
لایه ادغام (Pooling Layer) یکی از مراحل شبکه عصبی کانولوشنی (CNN / Convolutional Neural Network) است. شبکه عصبی کانولوشنی نتایج بسیار قابلقبولی را در حوزههای مختلف بینایی ماشین (Computer Vision)، مانند شناسایی تصاویر (Image Detection)، طبقهبندی تصاویر (Image Classification) و تشخیص چهره (Face Recognition)، داشته است؛ بههمین دلیل، به یکی از پرکاربردترین شبکهها در حوزهی تصویر تبدیل شده است. در این مطلب لایه ادغام (Pooling Layer) در شبکه عصبی کانولوشنی را بررسی میکنیم.
- 1. شبکه عصبی کانولوشنی یا CNN چیست؟
- 2. قبل از لایه ادغام (Pooling Layer) چه اتفاقاتی رخ میدهد؟
- 3. فرایند لایه ادغام
- 4. لایه ادغام (Pooling Layer) چیست؟
- 5. انواع لایه ادغام را بشناسید
- 6. قطعه کد لایه ادغام
- 7. خلاصهی لایه ادغام (Pooling Layer) در شبکه عصبی کانولوشنی (CNN)
- 8. یادگیری علم داده و یادگیری ماشین با کلاسهای آنلاین آموزش علم داده کافهتدریس


شبکه عصبی کانولوشنی یا CNN چیست؟
CNN مخفف کلمه Convolutional Neural Network است که یک نوع شبکه عصبی یادگیری عمیق است که معمولاً برای تجزیه و تحلیل تصویر و ویدئو، پردازش زبان طبیعی و سایر وظایف مربوط به دادههای متوالی استفاده میشود.
معماری یک CNN برای پردازش ورودیها با توپولوژی شبکه مانند، مانند تصاویر طراحی شده است. شبکه از چندین لایه فیلتر تشکیل شده است که در آن هر فیلتر یک عملیات کانولوشن را روی دادههای ورودی اعمال میکند. این کار به شبکه کمک میکند تا ویژگیهای فضایی، مانند لبهها و بافتها را که برای شناسایی الگوها در دادههای ورودی مهم هستند، بیاموزد.
CNNها معمولاً شامل لایههای ادغام میشوند که ابعاد فضایی نقشههای ویژگی یا feature map تولید شده توسط لایههای کانولوشن را کاهش میدهد. این کار به کاهش پیچیدگی محاسباتی شبکه و کارآمدتر کردن آن کمک میکند.
در نهایت، CNNها اغلب شامل لایههای کاملاً متصل (Fully connected layers) هستند که خروجی لایههای کانولوشن و ادغام را میگیرند و آن را به یک پیشبینی یا طبقهبندی تبدیل میکنند. ترکیب این لایهها، CNNها را قادر میسازد تا ویژگیهای معناداری را از دادههای ورودی بیاموزند و استخراج کنند و آن ها را برای طیف وسیعی از کاربردها در بینایی کامپیوتر (Computer Vision) و پردازش زبان طبیعی (Natural Language Processing) مناسب سازد.
قبل از لایه ادغام (Pooling Layer) چه اتفاقاتی رخ میدهد؟
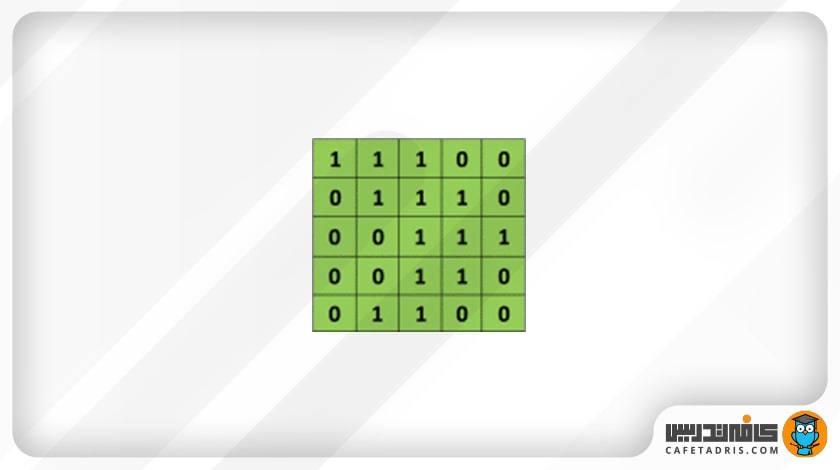
وقتی عکسی به شبکهی عصبی کانولوشنی (CNN / Convolutional Neural Network) وارد میشود، شبکه آن را بهصورت ماتریسی از پیکسلها میبیند. مقدار هر پیکسل عددی میان صفر تا ۲۵۵ است. در شکل زیر یک عکس با سایز ۵×۵ را میبینیم که برای راحتی و درک بهتر مقدار هر پیکسل آن را صفر و ۱ در نظر گرفتهایم.
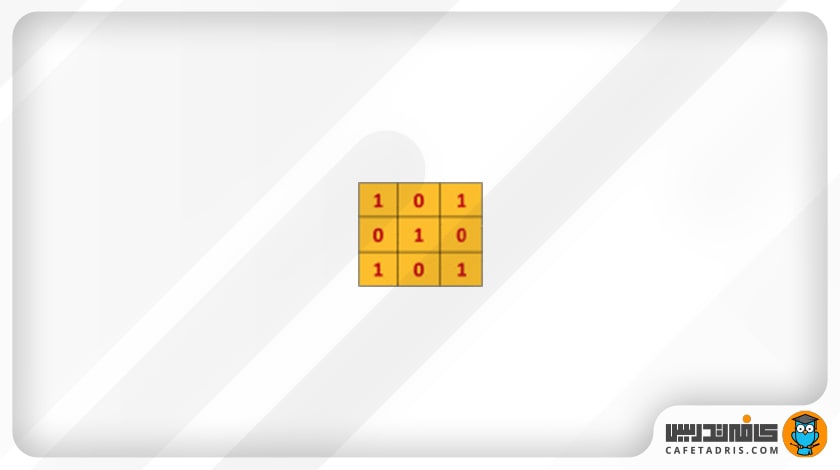
در فرایند کانولوشن مقدار پیکسلهای ماتریس عکس ورودی در یک فیلتر ضرب میشود. فیلتر یک ماتریس است که ممکن است مقادیر و اندازههای مختلفی داشته باشد؛ مثلاً در این مثال یک فیلتر ۳×۳ به این شکل داریم:
این فیلتر مانند یک پنجره کوچک روی عکس ورودی قرار میگیرد؛ بهعبارت دیگر، میتوانیم بگوییم این فیلتر با عکس ورودی ادغام (Convolve) میشود. زمانیکه این فیلتر روی هر بخش از عکس ورودی قرار میگیرد مقدار هر پیکسل آن با مقدار پیکسل متناظرش در ماتریس عکس ورودی ضرب میشود و حاصلجمع ضرب تمامی پیکسلها با پیکسلهای متناظرشان ماتریس جدیدی را ایجاد میکند؛ به آن Convolved Layer / Convolutional Feature / Feature map / Filter map گفته میشود.
در شکل بعدی این فرایند مشاهدهشدنی است؛ بهعبارت دیگر، میتوان گفت در هر بار فرایند کانولوشن ما اندازهی عکس را کوچک و کوچکتر میکنیم. چیزی که به دست میآوریم Feature Map است که نسخهی کوچکشدهی عکس ورودی است و اطلاعات مهم و موردنیاز عکس را به همراه دارد.

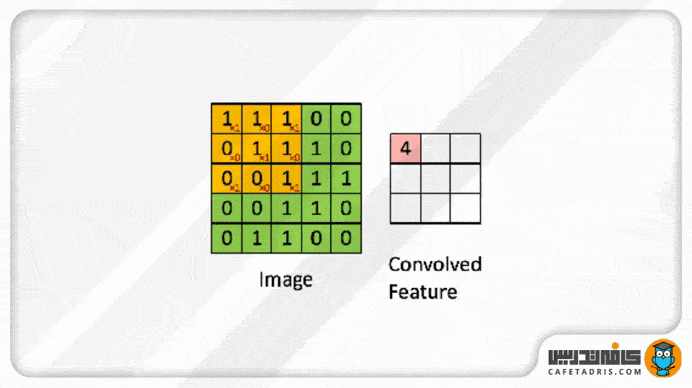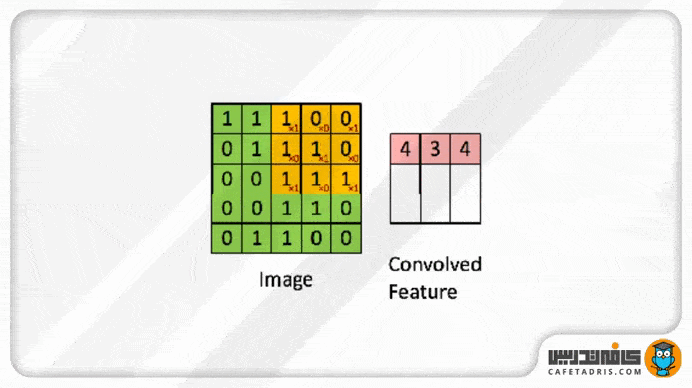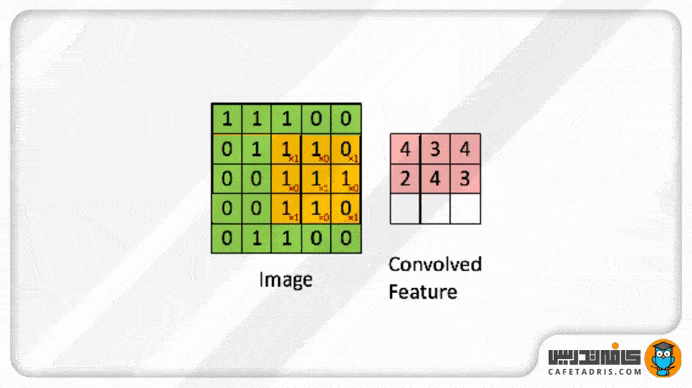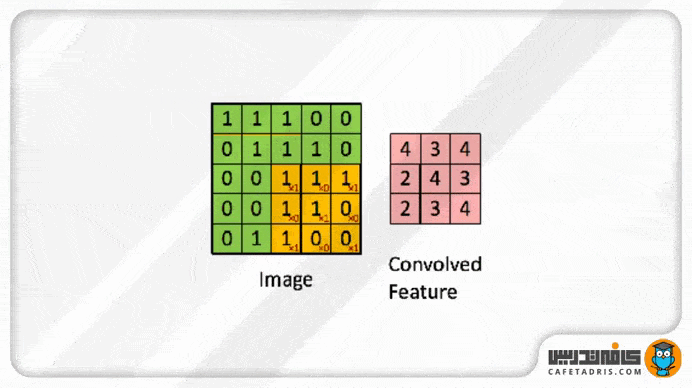
این فیلتر براساس مقداری که برای گام (Stride) مشخص شده است روی ماتریس عکس ورودی حرکت میکند؛ یعنی اگر مقدار گام (Stride) برابر با ۱ باشد، فیلتر هر بار یک پیکسل به جلو حرکت میکند. در شکل بالا مقدار گام (Stride) برابر با ۱ است.


فرایند لایه ادغام
همانطور که در شکل قبلی مشاهده میکنیم، عکس ۵×۵ بعد از فرایند کانولوشن به یک عکس ۳×۳ تبدیل شده است. بهطور کلی، اگر یک عکس n×n داشته باشیم و فیلتر f×f باشد، ابعاد عکس خروجی (n-f+1)×(n-f+1) میشود. در مثالی که داشتیم، عکس ورودی ۵×۵ و فیلتر ۳×۳ است، اندازهی عکس خروجی (۱+۳-۵)×(۱+۳-۵) میشود که همان ۳×۳ است.
همانطور که تا الان متوجه شدیم، از طرفی در هر بار فرایند کانولوشن اندازهی عکس کوچکتر میشود؛ از طرف دیگر، زمانی که فیلتر روی عکس ورودی حرکت میکند، بهوضوح مشخص است که فقط یک بار پیکسلهای لبهی ماتریس را میبیند، درحالیکه فیلتر ممکن است پیکسلهای میانی را بارها ببیند؛ این یعنی اطلاعاتی که در لبههای عکس وجود دارد دور ریخته میشود.
برای جلوگیری از کوچکشدن بیشازحد عکس در طول فرایند کانولوشن و همچنین دورریختهنشدن اطلاعات لبهها از لایهگذاری (Padding) استفاده میشود؛ بههمین دلیل، قبل از اینکه کانولوشن را انجام دهیم، یک یا چند لایه دورتادور عکس اضافه میکنیم؛ معمولاً هم مقدار پیکسلهای آن برابر با صفر است و بههمین دلیل به آن Zero Padding میگویند. بهطور کلی بعد از لایهگذاری اگر یک عکس n×n و فیلتر f×f داشته باشیم، اندازهی ماتریس (عکس) خروجی برابر با (n+2p—f+1)×(n+2p—f+1) است. در این شکل نمونهی لایهگذاری صفر را روی یک عکس ۵×۵ میبینیم.

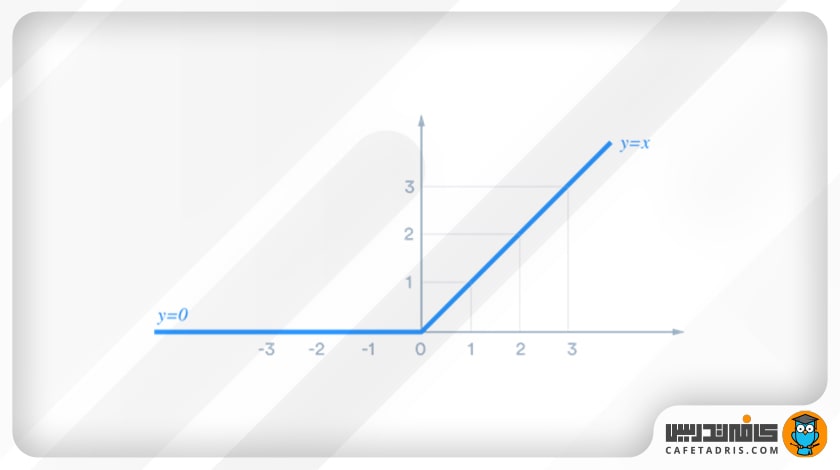
بعد از هر بار لایهی کانولوشن، هر Feature Map بهدستآمده به یک تابع فعالساز واحد یکسوشدهی خطی (ReLU / Rectified Linear Unit) وارد میشود تا درنهایت خروجی غیرخطی داشته باشیم. این تابع در خروجی اعداد منفی را صفر میکند و اعداد مثبت را بههمان شکل بازمیگرداند.
لایه ادغام (Pooling Layer) چیست؟
بعد از هر بار عمل کانولوشن که در خروجی به ما یک نقشهی ویژگی (Feature Map) میدهد یک بار فرایند ادغام (Pooling Layer) انجام میشود.
قبل از اینکه چگونگی فرایند ادغام (Pooling) را بررسی کنیم، بهتر است بدانیم چرا لازم است از آن استفاده کنیم:
- لایه ادغام اندازهی نقشههای ویژگی (Feature Maps) را کاهش میدهد که این خود تعداد پارامترهای یادگیری و همچنین میزان محاسبات شبکه را کاهش میدهد.
- لایه ادغام ویژگیهای موجود در هر ناحیه از نقشهی ویژگی را که لایهی کانولوشن تولید کرده است خلاصه میکند؛ درواقع مهمترین آنها را انتخاب میکند و به مرحلهی بعد منتقل میکند. این باعث میشود مدل در برابر تغییرات موقعیت ویژگیهای موجود در تصویر ورودی مقاومت بیشتری داشته باشد.
انواع لایه ادغام را بشناسید
بهطور کلی سه نوع ادغام (Pooling) وجود دارد:
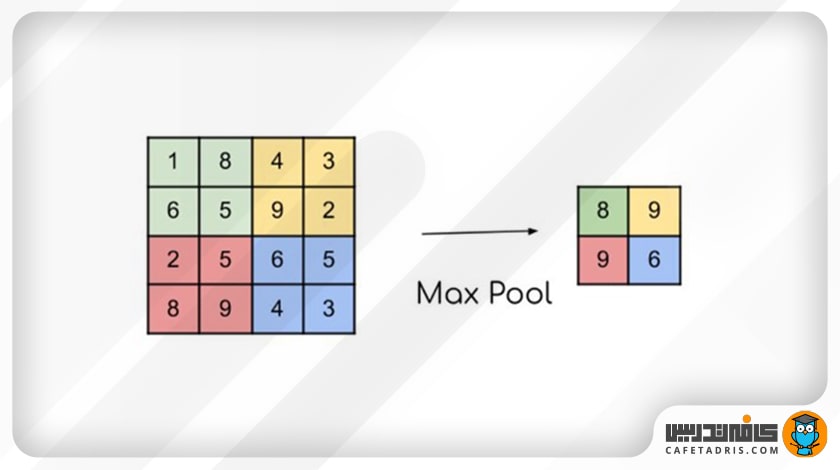
- Max Pooling
در این نوع ادغام بزرگترین مقدار در ناحیهای را که فیلتر پوشانده است انتخاب میشود؛ بنابراین در این حالت خروجی یک نقشهی ویژگی (Feature Map) است که برجستهترین ویژگیهای نقشه ویژگی (Feature Map) قبلی را دارد.
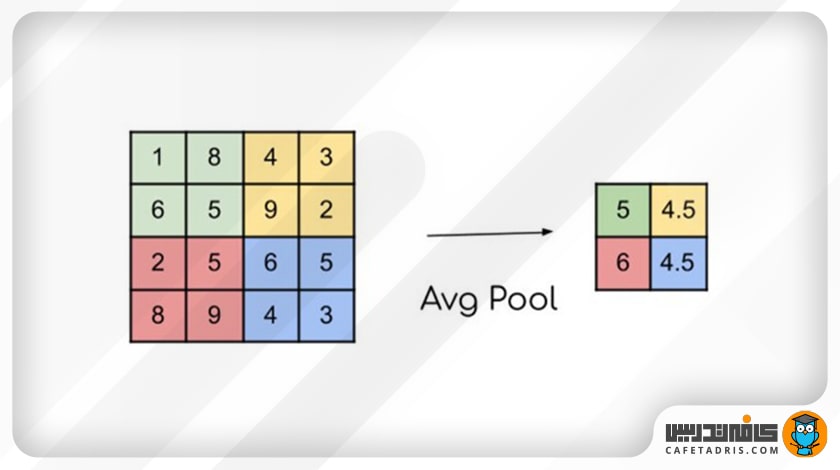
- Average Pooling
در این نوع ادغام مقدار میانگین ناحیهای که فیلتر روی آن قرار میگیرد محاسبه میشود؛ بنابراین میانگین ویژگیهای نقشهی ویژگی قبلی را در خروجی ارائه میکند.
- Sum Pooling
در این نوع ادغام (Pooling) جمع کل ناحیهای که فیلتر پوشانده است محاسبه میشود و یک نقشهی ویژگی جدید را ایجاد میکند.

قطعه کد لایه ادغام
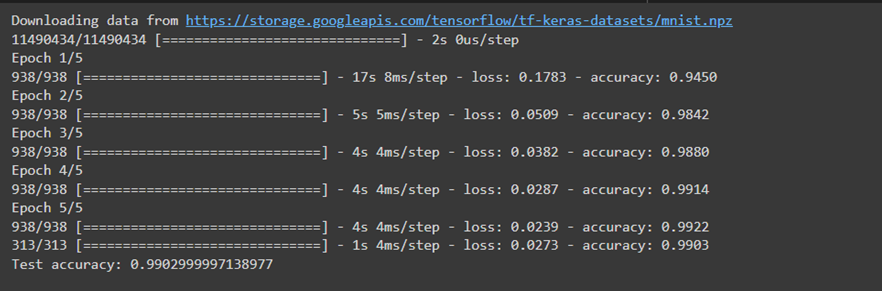
در ادامه میتوانید قطعه کدی شامل طراحی یک شبکه عصبی کانولوشنی برای پیشبینی ارقام دست نوشت انگلیسی (MNIST) ببنید که در آن بعد از هر لایه کانولوشنی، یک لایه ادغام (Pooling) قرار دارد و به دقت ۹۹ درصد روی دادههای تست رسیده است.



در پایان با استفاده از تابع isinstance خروجی لایههایی که در آنها از Pooling استفاده شده است را نمایش میدهیم:

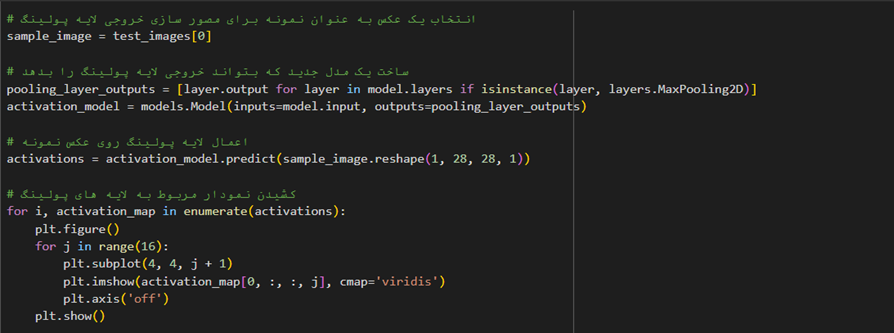




توجه کنید که هر یک از این Feature Map ها مربوط به خروجی یکی از کرنلهای MaxPooling مدل است و هر چه جلوتر میرویم، این خروجی برای ما غیر قابل فهمتر میشود چرا که هر Feature Map، اطلاعات خلاصهشدهتری از Receptive Field اولیه را نگه میدارد. البته همین اطلاعات برای ماشین کافی است تا بتواند لیبل آن را مشخص کند.
خلاصهی لایه ادغام (Pooling Layer) در شبکه عصبی کانولوشنی (CNN)
همانطور که توضیح داده شد، لایهی ادغام با کوچککردن اندازهی عکس ورودی و خلاصهسازی ویژگیهای اصلی و مهم موجود در عکس، به کاهش محاسبات شبکه و مشکل Overfitting کمک میکند؛ بههمین دلیل، یکی از مهمترین فرایندها در شبکه عصبی کانولوشنی (CNN / Convolutional Neural Network) محسوب میشود.
برای آشنایی بیشتر با بینایی ماشین مطلب بینایی ماشین (Computer Vision) چیست و چه کاربردهایی دارد؟ را مطالعه کنید.
یادگیری علم داده و یادگیری ماشین با کلاسهای آنلاین آموزش علم داده کافهتدریس
کافهتدریس بهصورت جامع کلاسهای آنلاین آموزش علم داده را برگزار میکند. این کلاسها بهشکل پویا و تعاملی و در قالب مقدماتی و پیشرفته برگزار میشود و به شما امکان میدهد از هر نقطهی جغرافیایی به بهروزترین و جامعترین آموزش دیتا ساینس دسترسی داشته باشید.
برای آشنایی با کلاسهای آنلاین آموزش علم داده کافهتدریس و مشاورهی رایگان برای شروع یادگیری روی این لینک کلیک کنید: