خلیج فارس بوشهر
رشته علوم کامپیوتر گرایش علوم داده:
دانشگاه صنعتی اصفهان، دانشگاه غیر انتفاعی خاتم تهران و دانشگاه غیر انتفاعی علم و فرهنگ تهران
رشته آمار گرایش علم داده ها:
دانشگاه بیرجند، دانشگاه تربیت مدرس تهران، دانشگاه زنجان، دانشگاه شهید بهشتی تهران، دانشگاه علامه طبابایی تهران، دانشگاه یزد
ممنون از پاسخ شما
سلام وقت بخیر
بله در دانشگاههای مانند مدرس، خواجه نصیر و شهیدبهشتی ارائه میشه و زیرشاخه رشته آمار هست.