
بیش برازش (Overfitting) یکی از خطاهای مدلسازی در علم داده (Data Science) است. این خطا هنگامی اتفاق میافتد که مدل ویژگیهای دادههای آموزشی را بهجای یادگیری، حفظ کرده باشد، یعنی بیشازحد روی آن آموزش دیده باشد؛ درنتیجه، این مدل فقط در مجموعهی دادههای آموزشی مفید خواهد بود و نه در مجموعهی دادههای دیگر که هنوز آنها را ندیده است.
در ادامهی این مطلب بهصورت مفصل به این مفهوم پرداختهایم، دلایل رخدادن آن را توضیح دادهایم و راهحلهای جلوگیری از آن را بررسی کردهایم.
- 1. منظور از شکست تعمیم در ماشینلرنینگ چیست؟
- 2. بیش برازش (Overfitting) چیست؟
- 3. دلایل ایجاد بیشبرازش (Overfitting)
-
4.
راهحلهای مقابله با بیشبرازش
- 4.1. ۱. نگهداشتن دادهها (Holding Out Data)
- 4.2. ۲. اعتبارسنجی متقابل دادهها (Cross Validation)
- 4.3. ۳. افزایش دادهها (Data Augmentation)
- 4.4. ۴. انتخاب ویژگی (Feature Selection)
- 4.5. ۵. نظمدهی (Regularization) L1 / L2
- 4.6. ۶. حذف لایهها در مدل
- 4.7. ۷. دراپاوت (Drop Out)
- 4.8. ۸. توقف زودهنگام (Early Stopping)
- 5. جمعبندی مطالب دربارهی بیشبرازش (Overfitting)
منظور از شکست تعمیم در ماشینلرنینگ چیست؟
شکست تعمیم یا Generalization Failure در یادگیری ماشین به وضعیتی اشاره دارد که مدلی که روی دادههای آموزشی به خوبی عمل میکند، اما در آزمایش یا دادههای اعتبار سنجی (Validation) عملکرد خوبی ندارد. به عبارت دیگر، مدل یاد نگرفته است که به خوبی از دادههای آموزشی به دادههای جدید و دیده نشده تعمیم پیدا کند.
هدف اصلی یادگیری ماشین ایجاد مدلهایی است که بتوانند پیشبینیهای دقیقی را روی دادههای جدید انجام دهند. برای دستیابی به این هدف، مدلها بر روی یک مجموعه داده متشکل از جفت ویژگی ورودی و برچسبهای خروجی مربوطه آموزش داده میشوند. در طول آموزش، مدل سعی میکند الگوها و روابط بین متغیرهای ورودی و خروجی را بیابد، تا بتواند پیش بینیهای دقیقی را روی دادههای جدید انجام دهد.
با این حال، اگر یک مدل بیشازحد پیچیده شود یا با دادههای آموزشی بیشازحد تطبیق پیدا کند، ممکن است به جای یادگیری الگوهای زیربنایی، شروع به حفظ نمونههای آموزشی کند. این موضوع میتواند باعث شود که مدل در دادههای آموزشی عملکرد خوبی داشته باشد، اما در دادههای جدید و دیده نشده ضعیف عمل کند و منجر به مشکل شکست تعمیم شود. برای جلوگیری از شکست تعمیم، استفاده از تکنیکهایی مانند منظمسازی (Regularization)، اعتبار سنجی متقابل (Cross validation) و توقف زودهنگام (Early stopping) در طول فرآیند آموزش ضروری است تا به مدل کمک کند تا تعمیم خوبی از دادههای آموزشی به دادههای جدید را یاد بگیرد.
بیش برازش (Overfitting) چیست؟
قبل از اینکه به بحث اصلی، یعنی تعریف بیش برازش (Overfitting)، وارد شویم، بیایید ابتدا کمی درمورد یادگیری ماشین (Machine Learning) صحبت کنیم. در یادگیری ماشین ما یک مدل ریاضی تعریف میکنیم که دستهای از دادههایی را که در اختیارش میگذاریم بررسی میکند؛ برای مثال، دادههای ما میتواند صدها عکس گل باشد که درنهایت راهی برای پیشبینی آنها ارائه میشود؛ حال هر زمان تصویری از یک گل را به این مدل نشان دهیم، حدس میزند این گل در کدام دسته قرار دارد.
اما اگر یک تصویر کاملاً جدید از گل ببیند که قبلاً ندیده است چطور؟ آیا آن را هم پیشبینی میکند؟
در جواب باید بگوییم بله؛ مدل یادگیری ماشینِ خوب، میتواند دادههای جدید را نیز پیشبینی کند. به این موضوع تعمیم (Generalization) گفته میشود. هدف کلی این است که مدل یک گروه از تصاویر را ببیند و آن را بهخوبی تعمیم دهد تا بتواند تصاویر جدید را پیشبینی کند.
حال، هنگامی که مدل خود را با دادههای آموزشی آموزش میدهیم، ممکن است درنهایت آن را خیلی خوب آموزش دهیم، اما این بهچه معناست؟
مدل یادگیری ماشین با دیدن ویژگیهای موجود در تصویر آن را تشخیص میدهد. درمورد گلها، ممکن است منحنیها، خطوط و الگوهای رنگی برای شناسایی یک گل را ببیند. حال اگر آن را بیشازحد آموزش دهیم، مدل به همان الگوها عادت میکند و نمیتواند چیزی بهجز آنها را پیشبینی کند. اینجاست که بیش برازش (Overfitting) رخ میدهد.
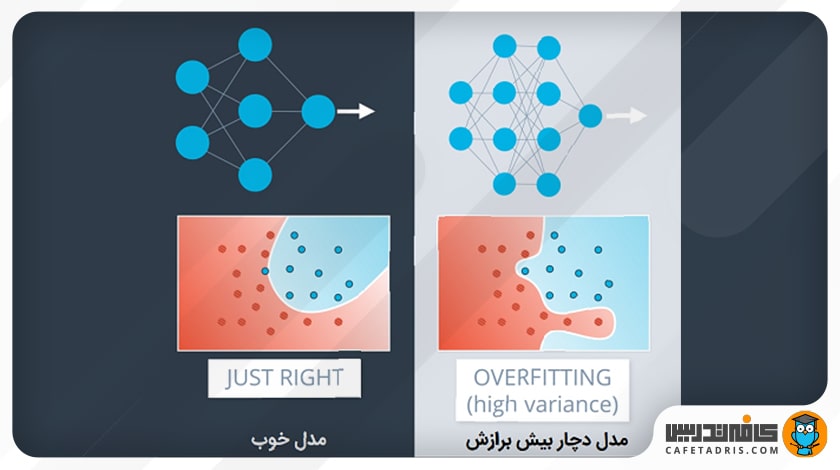
بیش برازش (Overfitting) یا آموزش بیشازحد
تصور کنید وقتی با یک بچه بازی میکنید، به او دایره را یاد میدهید، دایرهی کوچک، بزرگ، قرمز و غیره. حال اگر یک مربع را به او نشان دهید، بچه تشخیص نمیدهد؛ زیرا روی دایره و ویژگیهای آن بیشازحد تمرین کرده است.
بیشبرازش هم دقیقاً همین است. وقتی مدل ما بیشازحد آموزش ببیند، نمیتواند بهخوبی تعمیم یابد و بهجز دادههای آموزشی، نمیتواند پیشبینیهای خوبی انجام دهد.
برای مطالعه دربارهی یادگیری ماشین به این لینکها سر بزنید:
یادگیری ماشین (Machine Learning) چیست و چگونه کار میکند؟
دلایل ایجاد بیشبرازش (Overfitting)
بیشبرازش (Overfitting) میتواند به یکی از این دلایل اتفاق بیفتد:
- مدل بیشازحد پیچیده است و ویژگیهای همخط (Collinear) را دربرمیگیرد که واریانس دادههای ما را افزایش میدهد؛
- تعداد ویژگیهای دادههای ما بیشتر یا برابر با تعداد داده است؛
- حجم داده بسیار کم است.
- داده پیشپردازش نشده تمیز نیست و نویز (Noise) دارد.

راهحلهای مقابله با بیشبرازش
بیش برازش (Overfitting) مسئلهای بسیار رایج در یادگیری ماشین است. روشهای مختلفی هم برای جلوگیری از آن وجود دارد. در این بخش به این روشها اشاره خواهیم کرد.
۱. نگهداشتن دادهها (Holding Out Data)
بهجای استفاده از همهی دادههای خود برای آموزش، میتوانیم بهراحتی مجموعهی داده را به دو مجموعه تقسیم کنیم: آموزش و تست. نسبت معمول میان این دو 80 درصد برای آموزش و 20 درصد برای تست است. مدل خود را آموزش میدهیم تا زمانی که نهتنها در مجموعهی آموزش، در مجموعهی تست نیز عملکرد خوبی داشته باشد. این امر نشاندهندهی قابلیت تعمیم خوب مدل است؛ زیرا مجموعهی تست نشاندهندهی دادههای دیدهنشدهای است که برای آموزش استفاده نشدهاند؛ البته این رویکرد به مجموعهدادهای نسبتاً بزرگ نیاز دارد.
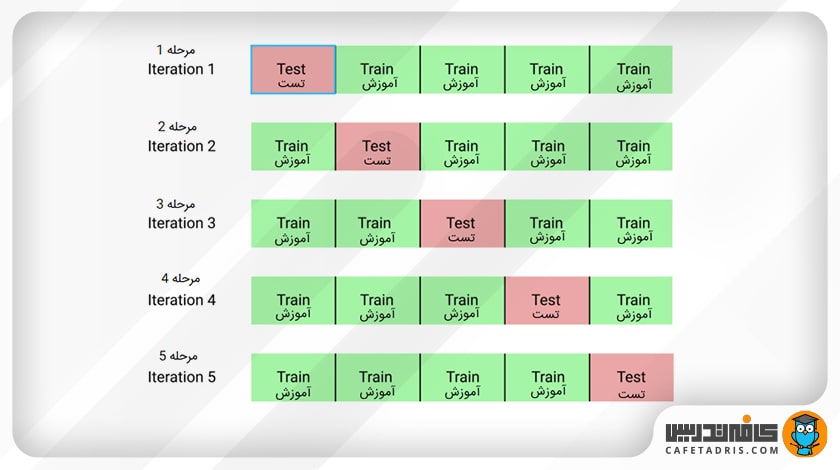
۲. اعتبارسنجی متقابل دادهها (Cross Validation)
میتوانیم مجموعهدادهمان را به k گروه تقسیم کنیم (K-fold Cross Validation). در این روش اجازه میدهیم یکی از گروهها مجموعهی تست و گروه دیگر بهعنوان مجموعهی آموزش باشد. این روند را تا زمانی که هر گروه جداگانه یک بار بهعنوان مجموعهی تست استفاده شود تکرار میکنیم (برای مثال، k بار تکرار میکنیم). برخلاف روش نگهداشتن داده، اعتبارسنجی متقابل اجازه میدهد تا تمامی دادهها یک بار برای آموزش استفاده شوند، اما از طرفی از نظر محاسباتی گرانتر هستند.

۳. افزایش دادهها (Data Augmentation)
یک مجموعه داده بزرگتر از بیشبرازش جلوگیری میکند. اگر نتوانیم دادههای بیشتری جمع کنیم و به دادههایی که در مجموعهی داده فعلی خود داریم محدود باشیم، میتوانیم برای افزایش اندازهی مجموعهدادهمان از روش افزایش داده استفاده کنیم؛ برای مثال، اگر کارمان طبقهبندی تصاویر است، میتوانیم تغییرات مختلف تصویر را در مجموعهدادههای تصویر خود اعمال کنیم؛ برای مثال، معکوسکردن (Flipping)، چرخش (Rotating)، تغییر اندازه (Rescaling) و شیفتدادن (Shifting).
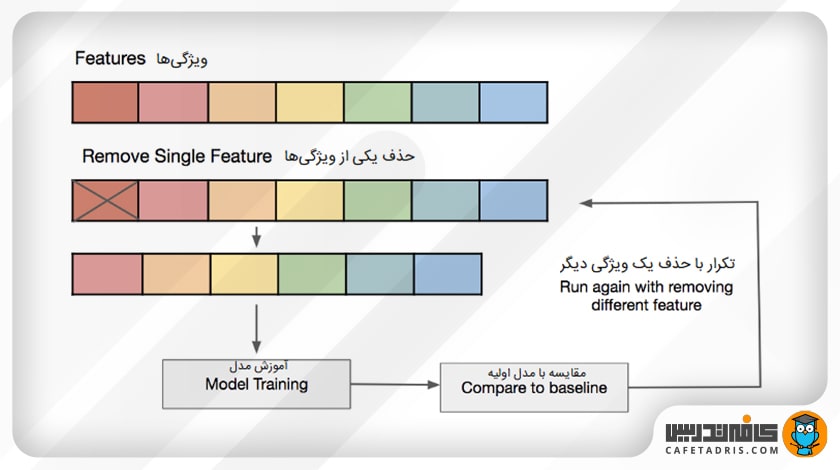
۴. انتخاب ویژگی (Feature Selection)
اگر فقط تعداد محدودی نمونهی آموزشی داشته باشیم که هر یک از آنها تعداد زیادی ویژگی داشته باشند، فقط باید مهمترین ویژگیها را برای آموزش انتخاب کنیم تا مدل ما به یادگیری تمامی ویژگیها مجبور نباشد که سرانجام بیش برازش (Overfitting) اتفاق بیفتد. ما میتوانیم بهسادگی ویژگیهای مختلف را آزمایش کنیم، مدلهای جداگانهای را برای این ویژگیها آموزش دهیم و قابلیت تعمیم مدلها را ارزیابی کنیم یا از یکی از روشهای مختلف انتخاب ویژگی استفاده کنیم.
۵. نظمدهی (Regularization) L1 / L2
نظمدهی تکنیکی است که شبکهی ما را در یادگیری مدلی که بیشازحد پیچیده است و ممکن است به بیشبرازش بینجامد، محدود میکند. در نظمدهی L1 یا L2 میتوانیم برای تابع زیان (Loss Function) یک مجازات در نظر بگیریم تا ضرایب برآوردشده (Coefficients) را بهسمت صفر سوق دهیم. نظمدهی L2 اجازه میدهد وزنها بهسمت صفر پیش بروند، اما به صفر نرسند، درحالیکه تنظیم L1 اجازه میدهد وزنها به صفر برسند.
۶. حذف لایهها در مدل
همانطور که در تنظیم L1 یا L2 ذکر شد، یک مدل بیشازحد پیچیده بهاحتمال زیاد به بیش برازش (Overfitting) خواهد انجامید. بنابراین، ما میتوانیم با حذف لایهها بهطور مستقیم از پیچیدگی مدل بکاهیم و اندازه مدل خود را کاهش دهیم.
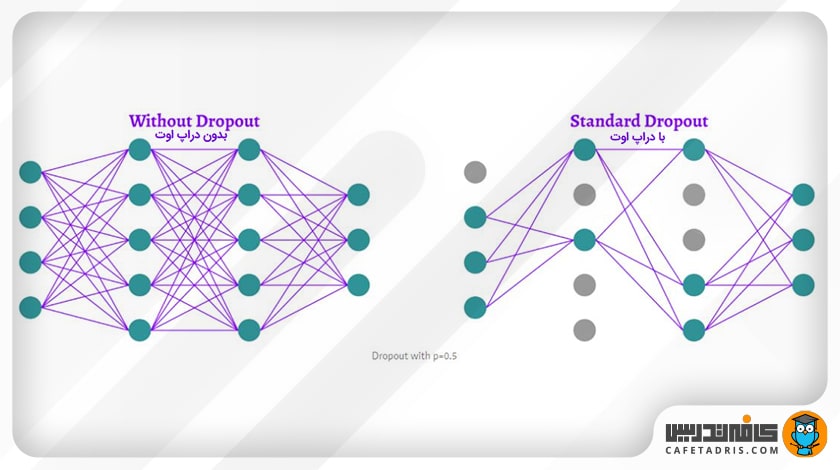
۷. دراپاوت (Drop Out)
با استفاده از این تکنیک که نوعی نظمدهی محسوب میشود، در برخی از لایهها برخی نودها را در نظر نمیگیریم. با استفاده از دراپاوت میتوانیم یادگیری متقابل میان نودها را که ممکن است به بیش برازش بینجامد کاهش دهیم؛ با وجود این، برای اجرای این تکنیک به ایپاکهای (Epoch) بیشتری برای همگراشدن مدل خود نیاز داریم.
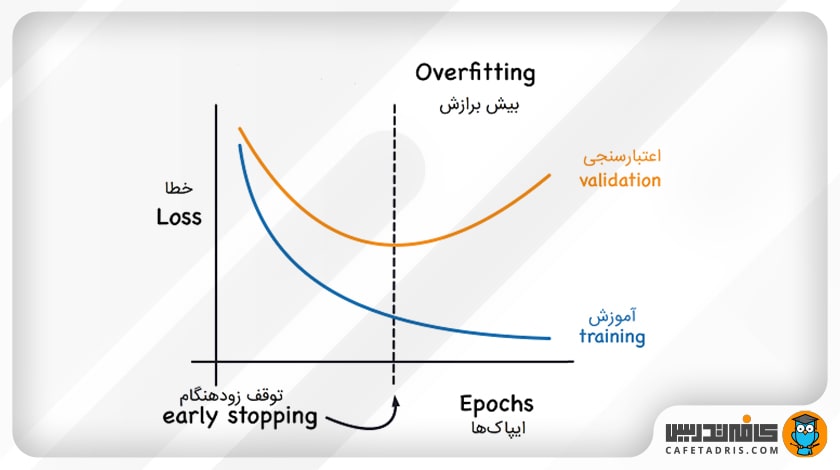
۸. توقف زودهنگام (Early Stopping)
ابتدا میتوانیم مدل خود را برای تعداد دلخواه زیادی از ایپاکها آموزش دهیم و نمودار خطای اعتبارسنجی (Validation) را رسم کنیم. هنگامی که مقدار خطای اعتبارسنجی شروع به افزایش کرد، آموزش را متوقف میکنیم و مدل فعلی را ذخیره میکنیم. مدل ذخیرهشده بهترین مدل برای تعمیم در میان مقادیر مختلف ایپاک برای آموزش آن خواهد بود.

جمعبندی مطالب دربارهی بیشبرازش (Overfitting)
در این مطلب مشکل بیش برازش (Overfitting) را معرفی کردیم و با دلایل ایجاد و همینطور نحوهی مقابله با آن آشنا شدیم. بیشبرازش یکی از مشکلات معمول در حوزهی یادگیری ماشین است که خیلی از مواقع ممکن است در حین آموزش مدل خود با آن مواجه شویم؛ بههمین دلیل، یادگیری تکنیکهای جلوگیری از آن بسیار ضرورت دارد.
یکی از دیگر مشکلات مشابه بیش برازش (Overfitting) مشکل کم برازش (Underfitting) است. برای مطالعه دربارهی این موضوع این مطلب را مطالعه کنید:
کم برازش (Underfitting) چیست و راههای جلوگیری از آن کدام است؟
سلام در قسمت افزایش داده اگر داده های ما عددی بود مثلا قیمت یک کالا چطوری باید داده های جدید ایجاد کنیم؟
برای افزایش دادههای عددی مانند قیمت کالا، میتوانید تکنیکهای زیر را به کار ببرید:
1. جمع کردن نویز: اضافه کردن مقادیر کوچک و تصادفی به دادهها برای ایجاد تنوع.
2. تکثیر ویژگیها: استفاده از ترکیبات ریاضی مختلف میان ویژگیها برای ایجاد ویژگیهای جدید.
3. بوت استرپ: نمونهبرداری با جایگزینی از مجموعه دادههای موجود برای تولید نمونههای جدید.
4. اسکیل کردن: تغییر مقیاس دادهها با استفاده از عوامل مختلف.
5. تغییرات موقتی: اگر دادهها زمانی هستند (مانند قیمتهای روزانه)، تغییر دادهها بر اساس روند یا فصلیت میتواند مفید باشد.
این تکنیکها باید با دقت و با در نظر گرفتن ماهیت دادهها و مدل مورد استفاده به کار روند تا از ایجاد سوگیری در دادهها جلوگیری شود.
سلام از رشته ی برق الکترونیک بدون هیچ پیش زمینه ای میشه وارد این شاخه شد؟ اگر میشه باید از چه زبان هایی برای پیش نیاز استفاده کرد؟
سلام، بله این امکان وجود داره، پیش نیازهای یادگیری علم داده، کمی ریاضی و آمار و احتمال و زبان برنامهنویسی پایتونه.
برای دیتاساینس به چه مباحثی از ریاضی نیاز هست که یاد بگیریم و حرفه ای بشیم؟ممنون
پیشنهاد می کنیم برای دریافت پاسخ این سوال این مطلب رو حتما مطاله کنین: http://ctdrs.ir/ds0065
میشه یک وبینار بزارید مسیر 0 تا 100 ماشیین لررنیگ از کجا با چی چجوری شروع کنیم ؟
وبینارهای رایگان زیادی در این مورد داشتیم، پیشنهاد می کنیم در بخش ویدیوهای آموزشی این صفحه، وبینارها رو بررسی کنین: https://cafetadris.com/datascience
موضوع خوبی بود
اور فیتینگ از دسته موضوعاتی هست که مقاله چندانی به فارسی براش وجود نداره
ممنون از اشتراک نظرتون.
نقطه ی صفر حوزه ی ماشین لرنینگ کجاست؟
لطفا یک نقشه راه درمورد این حوزه مطرح کنید..
نقشهراه در این صفحه قرار داده شده و علاوه بر این در وبینارها در مورد این موضوع صحبت کردیم. پیشنهاد میکنیم وبینارها رو حتما ببینین: https://cafetadris.com/datascience
مدتها دنبال یه منبع فارسی خوب بودم که این اورفیتینگ رو واضح توضیح بده مرسی بالاخره یاد گرفتم
خوشحالیم که مطلب براتون مفید بوده