
بیز ساده (Naïve Bayes) یک الگوریتم طبقهبندی ساده اما مؤثر و متداول یادگیری ماشین (Machine Learning) است که در دستهی یادگیری با ناظر (Supervised Learning) جای میگیرد. بیز ساده الگوریتمی احتمالی است که براساس نظریهی بیز برای طبقهبندی (Classification) استفاده میشود.
- 1. مقدمه
- 2. یادگیری ماشین چیست؟
- 3. طبقهبندی یا Classification چیست؟
- 4. بیز ساده (Naïve Bayes) چیست؟
- 5. درک بیز ساده با یک مثال
- 6. انواع بیز ساده
- 7. مقایسه نقاط قوت و ضعف انواع بیز ساده
- 8. مقایسه ویژگیهای انواع بیز ساده
- 9. قسمتی از جزوه کلاس برای آموزش بیز ساده
- 10. بیز ساده در پایتون
- 11. خلاصه مطالب درباره الگوریتم بیز ساده (Naive Bayes)

مقدمه
فرض کنید در حال قدمزدن در یک پارک هستید و جسمی قرمز در مقابل خود مشاهده میکنید. این جسم قرمز میتواند چوبدستی، خرگوش یا توپ باشد. شما قطعاً فرض میکنید که آن جسم یک توپ است. چرا؟
بیایید تصور کنیم که در حال ساخت ماشینی هستیم که وظیفهاش طبقهبندی یک جسم میان سه گروه چوبدستی، توپ و خرگوش است. در ابتدا احتمالاً به این فکر میکنیم که ماشینی که میسازیم بتواند ویژگیهای جسم را شناسایی کند و سپس آن را با یکی از گروههایی که میخواهیم در آنها طبقهبندی کنیم مطابقت دهد.
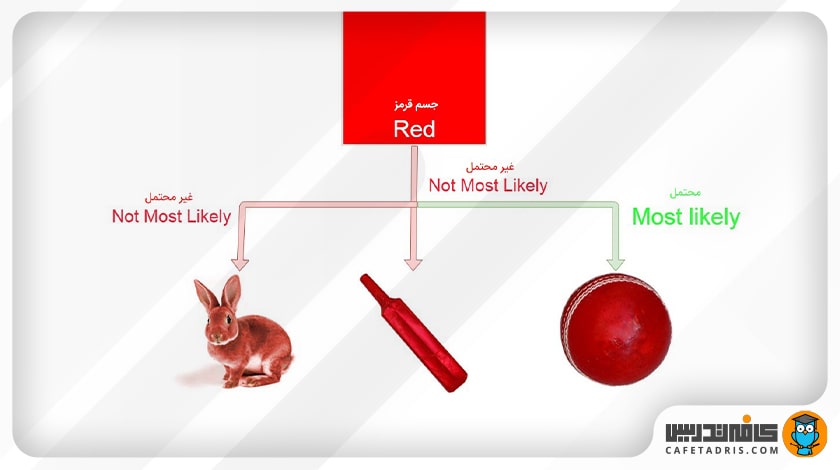
بهطوری که مثلاً اگر جسم دایرهای شکل باشد، پیشبینی کند که یک توپ است یا اگر آن جسم یک موجود زنده باشد، آنگاه پیشبینی ماشین ما خرگوش باشد، یا در مثالی که داشتیم، اگر جسم قرمز باشد، بهاحتمال زیاد آن را توپ در نظر بگیرد.
چرا؟ زیرا از دورهی کودکی ما توپهای قرمز زیادی دیدهایم، اما یک خرگوش قرمز یا یک چوبدستی قرمز در نظر ما بسیار بعید است.
بنابراین در مثالی که داریم ویژگی ما رنگ قرمز است که آن را با هر سه گروه مطابقت میدهیم و میبینیم که احتمال اینکه این جسم یک توپ باشد خیلی بیشتر است.

این تعریف ساده الگوریتم بیز ساده (Naïve Bayes) است. در ادامه بهصورت دقیقتر این الگوریتم را تعریف میکنیم و با مثالی آن را بهتر درک توضیح خواهیم داد.
اما قبل آن، بهتر است با ماشین لرنینگ و تسک طبقهبندی آشنا شویم:

یادگیری ماشین چیست؟
یادگیری ماشین زیرشاخهای از هوش مصنوعی (AI) است که شامل توسعه الگوریتمها و مدلهایی است که میتوانند از دادهها یاد بگیرند و بدون برنامهریزی صریح، پیشبینی یا تصمیم بگیرند. هدف از یادگیری ماشین این است که کامپیوترها را قادر میسازد تا از دادهها به روشی مشابه که انسانها از تجربه یاد میگیرند، یاد بگیرند.
تکنیکهای یادگیری ماشین در طیف گستردهای از برنامهها، از جمله تشخیص تصویر و گفتار، پردازش زبان طبیعی، سیستمهای توصیهگر و وسایل نقلیه خودران استفاده میشوند. در این برنامهها، الگوریتم های یادگیری ماشین دادهها را تجزیه و تحلیل میکنند و از الگوها برای پیشبینی یا تصمیمگیری یاد میگیرند.
یکی از مزایای کلیدی یادگیری ماشین این است که می توان از آن برای مدیریت مجموعه دادههای پیچیده و بزرگ استفاده کرد. استفاده از روشهای برنامهنویسی سنتی برای چنین مجموعههای دادهای دشوار یا غیرممکن است، اما الگوریتمهای یادگیری ماشین میتوانند دادهها را تجزیه و تحلیل کنند و الگوها یا روابط معناداری را استخراج کنند.
انواع مختلفی از الگوریتمهای یادگیری ماشین وجود دارد، از جمله یادگیری تحت نظارت، یادگیری بدون نظارت و یادگیری تقویتی. یادگیری نظارت شده شامل آموزش مدلی بر روی دادههای برچسب گذاری شده است که در آن خروجی مورد نظر برای هر ورودی مشخص است. سپس میتوان از این مدل برای پیش بینی دادههای جدید و بدون برچسب استفاده کرد. یادگیری بدون نظارت شامل آموزش مدلی بر روی دادههای بدون برچسب است و مدل یاد میگیرد که الگوها و روابط موجود در دادهها را شناسایی کند. یادگیری تقویتی شامل آموزش یک مدل برای انجام اقدامات در یک محیط و دریافت پاداش یا جریمه بر اساس اقداماتش، به منظور یادگیری یک خط مشی بهینه است.
طبقهبندی یا Classification چیست؟
طبقهبندی یک تسک اساسی در یادگیری ماشین است که هدف آن پیشبینی کلاس یا دسته یک ورودی داده شده بر اساس ویژگیهای آن است. به عبارت دیگر، با توجه به مجموعهای از دادههای ورودی با برچسبهای متناظر، هدف یک الگوریتم طبقه بندی، یادگیری مدلی است که بتواند برچسب دادههای ورودی جدید و دیده نشده را پیشبینی کند.
دادههای ورودی میتوانند اشکال مختلفی مانند تصاویر، متن یا دادههای عددی داشته باشند، و کلاسها یا دستهها میتوانند باینری (به عنوان مثال، اسپم وغیر اسپم) یا چند کلاسه (به عنوان مثال، دستهبندی تصاویر به انواع مختلف حیوانات) باشند.
فرآیند طبقهبندی معمولاً شامل سه مرحله اصلی است:
آمادهسازی دادهها: این شامل پیشپردازش دادهها برای حذف نویز، نرمالسازی ویژگیها و رسیدگی به مقادیر از دسترفته است. سپس دادهها به یک مجموعه آموزشی و یک مجموعه آزمایشی تقسیم میشوند.
آموزش مدل: مجموعه آموزشی برای آموزش مدل طبقهبندی با استفاده از الگوریتم یادگیری ماشین استفاده میشود. در این مرحله، الگوریتم یاد میگیرد که الگوهایی را در دادههای ورودی که با کلاسهای مختلف مرتبط هستند، تشخیص دهد.
ارزیابی مدل: در این مرحله، عملکرد مدل با استفاده از مجموعه تست که شامل دادههای ورودی است که مدل قبلا ندیده است، ارزیابی میشود.
الگوریتمهای مختلفی مانند درخت تصمیم، ماشین بردار پشتیبان، رگرسیون لجستیک، نایو بیز و شبکههای عصبی میتوانند برای طبقهبندی استفاده شوند. هر الگوریتم نقاط قوت و ضعف خود را دارد و انتخاب الگوریتم به ماهیت دادهها و الزامات خاص کار بستگی دارد.
طبقهبندی یک تکنیک پرکاربرد در بسیاری از برنامهها مانند تشخیص تصویر، پردازش زبان طبیعی و تشخیص تقلب است. این تکنیک برای بسیاری از صنایع، از جمله مراقبتهای بهداشتی، مالی و بازاریابی، که در آن برای تصمیم گیریهای مبتنی بر دادهها و خودکارسازی فرآیندها استفاده میشود، به یک ابزار مهم تبدیل شده است.

بیز ساده (Naïve Bayes) چیست؟
بیز ساده (Naive Bayes) سادهترین الگوریتم یادگیری ماشین است که میتوانیم روی دادههای خود اعمال کنیم. همانطور که از نامش پیداست، این الگوریتم فرض میکند همهی متغیرهای مجموعهی داده ساده (Naïve) هستند، یعنی با یکدیگر ارتباط ندارند.
Naive Bayes یک الگوریتم طبقهبندی محبوب در یادگیری ماشین است. یک الگوریتم احتمالی است که مبتنی بر قضیه بیز است، که احتمال وقوع یک رویداد را بر اساس دانش قبلی از شرایطی که ممکن است با رویداد مرتبط باشد محاسبه میکند.
در Naive Bayes، الگوریتم فرض میکند که ویژگیهای دادههای ورودی مستقل از یکدیگر هستند، که این موضوع محاسبات احتمال را ساده میکند و الگوریتم را از نظر محاسباتی کارآمد میکند. علیرغم این فرض سادهکننده، مشخص شده است که Naive Bayes در بسیاری از کاربردهای دنیای واقعی، بهویژه در پردازش زبان طبیعی (NLP) و وظایف طبقهبندی متن، بسیار مؤثر است.
الگوریتم Naive Bayes با یادگیری احتمال شرطی هر ویژگی داده شده در هر کلاس در دادههای آموزشی کار میکند. هنگامی که دادههای جدید و دیده نشده به الگوریتم ارائه میشود، الگوریتم احتمال هر کلاس را بر اساس ویژگیهای مشاهده شده محاسبه میکند و کلاسی را که بیشترین احتمال را دارد به عنوان کلاس پیشبینی شده برای آن داده انتخاب میکند. با وجود سادگی و فرضیات گفته شده، مشخص شده است که Naive Bayes در طیف گستردهای از وظایف طبقهبندی به خوبی عمل میکند، به خصوص زمانی که میزان دادههای آموزشی در مقایسه با تعداد ویژگیها کم باشد.
این الگوریتم از نظریهی بیز استفاده میکند که فرمول آن بهاین شکل است:
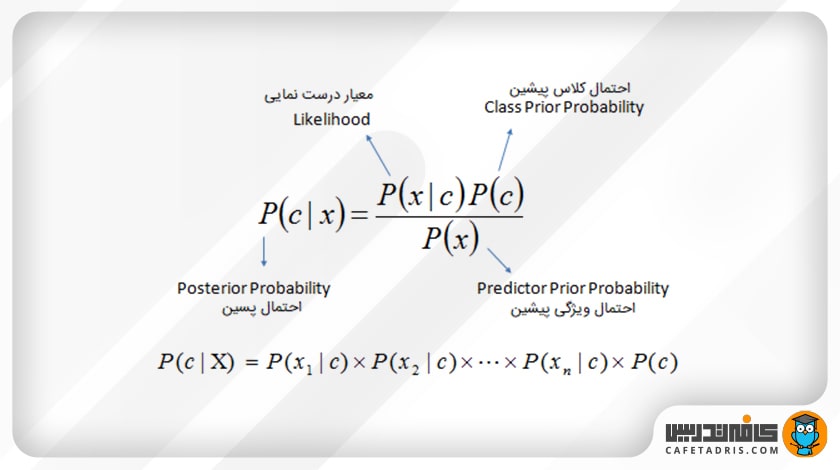
که در آن:
- c نشاندهندهی کلاس مدنظر است؛ مثلاً در مثالی که داشتیم کلاسها خرگوش و چوبدستی و توپ هستند.
- x، نشاندهندهی ویژگیهاست که هر یک بهطور جداگانه باید محاسبه شوند.
- P(c | x) احتمال پسین (Posterior) کلاس c با داشتن پیشبینیکنندهی (ویژگی) x است.
- P(c) احتمال کلاس است.
- P(x | c) معیار درستنمایی (Likelihood) است که احتمال پیشبینیکنندهی x با داشتن کلاس c را نشان میدهد.
- P(x) احتمال پیشین (Prior) پیشبینیکنندهی x است.
برای اینکه بتوانیم از این فرمول و نحوهی استفاده از آن درک بهتری داشته باشیم، در بخش بعد مثالی را با هم بررسی میکنیم.
درک بیز ساده با یک مثال
مجموعهدادهای داریم که شرایط آبوهوایی برای بازی گلف را شرح میدهد. با توجه به شرایط آبوهوایی شرایط برای بازی گلف مناسب (بله) یا نامناسب (خیر) طبقهبندی میشود.
ما در اینجا ۴ ویژگی داریم که اولی آبوهوا (Outlook) است که میتواند بارانی (Rainy)، آفتابی (Sunny) و ابری (Overcast) باشد. دومی دما (Temperature) است که گرم (Hot)، معتدل (Mild) و یا خنک (Cool) میتواند باشد. ویژگی بعدی رطوبت (Humidity) است که دو حالت نرمال (Normal) و بالا (High) را دربرمیگیرد. ویژگی آخر هم باد (Windy) است که میتواند بادی باشد (True) یا بادی نباشد (False) باشد.
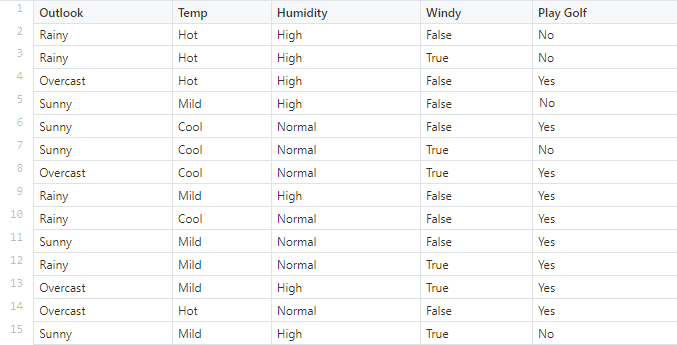
در اینجا احتمال بازیکردن از بین چهارده دادهای که داریم، P (Yes) = 9/14 است و احتمال بازینکردن میان این چهارده داده P (No) = 5/14 است. حال باید احتمالات جداگانهی مرتبط با هر ویژگی، یعنی دما (Temperature)، رطوبت (Humidity)، باد (Windy) و شرایط آبوهوا (Outlook)، را محاسبه کنیم.
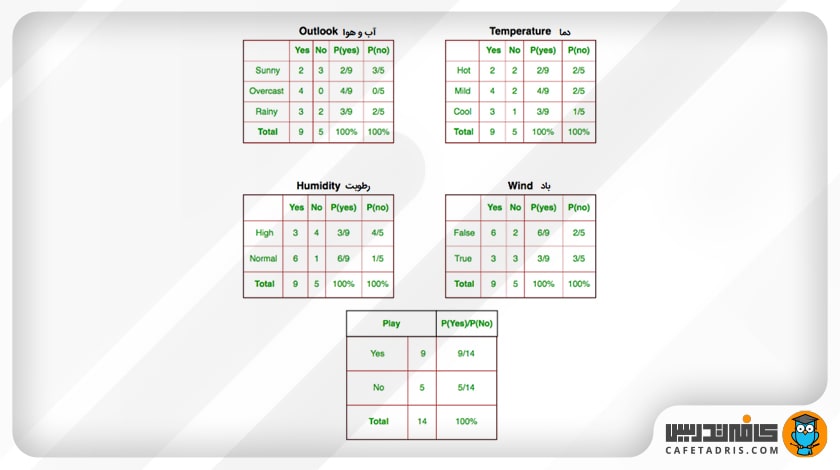
حال فرض کنید باید نمونهی جدید X را طبقهبندی کنیم که اطلاعات آن بهاین شرح است:
- Outlook = sunny
- Temperature = cool
- Humidity = high
- Wind = true
یعنی هوا آفتابی، دما خنک، رطوبت زیاد و باد هم وجود دارد.
بنابراین احتمال بازی گلف بهاین شرح است:
برای شرایطی که این داده جدید دارد هم احتمال بازیکردن و هم احتمال بازینکردن را از روی جدول بالا بار دیگر مینویسیم:
- P(outlook =sunny | play = yes) = 2/9
- P(temperature=cool | play = yes) = 3/9
- P(Humidity = high | play = yes) = 3/9
- P(wind = true | play = yes) = 3/9
- P(play = yes) = 9/14
- P(outlook =sunny | play = no) = 3/5
- P(temperature=cool | play = no) = 1/5
- P(Humidity = high | play = no) = 4/5
- P(wind = true | play = no) = 3/5
- P(play = no) = 5/14
احتمال انجامدادن بازی گلف براساس الگوریتم بیز ساده (Naïve Bayes)
حال با توجه به فرمول بیز ساده، اول احتمال این را که بازی صورت گیرد یا نگیرد برای این دادهی جدید، یعنی X، محاسبه میکنیم. بهاین صورت که یک بار احتمال هر یک از ویژگیها (باد، رطوبت، دما، هوا) را برای صورتگرفتن بازی که در بالا هم بار دیگر از روی جدول برای راحتی کار نوشتیم و احتمال P (Yes) = 9/14، در هم ضرب میکنیم؛ سپس بار دیگر بار احتمال هر یک از ویژگیها (باد، رطوبت، دما، هوا) را برای صورتنگرفتن بازی و احتمال P (No) = 5/14 در هم ضرب میکنیم:

P(X | play = yes).P(play = yes) = 2/9 * 3/9 * 3/9 * 3/9 * 9/14 = 0.0053
0.0206 = 5/14 * 3/5 * 1/5 * 4/5 * 3/5 = (P(X | play = no).P(play = no))
حال که مقدار P (c | x) P (c) را داریم، باید اول مقدار P(X) را به دست آوریم و درنهایت طبق فرمول بیز، P (c | x) P (c) را بر P(X) تقسیم کنیم:
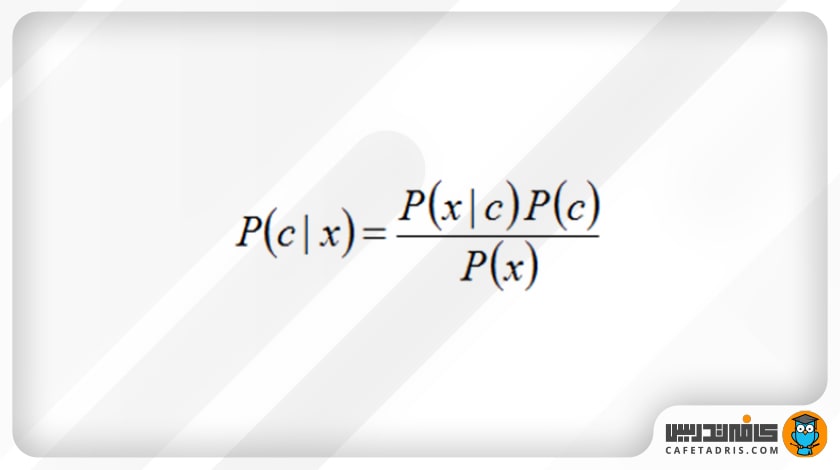
(P(X) = P(Outlook = sunny) * P(Humidity = High) * P(Temperature = Cool) * P(Wind = True
0.02186 = 6/14* 7/14 * 4/14 * 5/14 =
P(play = Yes | X) = (P(X | play = yes).P(play = yes)) / P(X) = 0.2424
P(play = No | X) = (P(X | play = no).P(play = no)) / P(X) = 0.9421
این یعنی با احتمال 0.9421، پیشبینی ما در مورد بازی گلف «نه» است؛ یعنی بازی صورت نمیگیرد.
انواع بیز ساده
سه نوع اصلی بیز ساده وجود دارد:
- Gaussian Naïve Bayes
- Multinomial Naïve Bayes
- Bernoulli Naïve Bayes
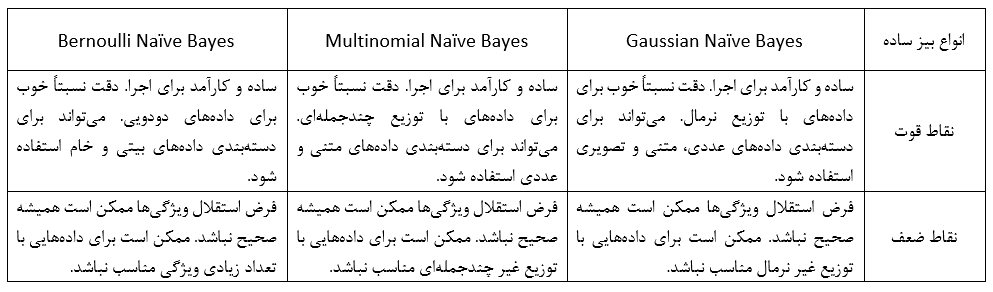
Gaussian Naïve Bayes
Gaussian Naïve Bayes برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها توزیع نرمال دارند. به عنوان مثال، میتوان از این الگوریتم برای دستهبندی متن، تصاویر یا دادههای عددی استفاده کرد.
Multinomial Naïve Bayes
Multinomial Naïve Bayes برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها توزیع چندجملهای دارند. به عنوان مثال، میتوان از این الگوریتم برای دستهبندی متن یا دادههای عددی استفاده کرد.
Bernoulli Naïve Bayes
Bernoulli Naïve Bayes برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها میتوانند فقط دو مقدار داشته باشند، مانند صفر یا یک. به عنوان مثال، میتوان از این الگوریتم برای دستهبندی دادههای بیتی یا دادههای خام استفاده کرد.
مقایسه نقاط قوت و ضعف انواع بیز ساده
مقایسه ویژگیهای انواع بیز ساده

قسمتی از جزوه کلاس برای آموزش بیز ساده
دوره جامع دیتا ساینس و ماشین لرنینگ

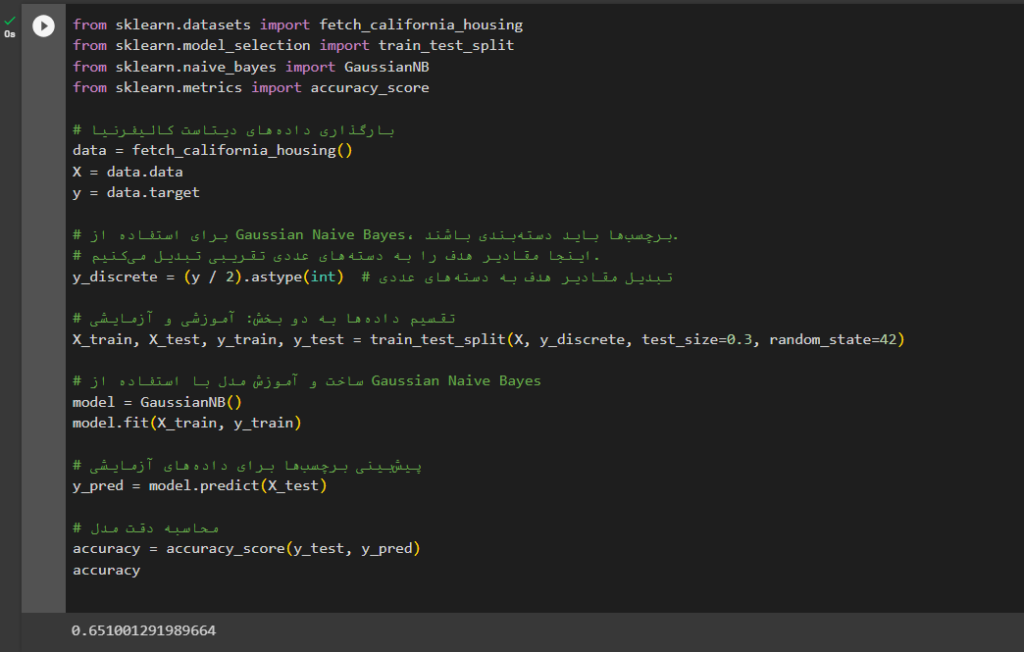
بیز ساده در پایتون
خلاصه مطالب درباره الگوریتم بیز ساده (Naive Bayes)
در این مطلب یکی از الگوریتمهای یادگیری ماشین با ناظر بهنام بیز ساده (Naive Bayes) را بررسی کردیم که عمدتاً برای طبقهبندی استفاده میشود.
الگوریتم بیز ساده (Naive Bayes) بیشتر در تجزیهوتحلیل احساسات (Sentiment Analysis)، فیلتر هرزنامهها (Spam Filtering)، سیستمهای توصیهگر (Recommendation Systems) و غیره استفاده میشود. پیادهسازی آن سریع و آسان است، اما بزرگترین عیب آن نیاز به مستقلبودن پیشبینیکنندهها یا همان ویژگیهاست؛ در دنیای واقعی ویژگیها معمولاً بههموابسته هستند که این عملکرد طبقهبندیکننده ضعیف میکند.
برای آشنایی بیشتر با یادگیری با ناظر این مطلب را مطالعه کنید:
انواع مختلف بیز ساده کدامها هستند و یک توضیح مختصر در مورد هرکدام بنویسید.
سه نوع اصلی بیز ساده وجود دارد:
Gaussian Naïve Bayes
Multinomial Naïve Bayes
Bernoulli Naïve Bayes
Gaussian Naïve Bayes
Gaussian Naïve Bayes برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها توزیع نرمال دارند. به عنوان مثال، میتوان از این الگوریتم برای دستهبندی متن، تصاویر یا دادههای عددی استفاده کرد.
Multinomial Naïve Bayes برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها توزیع چندجملهای دارند. به عنوان مثال، میتوان از این الگوریتم برای دستهبندی متن یا دادههای عددی استفاده کرد.
Bernoulli Naïve Bayes برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها میتوانند فقط دو مقدار داشته باشند، مانند صفر یا یک. به عنوان مثال، میتوان از این الگوریتم برای دستهبندی دادههای بیتی یا دادههای خام استفاده کرد.
گوریتم بیز ساده (Naïve Bayes) برای چه نوع مسائلی مناسب است؟
برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها توزیع چندجملهای دارند
سوال ۳
الگوریتم بیز ساده (Naive Bayes) بیشتر در تجزیهوتحلیل احساسات (Sentiment Analysis)، فیلتر هرزنامهها (Spam Filtering)، سیستمهای توصیهگر (Recommendation Systems) و غیره استفاده میشود.
سوال۱
Gaussian Naïve Bayes:
برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها توزیع نرمال دارند.
Multinomial Naïve Bayesـ
برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها چند جمله ای
دارند.
Bernoulli Naïve Bayes
برای دستهبندی دادههایی استفاده میشود که ویژگیهای آنها میتوانند فقط دو مقدار داشته باشند، مانند صفر یا یک.
عبارت زیر اشتباهه:
P(X) = 0.0053 + 0.0206 = 0.0259
این درسته:
P(X) = P(Outlook=Sunny)*P(Temp=Cool)*P(Humidity=High)*P(Windy=true)
بله درست میگین، اصلاح شد.
خیلی ممنون از متن خوب و توضیحات مفیدتان.
تشکر از شما دوست عزیز
من دیگه ناامید شه بودم که برم سمت ماشین لرنینگ ، اما شما یک معلم خیلی خوب هستید.
ممنون
تشکر از لطف شما.
ممنون ازتون مطلب خیلی کامل و واضح بود
ممنون از اشتراک نظرتون.
خیلی خوشحال میشم وقتی میبینم عزیزانی مثل شما بدون اغراق و بزرگ نمایی برای فروش پکیج هاشون ، میان حقیقت رو بیان میکنن . خداقوت
تشکر از لطف شما دوست عزیز.
سلام رضای عزیز امیدوارم حالت خوب باشه من این کلاس فوق العاده رو تماشا و تمرین کردم و توانستم تمام ویدیو رو تمام کنم حق تون رو حلال کنید خیلی مطالب مفیدی راجب ماشین لزنینگ یاد گرفتم موفق باشید
سلام دوست عزیز، ممنون از اینکه نظرتون رو با ما به اشتراک گذاشتین.
بهترین کاملترین و گیراترین درنوع خود و بکلی از تجربه آموزشی بنده اینجا توسط شما بود.امیدوارم بتونم جبران کنم
ممنون از اینکه نظرتون رو با ما درمیون گذاشتین.
مرسی از مقاله جدید مثل همیشه عالی
ممنون از شما.