
شبکهی رزنت (ResNet) یا بهصورت کامل، Residual Network یکی از شبکههای عمیق معروف است. این شبکه را شِیوکینگ رن (Shaoqing Ren)، کِیمینگ هی (Kaiming He)، ژان سان (Jian Sun) و زایانگیا ژوئنگ (Xiangyu Zhang) در سال ۲۱۰۵ معرفی کردند. مدل رزنت تاکنون یکی از محبوبترین و موفقترین مدلهای یادگیری عمیق بوده است. این مدل برندهی چالش ILSVRC در سال ۲۰۱۵ بود. دلیل موفقیت شبکهی رزنت (ResNet) این است که به ما امکان آموزش شبکههای عصبی بسیار عمیق با بیش از ۱۵۰ لایه را داد. قبل از رزنت (ResNet) شبکههای عصبی بسیار عمیق، بهدلیل مشکل محوشدگی گرادیان (Vanishing Gradient)، دچار مشکل میشدند.
- 1. شبکهی رزنت (ResNet) چیست و کاربردهای آن کجاست؟
- 2. مزیتهای شبکهی رزنت چیست؟
- 3. پیش از Residual Network
- 4. اتصالات میانبر، نقطهقوت رزنت
- 5. معماری شبکهی رزنت (ResNet)
- 6. جمعبندی مطالب دربارهی شبکهی رزنت (ResNet)
- 7. با کافهتدریس صفر تا صد علم داده را یاد بگیرید!
- 8. هفتخوان: مطالعه کن، نظر بده، جایزه بگیر!
- 9. هفتخوانپلاس

شبکهی رزنت (ResNet) چیست و کاربردهای آن کجاست؟
طی چند سال اخیر، در حوزهی بینایی ماشین (Computer Vision) پیشرفتهای چشمگیری صورت گرفته است؛ بهخصوص با معرفی شبکههای عصبی عمیق کانولوشن (CNN)، نتایج بسیار خوبی را در زمینهی مسائلی مانند طبقهبندی تصاویر (Image Classification) و شناسایی تصاویر (Image Recognition) به دست آوردهایم.
طی سالها محققان به ایجاد شبکههای عصبی عمیقتر (افزودن لایههای بیشتر) برای حل و بهبود چنین کارهای پیچیدهای تمایل پیدا کردهاند، اما موضوع این است که با افزودن لایههای بیشتری به شبکهی عصبی، آموزش آنها دشوار میشود و دقت عملکرد شبکه شروع به کاهش میکند. اینجاست که رزنت (ResNet) به کمکمان میآید و به حل این مشکل کمک میکند.
در این مطلب با رزنت (ResNet) و معماری آن بیشتر آشنا خواهیم شد.
مزیتهای شبکهی رزنت چیست؟
شبکهی رزنت (ResNet) یک شبکهی عصبی عمیق است که در سال ۲۰۱۵ توانست رتبهی اول را در رقابت ILSVRC کسب کند. قبل از معرفی این شبکه استفاده از شبکههای عصبی با لایههای زیاد دچار مشکل بود. با افزایش تعداد لایهها شبکه دچار مشکل محوشدگی گرادیان (Vanishing Gradient) میشد؛ شبکهی رزنت توانست با ارائهی راهحلی این مشکل را تا حد زیادی برطرف کند؛ بههمین دلیل، این شبکه قادر است حتی تا ۱۵۲ لایه هم داشته باشد.
پیش از Residual Network
شبکههای یادگیری عمیق معمولی، مانند AlexNet، ZFNet و VGGNet، اغلب لایههای کانولوشنی و سپس لایههای کاملاً متصل (Fully Connected) برای طبقهبندی دارند، بدون هیچگونه اتصال میانبر. ما در اینجا آنها را شبکههای ساده (Plain Networks) مینامیم. وقتی شبکهی ساده (Plain Networks) عمیقتر هستند (یعنی لایهها افزایش مییابند)، مشکل محوشدگی گرادیان (Vanishing Gradient) یا انفجار گرادیان (Exploding Gradient) رخ میدهد؛ بنابراین عمیقترکردن شبکه کار راحتی محسوب نمیشد که تنها با اضافهکردن لایه به شبکه آن را عمیقتر کنیم. اینجا بود که شبکهی رزنت (ResNet) معرفی شد تا این مشکل را حل کند. این شبکه میتواند تا ۱۵۲ لایه داشته باشد.
اما رزنت (ResNet) چطور این مشکل را حل کرد؟
اتصالات میانبر، نقطهقوت رزنت
اتصالات میانبر (Skip Connections) یا اتصالات اضافی (Residual Connections) راهحلی بود که شبکه رزنت (ResNet) برای حل مشکل شبکههای عمیق ارائه کرد. در شکل ۱ یک بلاک اضافی (Residual Block) را مشاهده میکنیم. همانطور که در تصویر مشخص است، فرق این شبکه با شبکههای معمولی این است که یک اتصال میانبر دارد که از یک یا چند لایه عبور میکند و آنها را در نظر نمیگیرد؛ درواقع بهنوعی میانبر میزند و یک لایه را به لایهي دورتر متصل میکند.

برای آشنایی با شبکهی عصبی الکسنت این مطلب را مطالعه کنید:
معماری الکس نت (AlexNet) را بهصورت کامل بشناسید!
طرز کار شبکه رزنت با اتصالات میانبر
با توجه به اینکه اکنون یک اتصال اضافی داریم، بنابراین خروجی این بلاک دیگر مانند قبل نیست؛ درواقع قبل از اضافهشدن این اتصال مقدار ورودی x در وزن متناظرش ضرب میشد و با مقدار بایاس (Bias) جمع میشد و درنهایت یک تابع فعالساز ReLU روی آن اعمال میشد.
H(x)=f(wx + b)
یا بهعبارت دیگر:
H(x)=f(x)
اما اکنون که اتصال میانبر را نیز داریم، مقدار x اتصال میانبر هم به مقدار F(X) اضافه میشود.
H(x)=f(x)+x
اما اینجا یک مشکل وجود دارد؛ از آنجا که در طول شبکهی خروجی لایههای مختلف کانولوشن ابعاد مختلفی را دارد، بنابراین ممکن است مقدار x که اتصال میانبر از لایههای قبلی به f(x) اضافه میکند ابعاد متفاوتی را رقم بزند. برای حل این مشکل دو راهحل وجود دارد:
ابعاد اتصال میانبر را با استفاده از فرایند لایهگذاری با صفر (Zero padding) افزایش میدهیم و از لایههای کانولوشن 1*1 برای کاهش ابعاد ورودی استفاده میکنیم؛ در این حالت مقدار خروجی بهاین صورت محاسبه میشود:
H(x)=f(x)+w1.x
در اینجا ما یک پارامتر (وزن) w1 به مقدار x اضافه میکنیم. البته در راهحل اول این اتفاق نمیافتد؛ درواقع با استفاده از اتصالات میانبر در هنگام انتشار روبهعقب، اگر مقدار گرادیان خیلی کوچک شود، این امکان را داریم که با استفاده از این اتصالات به لایههای اولیه برسیم.
معماری شبکهی رزنت (ResNet)
رزنت از یک شبکهی ۳۴ لایهای ساده استفاده میکند که از معماری VGGNet الهام گرفته شده و به این شبکهی اتصالات میانبر اضافه شده است. این شکل نمایی از معماری رزنت (ResNet) را نشان میدهد.
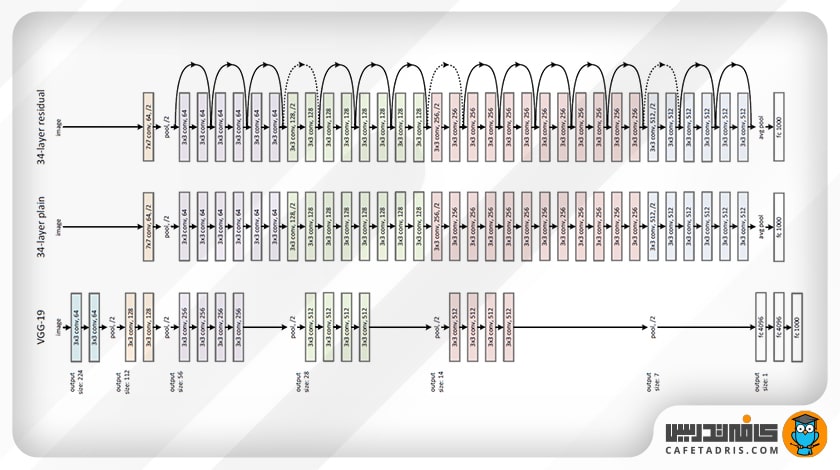
البته شبکه رزنت نسخههای ۵۰، ۱۰۱ و ۱۵۲ لایه نیز دارد. هر قدر شبکه عمیقتر میشود، پیچیدگی زمانی نیز افزایش مییابد. برای حل این مشکل راهحلی ارائه شد که در بخش بعد میبینیم.
طراحی گلوگاه (Bottleneck Design)
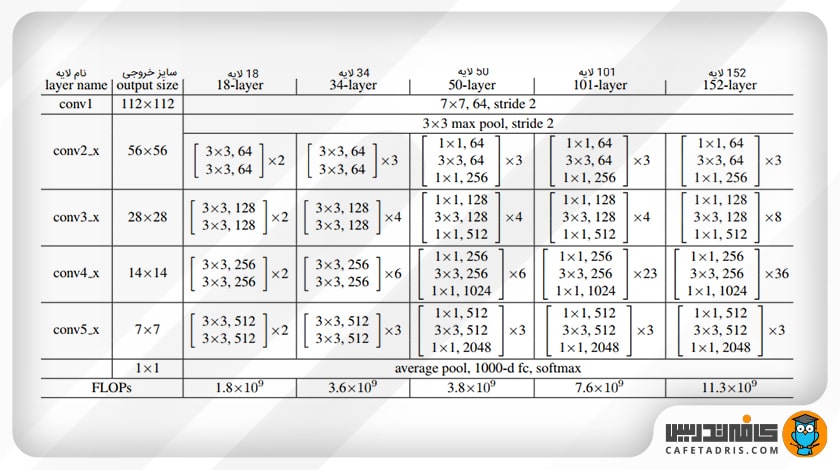
همانطور که در بخش قبل توضیح دادیم، در صورت اضافهشدن لایههای بیشتر به شبکه، پیچیدگی زمانی افزایش مییابد که برای حل آن یک گلوگاه (Bottleneck) طراحی شده است.

راهحل به این شکل بود که به اول و آخر هر لایه کانولوشن یک لایهی کانولوشن ۱×۱ اضافه شد. تکنیک کانولوشن ۱×۱ در شبکهی گوگلنت (GoogleNet) استفاده شده است و نشان میدهد کانولوشنهای ۱×۱ میتوانند تعداد پارامترهای شبکه را کاهش دهند و درعینحال کارایی آن را کاهش ندهند. با طراحی این گلوگاه رزنت ۳۴ لایه به ۵۰، ۱۱۰ و ۱۵۲ نیز افزایش یافت.
برای آشنایی با شبکهی عصبی گوگلنت این مطلب را مطالعه کنید:
گوگل نت (GoogleNet) چیست و از چه ساختاری تشکیل شده است؟
جمعبندی مطالب دربارهی شبکهی رزنت (ResNet)
شبکهی رزنت یک مدل بسیار قدرتمند است که بهطور مکرر در کارهای مربوط به حوزهی بینایی ماشین (Computer Vision) استفاده میشود. این شبکه با حل مشکل محوشدگی گرادیان (Vanishing Gradient) و انفجار گرادیان (Exploding Gradient) به استفاده از شبکههای عمیق کمک بزرگی کرد. در این مقاله ما این شبکه و معماری آن را بررسی کردیم و متوجه شدیم ایدهای که این شبکه را در مقایسه با شبکههای قبل از آن متمایز میکند چیست.
با کافهتدریس صفر تا صد علم داده را یاد بگیرید!
یادگیری علم داده به شما کمک میکند به دنیایی شگفتانگیز وارد شوید و بتوانید با یادگیری این مهارت فرصتهای شغلی بینظیری را هم برای خود فراهم کنید. اگر دوست دارید علم داده را یاد بگیرید و به دنیای دیتا ساینس وارد شوید، پیشنهاد ما شرکت در کلاسهای آنلاین آموزش علم داده کافهتدریس است.
کلاسهای آنلاین آموزش علم داده کافهتدریس بهصورت کاملاً پویا و تعاملی و در قالب دورههای مقدماتی و پیشرفته برگزار میشود. شکل برگزاری این کلاسها بهصورت کارگاهی و مبتنی بر کار روی پروژههای واقعی علم داده است.
شرکت در این کلاسها به شما کمک میکند هر جایی که هستید به بهترین و بهروزترین آموزش علم داده دسترسی داشته باشید.
برای آشنایی با کلاسهای آنلاین آموزش علم داده کافه تدریس و مشاورهی رایگان برای ورود به دنیای دیتا ساینس روی این لینک کلیک کنید:
کلاسهای آنلاین علم داده کافهتدریس

هفتخوان: مطالعه کن، نظر بده، جایزه بگیر!
هفتخوان مسابقهی وبلاگی کافهتدریس است. شما با پاسخ به چند پرسش دربارهی مطلبی که همین حالا مطالعه کردهاید، فرصت شرکت در قرعهکشی جایزه نقدی و کلاس رایگان کافهتدریس را پیدا خواهید کرد.
جوایز هفتخوان
- ۱,۵۰۰,۰۰۰ تومان جایزه نقدی
- ۳ کلاس رایگان ۵۰۰,۰۰۰ تومانی
پرسشهای مسابقه
برای شرکت در هفتخوان کافهتدریس در کامنت همین مطلب به این پرسشها پاسخ دهید:
- شبکهی رزنت (ResNet) چه کاربردهایی دارد و در کدام زمینهها مورد استفاده قرار میگیرد؟
- یکی از مزیتهای اصلی شبکهی رزنت نسبت به سایر شبکههای عصبی چیست؟
- اتصالات میانبر در شبکهی رزنت چگونه به بهبود عملکرد کمک میکنند و اصول اصلی کار آنها چیست؟
هفتخوانپلاس
برای بالابردن شانستان میتوانید این مطلب را هم مطالعه کنید و به پرسشهای آن پاسخ دهید:
شبکهی رزنت (ResNet) چه کاربردهایی دارد و در کدام زمینهها مورد استفاده قرار میگیرد؟
در حوزهی بینایی ماشین (Computer Vision) پیشرفتهای چشمگیری صورت گرفته است؛ بهخصوص با معرفی شبکههای عصبی عمیق کانولوشن (CNN)،
یکی از مزیتهای اصلی شبکهی رزنت نسبت به سایر شبکههای عصبی چیست؟
اتصالات میانبر
معماری شبکهی رزنت (ResNet)
رزنت از یک شبکهی ۳۴ لایهای ساده استفاده میکند که از معماری VGGNet الهام گرفته شده و به این شبکهی اتصالات میانبر اضافه شده است. این شکل نمایی از معماری رزنت (ResNet) را نشان میدهد.
سوال ۳:
اتصالات میانبر یا اتصالات اضافی راهحلی بود که شبکه رزنت (ResNet) برای حل مشکل شبکههای عمیق ارائه کرد.
فرق این شبکه با شبکههای معمولی این است که یک اتصال میانبر دارد که از یک یا چند لایه عبور میکند و آنها را در نظر نمیگیرد؛ درواقع بهنوعی میانبر میزند و یک لایه را به لایهي دورتر متصل میکند.
یک اتصال اضافی داریم، بنابراین خروجی این بلاک دیگر مانند قبل نیست؛ درواقع قبل از اضافهشدن این اتصال مقدار ورودی x در وزن متناظرش ضرب میشد و با مقدار بایاس (Bias) جمع میشد و درنهایت یک تابع فعالساز ReLU روی آن اعمال میشد
سوال ۲:
قبل از معرفی شبکه رزنت استفاده از شبکههای عصبی با لایههای زیاد دچار مشکل بود. با افزایش تعداد لایهها شبکه دچار مشکل محوشدگی گرادیان میشد؛ شبکهی رزنت توانست با ارائهی راهحلی این مشکل را تا حد زیادی برطرف کند؛ بههمین دلیل، این شبکه قادر است حتی تا ۱۵۲ لایه هم داشته باشد.
سوال ۱:
طی سالها محققان به ایجاد شبکههای عصبی عمیقتر (افزودن لایههای بیشتر) برای حل و بهبود چنین کارهای پیچیدهای تمایل پیدا کردهاند، اما موضوع این است که با افزودن لایههای بیشتری به شبکهی عصبی، آموزش آنها دشوار میشود و دقت عملکرد شبکه شروع به کاهش میکند. اینجاست که رزنت (ResNet) به کمکمان میآید و به حل این مشکل کمک میکند
حوزه بینایی ماشین
خیلی سطحی و ضعیف توضیح داده شده
ممنون از اینکه نظرتان را با ما به اشتراک گذاشتید. سعی میکنیم این مقاله را با بازبینی، بهبود دهیم.
بسیار شیوا و رسا توضیح داده شده بود.
ممنون از مطلب عالی تون.
سپاس از توجه شما
بسیار خوب بود ممنون
لطف بعد فنی مقاله را عمیق تر کنید
ممنون از توجه شما
اگه میخواین خیلی عمیقتر این شبکه رو بررسی کنین، پیشنهاد میکنیم مقاله اصلی رو بخونین:
https://arxiv.org/abs/1512.03385v1