
ماشین بردار پشتیبان (Support Vector Machine) یا بهاختصار SVM یک مدل یادگیری ماشین با ناظر (supervised Learning) است که با توجه به دادههای برچسبدار آموزشی (یادگیری با ناظر)، یک هایپرپلین (Hyperplane) بهینه را ارائه میکند تا دادههای جدید را به دستههای مختلف طبقهبندی کند.
- 1. یادگیری ماشین چیست؟
- 2. ماشین بردار پشتیبان (Support Vector Machine) چیست؟
- 3. کاربردهای ماشین بردار پشتیبان
- 4. ماشین بردار پشتیبان چطور کار میکند؟
- 5. ماشین بردار پشتیبان و دادههای غیرخطی
- 6. بررسی چند مفهوم رایج در الگوریتم ماشین بردار پشتیبان
- 7. چالشها و محدودیتهای SVM
- 8. قسمتی از جزوه کلاس برای آموزش الگوریتم SVM
- 9. قطعه کد الگوریتم ماشین بردار پشتیبان
- 10. جمعبندی دربارهی ماشین بردار پشتیبان (Support Vector Machine)

یادگیری ماشین چیست؟
یادگیری ماشین زیرشاخهای از هوش مصنوعی است که بر توسعه الگوریتمهایی تمرکز دارد که میتوانند از دادهها یاد بگیرند و بر اساس آن یادگیری، پیشبینی یا تصمیم بگیرند. هدف یادگیری ماشین این است که کامپیوترها را قادر سازد تا از تجربه یاد بگیرند و بدون برنامه ریزی صریح، پیشرفت کنند.
سه نوع اصلی یادگیری ماشین وجود دارد:
یادگیری تحت نظارت (Supervised Learning)، یادگیری بدون نظارت (Unsupervised Learning) و یادگیری تقویتی (Reinforcement Learning) . در یادگیری نظارت شده، الگوریتم بر روی یک مجموعه داده برچسبگذاری شده آموزش داده میشود، به شکلی که دادههای ورودی با خروجی صحیح مرتبط میشوند. الگوریتم یاد میگیرد که با به حداقل رساندن خطا بین خروجی پیش بینی شده و خروجی واقعی، ورودی را به خروجی نگاشت کند. این نوع یادگیری برای کارهایی مانند طبقه بندی (Classification) ، رگرسیون (Regression) و پیشبینی استفاده میشود.
به عنوان مثال، در یک تسک طبقهبندی، دادههای ورودی ممکن است تصاویری از ارقام دست نویس باشند، و برچسبهای خروجی ممکن است خود ارقام باشند. این الگوریتم بر روی یک مجموعه داده برچسبگذاری شده از بسیاری از این تصاویر و برچسبهای مرتبط آموزش داده میشود و یاد میگیرد که الگوهای موجود در دادههای ورودی را که با هر برچسب خروجی مرتبط هستند، تشخیص دهد. هنگامی که الگوریتم آموزش داده شد، می توان از آن برای طبقه بندی تصاویر جدید و دیده نشده بر اساس الگوهای آموخته شده استفاده کرد.
یادگیری تحت نظارت به طور گسترده در بسیاری از برنامههای کاربردی دنیای واقعی، مانند تشخیص تصویر، تشخیص گفتار، پردازش زبان طبیعی و سیستم های توصیهگر استفاده میشود. با این حال، برای آموزش الگوریتم به مقدار زیادی داده برچسبگذاری شده نیاز دارد که دستیابی به آن زمانبر و پرهزینه است.
الگوریتم ماشین بردار پشتیبان یا SVM هم نوعی یادگیری ماشین تحت نظارت یاSupervised Learning است که قصد داریم در این مطلب به معرفی آن بپردازیم.
ماشین بردار پشتیبان (Support Vector Machine) چیست؟
ماشین بردار پشتیبان یا Support Vector Machine که بهاختصار به آن SVM گفته میشود یک الگوریتم یادگیری ماشین با ناظر است که نمونهی دادههایی را بهصورتی نقاطی در فضا نشان داده شده است، با استفاده از یک خط یا هایپرپلین (Hyperplane)، از هم جدا میکند. این جداسازی بهگونهای است که نقاط دادهای که در یک طرف خط هستند مشابهبههم و در یک گروه قرار میگیرند. نمونهدادههای جدید هم بعد از اضافهشدن به همان فضا در یکی از دستههای موجود قرار خواهند گرفت.
کاربردهای ماشین بردار پشتیبان
الگوریتم ماشین بردار پشتیبان (SVM) با قابلیت تشخیص دقیق الگوها و دستهبندیهای پیچیده، در حوزههای گوناگونی کاربرد دارد. برخی از کاربردهای برجستهی این الگوریتم در زندگی واقعی عبارتاند از:
- مطالعات زمینشناسی: استفاده از SVM برای تعیین ساختارهای زیرزمینی.
- پیشبینی مایع شدن خاک: کمک به ارزیابی پتانسیل مایع شدن خاک در هنگام زلزلهها.
- بیوانفورماتیک: تشخیص ساختارهای پروتئینی و شناسایی توالیهای همولوژیک.
- تشخیص حالت چهره: کاربرد در تشخیص و طبقهبندی حالات چهره در تصاویر.
- طبقهبندی بافت در تصاویر: توانایی تفکیک و تشخیص انواع بافتها در تصاویر.
- تشخیص Stenography: شناسایی اطلاعات پنهان در تصاویر دیجیتال.
- پزشکی: استفاده در تشخیص و پیشبینی بیماریها، مانند سرطان.
ماشین بردار پشتیبان چطور کار میکند؟
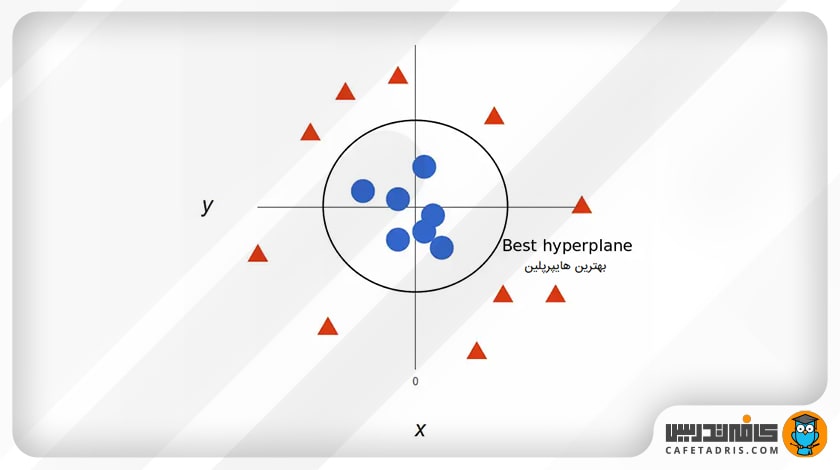
برای درک نحوهی عملکرد ماشین بردار پشتیبان (SVM) بیایید مثال خرگوش و ببر را در نظر بگیریم. بیایید اکنون یک سناریوی کوچک را در نظر بگیریم و وانمود کنیم صاحب مزرعهای هستیم و بنا به دلایلی میخواهیم حصاری برای محافظت از خرگوشهای خود دربرابر ببرها ایجاد کنیم.
حصار خود را کجا بسازیم؟
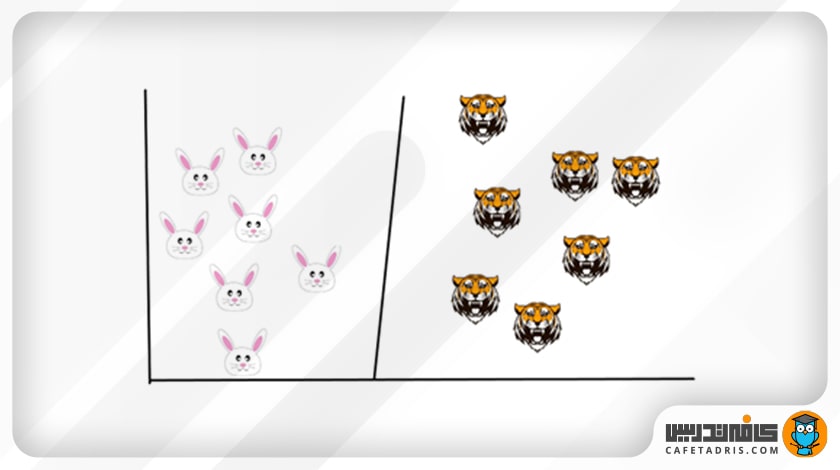
یکی از راهحلهای این مشکل این است که یک طبقهبندی براساس موقعیت خرگوشها و ببرها ایجاد کنیم. میتوانیم گروه خرگوشها را بهعنوان یک گروه و گروه ببرها را بهعنوان گروه دیگر طبقهبندی کنیم.
در حال حاضر، اگر سعی کنیم یک مرز میان خرگوشها و ببرها بکشیم، یک خط مستقیم خواهد شد (لطفاً به تصویر بعدی نگاه کنید). ماشین بردار پشتیبان (SVM) نیز دقیقاً بهاین شکل عمل میکند؛ یک مرز تصمیمگیری ترسیم میکند که درواقع یک هایپرپلین میان دو کلاس است تا آنها را از هم جدا و طبقهبندی کند.
چگونه بدانیم هایپرپلین را کجا باید بکشیم؟
اصل اساسی ماشین بردار پشتیبان این است که یک هایپرپلین ترسیم کنیم که دو کلاس را بهبهترین شکل از یکدیگر جدا کند. حال درمورد مثال ما دو کلاس خرگوش و ببر هستند؛ بنابراین ما با ترسیم یک هایپرپلین رندوم شروع میکنیم و سپس فاصلهی میان هایپرپلین و نزدیکترین نقاط دادهی هر کلاس را بررسی میکنیم.
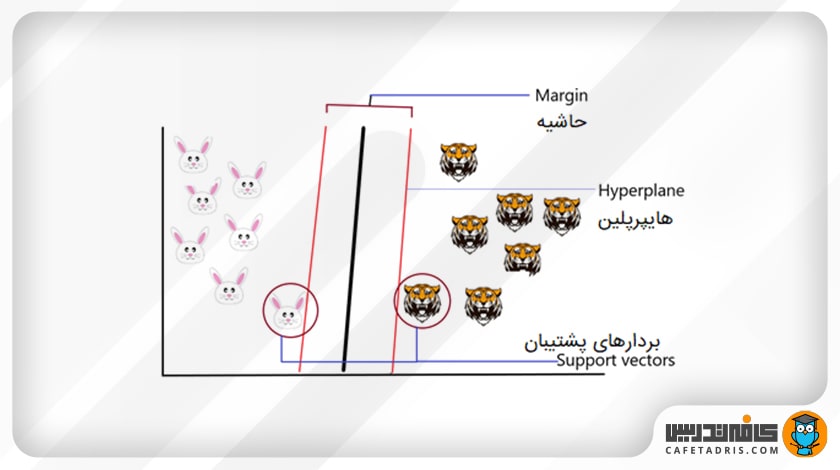
این نقاط داده نزدیک به هایپرپلین بردارهای پشتیبان (Support Vectors) نامیده میشوند؛ بههمین دلیل است که به این الگوریتم ماشین بردار پشتیبان (SVM) گفته میشود. اساساً هایپرپلین براساس این بردارهای پشتیبان ترسیم میشود. بهطور معمول هایپرپلینی که بیشترین فاصله از بردارهای پشتیبان را داشته باشد بهینهترین هایپرپلین است. این فاصلهی میان هایپرپلین و بردارهای پشتیبان حاشیه(Margin) نامیده میشود.
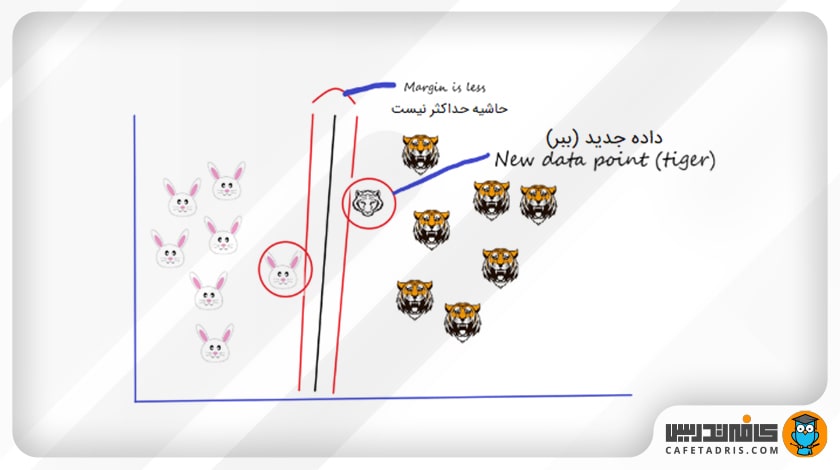
حال بیایید فرض کنیم یک نقطهی دادهی جدید اضافه کنیم (در این مثال ببر دیگری اضافه شده است). اکنون می خواهم یک هایپرپلین بکشیم تا این دو کلاس را بهبهترین شکل از هم جدا کند؛ بنابراین، با ترسیم هایپرپلین، همانطور که در تصویر بالا نشان داده شده است، شروع می کنیم؛ سپس فاصلهی میان این هایپرپلین و بردارهای پشتیبان را بررسی می کنیم که آیا حاشیهی این هایپرپلین حداکثر است یا خیر. در این شکل حاشیهی خیلی هم زیاد نیست.
در سناریوی دوم، یک هایپرپلین متفاوت، مانند تصویر زیر، ترسیم می کنیم و سپس فاصلهی میان هایپرپلین و بردارهای پشتیبان را بررسی میکنیم که آیا حاشیهی این هایپرپلین حداکثر است یا خیر.
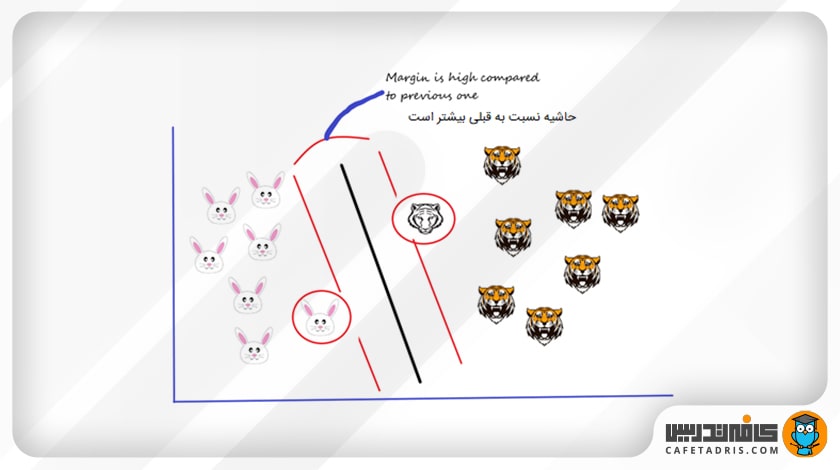
میبینیم که حاشیه در مقایسه با هایپرپلین قبلی بسیار زیاد است؛ بنابراین ما این هایپرپلین را انتخاب میکنیم.

ماشین بردار پشتیبان و دادههای غیرخطی
در مثال قبل دیدیم که دادههای ما تا کنون بهصورت خطی تفکیکپذیر بودند، یعنی میتوانستیم یک خط مستقیم برای جداکردن دو کلاس بکشیم، اما اگر نقاط دادهی ما بهشکل زیر باشد، چه کنیم؟ این دو کلاس با یک خط مستقیم از هم جدا نمیشوند.
در الگوریتم ماشین بردار پشتیبان، هنگام ساختن یک هایپرپلین برای نقاط دادهی تفکیکپذیر خطی کار آسانی است، اما وقتی دادهها غیرخطی تفکیکپذیر باشند، کار بسیار چالشبرانگیز خواهد بود.

هنگامیکه نقاط داده را نمیتوان با یک خط مستقیم یا یک هایپرپلین مستقیم جدا کرد، مسئله غیرخطی نامیده میشود. در چنین شرایطی کرنلهای ماشین بردار پشتیبان (SVM) وارد عمل میشوند و ابعاد فضا را افزایش میدهند تا نقاط داده بهصورت خطی تفکیکپذیر شوند.
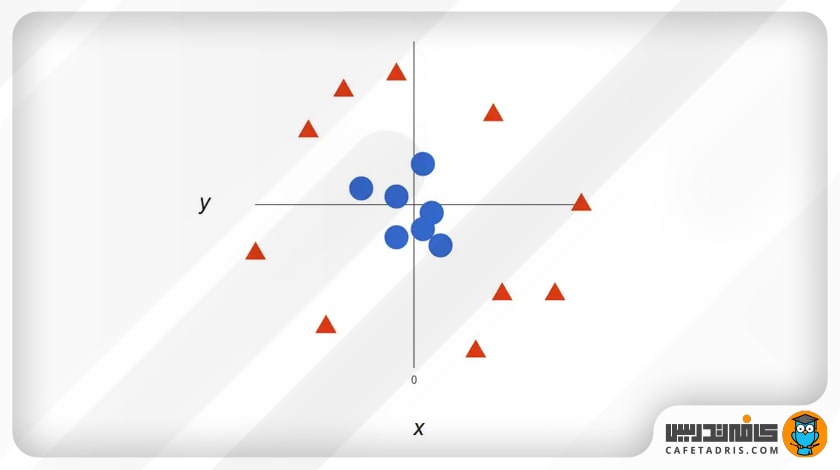
پس اگر دادههای اولیه ما بهشکل بالا باشند، لازم است که ما بعد سوم را اضافه کنیم. تابهحال ما دو بعد داشتیم: x و y. حال یک بعد z جدید ایجاد میکنیم که بهاین شکل محاسبه میشود: z = x² + y² (اگر دقت کنید این معادله یک دایره است).
این کار به ما فضایی سهبعدی میدهد که بهاین شکل میتوان آن را در اینجا نشان داد:
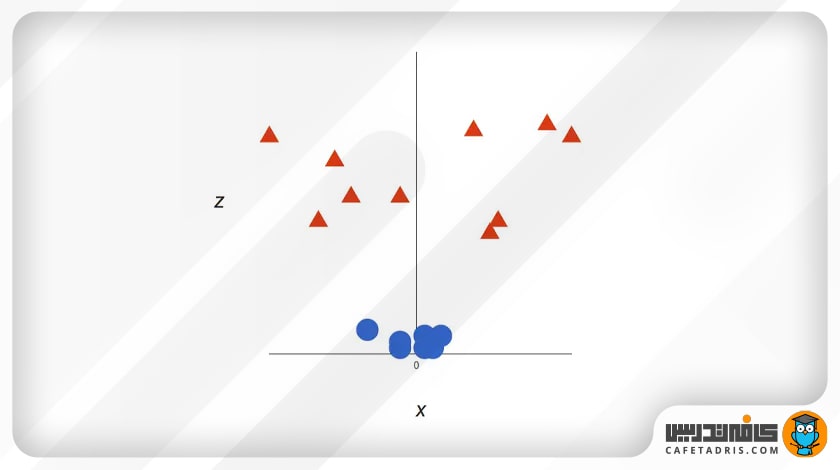
اما ماشین بردار پشتیبان الان چطور تفکیک را انجام میدهد؟ اجازه بدهید با هم ببینم:
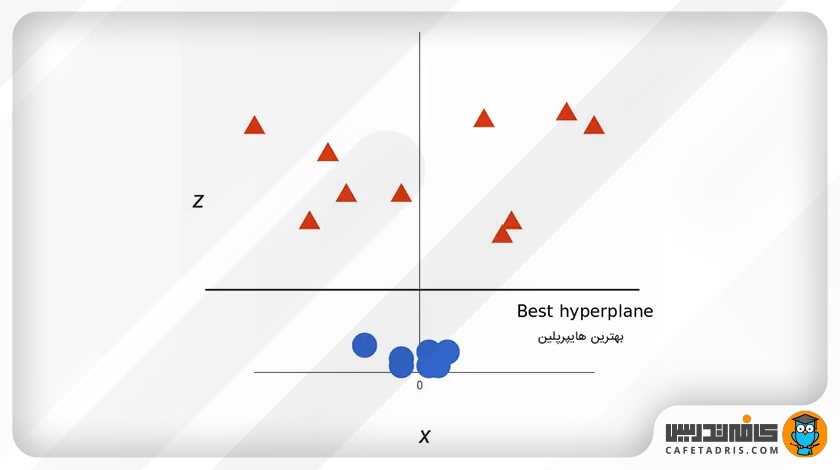
پس نقاط دادهی ما در حال حاضر بهراحتی با یک خط تفکیک شدند. آنچه باقی مانده ترسیم مجدد آن بهشکل دوبعدی است:
در حال حاضر کار طبقهبندی دادهها به پایان رسیده است. درواقع به این فرایند که توضیح داده شد حقهی کرنل (Kernel Trick) گفته میشود.
بررسی چند مفهوم رایج در الگوریتم ماشین بردار پشتیبان
حاشیه (Margin)
حاشیه در SVM به فضایی بین دستههای دادههای طبقهبندی شده اشاره دارد. فرض کنید حاشیه مانند منطقهای امن بین دو گروه است که میخواهیم جدا کنیم؛ هدف این است که این منطقه را تا جای ممکن گسترده کنیم تا حتی اگر دادههای جدیدی اضافه شوند، با اطمینان بیشتری بتوانیم آنها را طبقهبندی کنیم. حاشیه بزرگتر نشاندهنده جداسازی قویتر و در نتیجه، مدل دقیقتری است.
هایپرپلین (Hyperplane)
هایپرپلین در SVM، خط یا صفحهای است که دادهها را به دو دسته جدا میکند. در فضای دوبعدی، این یک خط مستقیم است؛ اما در فضاهای با ابعاد بالاتر، به صفحهای بزرگتر تبدیل میشود که میتواند دادهها را در ابعاد مختلف جدا کند. هایپرپلین بهینه آن صفحهای است که بزرگترین حاشیه را بین دستههای مختلف دادهها ایجاد میکند.
فضای ویژگی (Feature Space)
فضای ویژگی به بعد یا دامنهای گفته میشود که در آن دادهها نمایش داده میشوند و تجزیه و تحلیل میشوند. در SVM، تبدیل دادهها به فضای ویژگی بالاتر این امکان را فراهم میکند که دادههایی که در ابعاد اصلی خود قابل جداسازی خطی نیستند، به شکلی تبدیل شوند که بتوان آنها را به طور خطی جدا کرد.
انواع کرنلها
کرنلها در SVM به ما اجازه میدهند تا دادههایی که بهصورت خطی جداسازیپذیر نیستند را به فضای ویژگی بالاتری انتقال دهیم که در آن جداسازی ممکن است. انواع مختلفی از کرنلها وجود دارند که هرکدام برای دادهها و مسائل مختلف مناسب هستند. کرنل خطی، کرنل چندجملهای، کرنل رادیال بیس (RBF) و کرنل سیگموئید از جمله رایجترین کرنلها هستند.
چالشها و محدودیتهای SVM
استفاده از الگوریتم ماشین بردار پشتیبان (SVM) در یادگیری ماشین دارای مزایای بسیاری است، اما مانند هر روش دیگر، چالشها و محدودیتهای خاص خود را دارد. در اینجا، به برخی از این محدودیتها و چالشها میپردازیم:
انتخاب کرنل
یکی از چالشهای عمده در استفاده از SVM، انتخاب نوع کرنل مناسب است. اگر کرنل انتخابی با ماهیت دادهها همخوانی نداشته باشد، مدل نهایی نمیتواند الگوهای پیچیده را یاد بگیرد و این موضوع میتواند به کاهش دقت پیشبینیها منجر شود.
مقیاسبندی ویژگیها
الگوریتم SVM به مقیاس ویژگیها حساس است. ویژگیهایی که در مقیاسهای بزرگتر قرار دارند میتوانند تأثیر نامتناسبی بر مدل نهایی داشته باشند و باعث میشوند که مرز تصمیمگیری بیش از حد به سمت ویژگیهای با مقیاس بزرگتر کج شود. بنابراین، مقیاسبندی ویژگیها قبل از آموزش مدل ضروری است.
دادههای نامتعادل
زمانی که دادههای آموزشی نامتعادل هستند، یعنی تعداد نمونهها در یک کلاس به مراتب بیشتر از کلاسهای دیگر است، SVM ممکن است به سمت کلاس با تعداد نمونه بیشتر سوگیری پیدا کند. این مسئله میتواند منجر به تشخیص نادرست کلاسهای با تعداد نمونه کمتر شود.
محاسبات سنگین
اگرچه SVM در مجموعه دادههایی با ابعاد متوسط به خوبی کار میکند، اما با افزایش تعداد ویژگیها و نمونهها، زمان آموزش مدل به شدت افزایش مییابد. این مسئله باعث میشود که استفاده از SVM در دادههای بزرگ و پیچیده به لحاظ محاسباتی ناکارآمد باشد.
تنظیم پارامترها
تعیین پارامترهای مناسب برای SVM میتواند چالشبرانگیز باشد. پارامترهایی مانند C (هزینه خطا) و پارامترهای کرنل باید به دقت تنظیم شوند تا از بیشبرازش (Overfitting) یا زیربرازش (Underfitting) جلوگیری شود.
تفسیرپذیری
در حالی که SVM میتواند الگوهای پیچیده را با دقت بالایی تشخیص دهد، اما تفسیر مدلهای تولید شده توسط آن میتواند دشوار باشد. این مسئله به ویژه در مواردی که از کرنلهای پیچیده استفاده شده است، بیشتر خود را نشان میدهد.
قسمتی از جزوه کلاس برای آموزش الگوریتم SVM
دوره جامع دیتا ساینس و ماشین لرنینگ

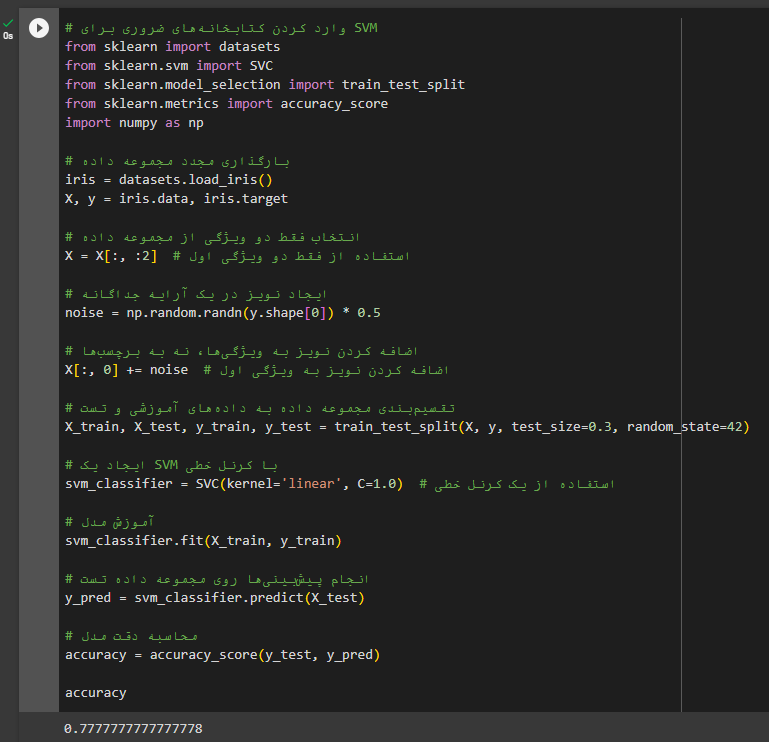
قطعه کد الگوریتم ماشین بردار پشتیبان
پارامترهای ورودی کد SVM
پارامترهای SVM تنظیمات مدل را کنترل میکنند و شامل تنظیماتی برای کرنل (مانند نوع کرنل و پارامترهای مربوط به آن)، مقدار C که نرخ خطای طبقهبندی را کنترل میکند، و پارامتر گاما برای کرنل RBF که تعیین میکند تا چه اندازه یک نمونه تکی میتواند تأثیر بگذارد، هستند. این پارامترها باید با دقت انتخاب شوند تا مدل نهایی بالاترین دقت و عمومیتپذیری را داشته باشد.
کد SVM
برای تمرین و آشنایی بیشتر با این الگوریتم، شما میتوانید کد زیر را در گوگل Colab اجرا کنید.
جمعبندی دربارهی ماشین بردار پشتیبان (Support Vector Machine)
در این مطلب سعی کردیم الگوریتم ماشین بردار پشتیبان (Support Vector Machines) را که بهاختصار به آن SVM گفته میشود بهصورت کوتاه و روشن توضیح دهیم. همانطور که اشاره کردیم، ماشین بردار پشتیبان یک الگوریتم یادگیری ماشین با ناظر (Supervised) است.
برای آشنایی با الگوریتم یادگیری ماشین با ناظر مطلب یادگیری با ناظر (Supervised Learning) را مطالعه کنید.
تدریستون فوق العاده بود. ممنون و خداقوت
سلام و عرض ادب،
خوشحالیم که مطلب براتون مفید بوده و رضایت شما رو جلب کرده.
کاربرد: در تشخیص بیماری ها
جهت طبقه بندی داده های با مشخصات زیاد و تعداد کم
هایپرپلین خط یا صفحهای است که دادهها را به دو یا چند دسته تقسیم میکند و باید بزرگترین حاشیه را داشته باشد.
پاسخ مختصر، مفید و درستی هست. ممنون از شما
یکی از کاربردهای ماشین بردار پشتیبان را نام ببرید.
مطالعات زمینشناسی: استفاده از SVM برای تعیین ساختارهای زیرزمینی.
ماشین بردار پشتیبان (SVM) برای چه منظوری استفاده میشود؟
ماشین بردار پشتیبان یا Support Vector Machine که بهاختصار به آن SVM گفته میشود یک الگوریتم یادگیری ماشین با ناظر است که نمونهی دادههایی را بهصورتی نقاطی در فضا نشان داده شده است، با استفاده از یک خط یا هایپرپلین (Hyperplane)، از هم جدا میکند. این جداسازی بهگونهای است که نقاط دادهای که در یک طرف خط هستند مشابهبههم و در یک گروه قرار میگیرند. نمونهدادههای جدید هم بعد از اضافهشدن به همان فضا در یکی از دستههای موجود قرار خواهند گرفت.
سوال ۳:
SVMالگوریتم یادگیری ماشین با ناظر است که نمونهی دادههایی را بهصورتی نقاطی در فضا نشان داده شده است، با استفاده از یک خط یا هایپرپلین (Hyperplane)، از هم جدا میکند. این جداسازی بهگونهای است که نقاط دادهای که در یک طرف خط هستند مشابهبههم و در یک گروه قرار میگیرند
سوال ۲:
ماشین بردار پشتیبان بهاختصار SVM یک مدل یادگیری ماشین با ناظر است که با توجه به دادههای برچسبدار آموزشی یک هایپرپلین بهینه را ارائه میکند تا دادههای جدید را به دستههای مختلف طبقهبندی کند.ـ
svm
یک الگوریتم یادگیری ماشین با ناظر است که نمونهی دادههایی را بهصورتی نقاطی در فضا نشان داده شده است، با استفاده از یک خط یا هایپرپلین (Hyperplane)، از هم جدا میکند. این
سوال۱:
تشخیص حالت چهره: کاربرد در تشخیص و طبقهبندی حالات چهره در تصاویر.
چقدرخوب توضیح دادین
ممنون
ممنون از توجه شما
خیلی ساده و روان . ممنون از سایت خوبتون
ممنون از توجه شما
خیلی عالی و ساده توضیح دادید. سپاسگزارم
ممنونم
خیلی عالیه توضیح دادید، یه دنیا ممنون
ممنون از لطف شما.
بهترین کتابی که میتونید در این زمینه معرفی کنید چه کتابی هست؟؟؟؟
وارد کانال تلگراممون بشید، اونجا کتابهای زیادی در زمینهی یادگیری ماشین معرفی کردیم. البته کتابهای خوب معمولا انگلیسی زبان هستن :https://t.me/DSLanders
سلام؛ عالی بود. میشه پایه ی برنامه نویسی رو یاد بدین یا منبع خوب معرفی کنید. ممنون.
سلام، ویدیوی مقدمات پایتون در این صفحه در بخش ویدیوهای آموزشی میتونه شروع خوبی باشه: https://cafetadris.com/datascience
این مقاله خیلی به کارم اومد. واقعا بی حد و مرز ممنونم
ممنون از اشتراک نظرتون.
برای مهاجرت بازار کار علم داده خوبه؟؟
بله، قطعا. در کشورهای دیگه علمداده تقاضای خیلی بالایی داره و اگه مهارتش رو داشته باشین، مسیر خوبیه.
سلام میشه یه ویدیو کامل بزارین قبل از یادگیری ماشین لرنینگ
باید چه کار هایی انجام بدیم سیستم مورد نیاز چقدر و….
سلام، در این مورد تو وبینارهای علمداده بسیار صحبت کردیم، پیشنهاد میکنم وارد این صفحه بشین و در بخش ویدیوهای آموزشی وبینارها رو مشاهده کنین:https://cafetadris.com/datascience
استاد الان باید از کجا آموزش پایتون رو شروع کنم دوره پیشنهادی دارید؟
به زودی کافهتدریس دوره پایتون رو هم اضافه میکنه به دورههاش. میتونین تا شروع دوره وارد لینک زیر بشین و در بخش ویدیوهای آموزشی ویدیوی مقدمات پایتون رو ببینین: https://cafetadris.com/datascience
سلام ممنون بابت این اطلاعات. به زبان ساده و روان . راجع به پایتون هم مقاله بذارید
سلام، دربارهی پایتون مقاله داریم، لطفا به این لینک مراجعه کنید: http://ctdrs.ir/ds0050
سلام وتشکر از مطلب مفیدی که به اشتراک گذاشتین
ممنون از توجه شما