
دپارتمان دیتا ساینس کافه تدریس از سال ۱۴۰۰ آغاز به کار کرده است. رضا شکرزاد، مدرس دورههای دیتا ساینس و ماشین لرنینگ دپارتمان دیتا ساینس کافه تدریس است که بیش از ۱۲ سال تجربه تدریس ریاضیات عمومی دانشجویان فنی و مهندسی را دارد. ایشان پس از اتمام تحصیلات کارشناسی در رشته مهندسی نرمافزار از دانشگاه تهران، دو مدرک کارشناسی ارشد خود را در رشتههای مهندسی صنایع از دانشگاه شریف و علم داده از دانشگاه رادبود هلند اخذ کرد. همچنین تجربه حضور در شرکت هنکل هلند بهعنوان مهندس ماشین لرنینگ را نیز در کارنامه دارد. هدف اصلی کافه تدریس کمک به دانشجویانی است که در حوزههای علمی و پژوهشی گام میگذارند و قصد دارند به موفقیتهای آکادمیک در این زمینهها دست یابند. عملکرد دپارتمان دیتا ساینس کافه تدریس نیز در همین راستاست؛ ما تلاش کردهایم که از روشهای مختلفی مانند برگزاری کلاسهای آنلاین، وبینارها و مشاورههای رایگان و ورکشاپهای مختلف دانشجویان را از نظر علمی و مهارتی بهروز نگه دارد.
- 1. بلاگ
- 2. کانالهای تلگرامی
- 3. کانال یوتیوب
- 4. وبینارهای رایگان
- 5. دوره جامع دیتا ساینس و ماشین لرنینگ کافه تدریس
- 6. کلام آخر
-
7.
پرسشهای متداول
- 7.1. دوره دیتا ساینس کافه تدریس برای چه کسانی مناسب است؟
- 7.2. آیا نیاز به پیشزمینه خاصی برای شرکت در دورههای کافه تدریس وجود دارد؟
- 7.3. چگونه میتوانم در دورههای آنلاین کافه تدریس شرکت کنم؟
- 7.4. بعد از شرکت در دوره چطور میتوانم مطمئن شوم بهخوبی مطالب را یاد بگیرم و میتوانم آنها را بهکار ببندم؟
- 7.5. آیا پس از اتمام دوره، مدرک معتبری دریافت میکنم؟
- 8. یادگیری تحلیل داده را از امروز شروع کنید!
بلاگ
یکی دیگر از خدمات کافه تدریس در حوزه دیتا ساینس مطالب تخصصی مربوط به این حوزه است که محتوای آن را جمعی از دانشجویان همین مجموعه تولید میکنند. هدف این وبلاگ ارائه اطلاعات جامع و بهروز در زمینههایی مانند هوش مصنوعی، یادگیری ماشین، تحلیل دادهها و ابزارهای پیشرفته این حوزه است. تیم نویسندگان، ازجمله مهسا مژدهی، زهرا رحیمیان، عباس سیفالسادات، سمیرا علیپور و مبینا پولایی، تلاش میکنند تا با پوشش حداکثری این مطالب، ارزشمندترین اطلاعات را در اختیار شما عزیزان قرار دهند.
این وبلاگ یکی از منابع جامع و تخصصی برای علاقهمندان به این حوزه است. مقالات موجود در این وبلاگ بهشکلی تدوین شدهاند که هم برای مبتدیان و هم برای متخصصان قابل استفاده باشند. ما تلاش میکنیم تا با ارائه مقالات آموزشی، راهنماییها و تحلیلهای دقیق، به خوانندگان کمک کنیم تا دانش خود را در زمینه دیتا ساینس و ماشین لرنینگ افزایش دهند.
یکی از ویژگیهای منحصربهفرد وبلاگ ما این است که تمامی مقالات را اعضای تیم کافه تدریس نوشتهاند و براساس تجربهها و مطالعات عملی آنان است. این موضوع باعث میشود تا مطالب بهشکل کاربردی و با مثالهای واقعی ارائه شوند که برای خوانندگان بسیار مفید و آموزنده خواهد بود.
علاوه بر مقالات، وبلاگ دیتا ساینس کافهتدریس نقد و بررسی آخرین تکنولوژیها و ابزارهای مورداستفاده در علم داده و یادگیری ماشین را هم در بر میگیرد. این نقدها و بررسیها به شما کمک میکند تا بهترین ابزارها و روشها را برای نیازهای خود انتخاب کنند.
همچنین ما در وبلاگ کافه تدریس به بهروزبودن مطالب اهمیت ویژهای میدهیم و همواره تلاش میکنیم تا با ارائه جدیدترین و کاربردیترین مطالب، نیازهای علمی و آموزشی کاربران خود را برآورده کنیم.
شما میتوانید ازطریق بخش نظرات و ارتباط با نویسندگان، سوالات و نظرات خود را مطرح کنند و پاسخهای دقیق و کاربردی دریافت کنند.
کانالهای تلگرامی
«DSLanders | دیاس لندرز» کانال تلگرامی کافهتدریس است. کانال دیاسلندرز با نظارت مستقیم رضا شکرزاد توسط زهرا رحیمیان و با هدف بهروزنگهداشتن اطلاعات دانشجویان تولید محتوا میکند. این کانال با هدف آموزش و گسترش دانش علم داده برای همه افراد، صرفنظر از رشته تحصیلی آنها، راهاندازی شده است. پستهای این کانال معرفی مقالههای علمی، منابع آموزشی، نقشهراههای یادگیری و اخبار بهروز حوزه علم داده را در بر میگیرد. همچنین، این کانال ابزارها و تکنیکهای پیشرفته در علم داده را بررسی میکند و منابع معتبری را برای مطالعه عمیقتر در اختیار کاربران قرار میدهد.
در کنار این کانال تلگرامی، کانال تلگرامی «آموزش دیتاساینس و ماشین لرنینگ» با هدف آموزش دقیق مطالب مربوط به حوزه علم داده راهاندازی شده است. یکی از ویژگیهای منحصربهفرد این کانال قراردادن آزمونهای مختلف متناسب با مطالب آموزشداده شده است. این کوییزها به کاربران کمک میکند تا مفاهیمی را که در همین کانال یاد گرفتهاند ارزیابی و تقویت کنند.
با شرکت در این کوییزها، اعضای کانال میتوانند دانش خود را محک بزنند و نقاط ضعف و قوت خود را شناسایی کنند. از دیگر مزیتهای این کانال ارائه منابع آموزشی بهصورت متنی، تصویری و ویدئویی است که یادگیری مباحث مختلف را برای کاربران آسان میکند؛ علاوهبراین، معرفی کتابهای تخصصی، ابزارهای نوین و نرمافزارهای کاربردی نیز از دیگر بخشهای جذاب این کانال است.
اگر به دنبال یادگیری عمیق و عملی علم داده و یادگیری ماشین هستید یا میخواهید دانش خود را در این زمینه طریق تقویت کنید، کانال آموزش دیتا ساینس کافه تدریس گزینهای بسیار مناسب برای شماست.
کانال یوتیوب
علاوه بر موارد گفتهشده، کانال یوتیوب رضا شکرزاد منبعی عالی برای یادگیری مفاهیم علم داده و یادگیری ماشین به زبان فارسی است. در این کانال یوتیوبی شما میتوانید به ویدئوهایی در زمینههای مختلف از مبانی اولیه تا موضوعات پیشرفته حوزه دیتا ساینس و ماشین لرنینگ دسترسی پیدا کنید. هر ویدئو توضیحات دقیق و مثالهای عملی را شامل میشود که به شما کمک میکند تا مفاهیم پیچیده این حوزه را بهراحتی درک کنید و در پروژههای عملی به کار بگیرید.
رضا شکرزاد در این کانال جدیدترین مقالات و فناوریها را بررسی میکند. این اطلاعات به شما کمک میکند تا دانش خود را بهروز نگه دارید و در حوزههای مختلف علم داده پیشرو باشید.
وبینارهای رایگان
ما در مجموعه کافه تدریس، برای تکمیل منابع آموزشی و ارتقا سطح دانشجویان در حوزه علم داده و یادگیری ماشین، مجموعهای از وبینارهای ارزشمند را تهیه کردهایم. این وبینارها بهگونهای طراحی شدهاند که نیازهای آموزشی شما را از سطح مبتدی تا پیشرفته پوشش دهند.
رضا شکرزاد این وبینارها را ارائه میکنند و به شما کمک میکنند تا درک بهتری از روندهای جاری و آینده حوزه علم داده داشته باشید و بتوانید بهبهترین نحو در مسیر شغلی خود قدم بردارید.
با استفاده از این وبینارهای رایگان میتوانید دانش خود را بهروز نگه دارید و در مسیر پیشرفت علمی و حرفهای خود گامهای موثری بردارید.
پلیلیست کامل این وبینارها را در این لینک پیدا کنید.
دوره جامع دیتا ساینس و ماشین لرنینگ کافه تدریس
در ادامه برای یادگیری دقیق و اصولی علم داده ما به شما دوره جامع علم داده رضا شکرزاد را معرفی میکنیم که در ان تمامی مطالب این حوزه از مفاهیم پایه تا مباحث پیشرفته، هم بهصورت تئوری و هم عملی، پوشش داده میشود. چیزی که این دوره را از دیگر دورههای مشابه متمایز میکند تدریس عمیق و مفهومی مبانی ریاضیاتی و آماری پشت تمامی مدلهای یادگیری ماشین و یادگیری عمیق پیش از آموزش کاربردی آنهاست.
توانایی بالای رضا شکرزاد در بیان این مطالب به تجربه دوازدهساله او در تدریس ریاضیات دانشجویان فنی و مهندسی برمیگردد. بهلطف این پیشینه قوی، تمای مطالب و پیشنیازهای لازم برای درک درست و اصولی نحوه کارکرد مدلهای یادگیری ماشین را بهبهترین شکل ارائه میدهد.
داشتن این درک درست به شما کمک میکند که بهترین مدلها را برای مسئله خود انتخاب و سریعتر راهحلهای بهینه را برای رفع مشکلات احتمالی حین آموزشدادن این مدلها پیدا کنید.
در این جدول میتوانید بهطور خلاصه مباحثی را که در این دوره تدریس میشود ببینید:
| دسته بندی | زیر گروه | مدلها | تئوریها | پکیجهای پایتون |
| یادگیری با نظارت (Supervised Learning) | رگرسیون (Regression) | رگرسیون خطی (Linear Regression)، رگرسیون ریج (Ridge) و رگرسیون لاسو (Lasso) | گرادیان کاهشی، بهینههای محلی، معادله نرمال، بایاس و واریانس توابع هزینه MSE و SSE و MAE و RMSE و … معیار ارزیابی R2 Score | Sklearn ,Pandas ,Numpy ,Scipy ,Matplotlib Seaborn |
| طبقهبندی (Classification) | رگرسیون لجستیک (Logistic Regression)، نزدیکترین همسایه (KNN)، ماشین بردار پشتیبان (SVM)، بیز ساده (NB)، درخت تصمیم (DT)، جنگل تصادفی (RF) | تابع سیگموید، مرز تصمیمگیری، فاصلههای اقلیدسی و منهتن، الگوریتم K-D Tree، مسئله بهینهسازی، تابع دوگان، شروط Karush–Kuhn–Tucker، توابع کرنل، Soft Margin و Hard Margin، احتمال شرطی، قضیه بیز و احتمال کل، آنتروپی، ضریب جینی، بهره اطلاعاتی (Information gain)، الگوریتم CART توابع هزینه Binary/Categorical Cross Entropy معیارهای ارزیابی Accuracy, Precision, Recall AUC/ROC, F1-score, Confusion matrix | ||
| یادگیری بدون نظارت (Unsupervised Learning) | خوشهبندی (Clustering) | K-means, DBscan, Agglomerative | فاصله میندوسکی معیارهای ارزیابی Inertia, Silhouette score | |
| تشخیص ناهنجاری (Anomaly detection) | Isolation forest, Local outlier factor, Elliptic Envelope, One-Class support vector machine | معیار ارزیابی F1-score | ||
| کاهش بعد (Dimensionality reduction) | PCA, t-SNE, Umap | مقدار ویژه، بردار ویژه، ماتریس کوواریانس، تجزیه مقادیر منفرد (SVD) | ||
| سیستم های توصیه گر (Recommender Systems) | Content-based filtering, Collaborative filtering, Hybrid method | فاصله کسینوسی، تجزیه ماتریس | ||
| ANNs | MLP | گرادیان کاهشی، مشتق زنجیرهای، پسانتشار، محوشدگی گرادیان، بهروزرسانی نرخ یادگیری توابع فعالساز (Sigmoid, Softmax, ReLu, Gelu, Selu, Tanh)، بهینهسازها (SGD, Momentum, Rmsprop, AdaGrad, Aadam) توابع هزینه MSE, Cross Entropy و … معیارهای ارزیابی امتیاز R2 Score, Accuracy | ,Tensorflow (Keras) PyTorch | |
| CNNs | AlexNet, VGGNet, ResNet, DenseNet, MobileNet, SqueezeNet, EfficientNet, GoogleNet (Inception) | یادگیری انتقالی، شمارش هایپر پارامترها ,Pooling, Padding Conv1D, 2D, 3D, توابع هزینه MSE, Cross Entropy و … | ||
| RNNs | RNN, LSTM, GRU, Bidirectional RNN | |||
| Transformers | Positional embedding, Multihead attention Scaled score matrix | |||
| RAG | ||||
| Computer Vision | Object Detection | R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN, RetinaNet, YOLO | جستجوی انتخابی، RoI pooling شبکه ناحیه پیشنهادی یا RPN Grid cell، Anchor Box توابع هزینه Bounding Box Regressor, Categorical Cross Entropy, … معیار ارزیابی IoU | |
| Image Segmentation | U-Net | Skip-connection ConvTranspose, Upsampling, Unpooling,… Categorical Cross Entropy تابع هزینه | ||
| VAEs | beta VAE, Conditional VAE | Encoder-Decoder, فضای پنهان توابع هزینه ,Reconstruction loss Kullback-Leibler معیار ارزیابی IoU | ||
| GANs | Cycle GAN, Conditional GAN, Style translation, DCGAN | Generator, Discriminator Binary Cross Entropy تابع هزینه | ||
| NLP | Word Embedding | BOW, One-Hot Encoding, Tf/idf, Word2vec, GloVe, Fasttext | Cbow, Skip-gram | ,Gensim, NLTK ,Tensorflow (Keras) PyTorch, Sklearn |
| Sentiment Analysis | ||||
| Text Classification | ||||
| LLMs | BERT, GPT, ELMo | NSP, MLM معیار ارزیابی Bleu | Hugging face | |
| ASR | End-to-End Speech Recognition | Speech Transformers | LJSpeech Dataset, TIMIT dataset, TTS, Voice-Activated Assistants, Audio Compression, Fourier Transform | ,Wave ,Pydub ,Pyaudio ,Librosa Speechrecognition |
یادگیری ماشین
همانطور که در جدول بالا مشخص است، در بخش مربوط به مباحث یادگیری ماشین این دوره، مباحث رگرسیون، کلسیفیکیشن، کلاسترینگ و غیره تدریس میشود که در ادامه به ترتیب نحوه تدریس آنها را بررسی میکنیم:
رگرسیون
برای تدریس مبحث مهم و پایهای رگرسیون، رضا شکرزاد ضمن تدریس شیوههای حل یک مسئله رگرسیون اعم از گرادیان کاهشی و معادله نرمال، نحوه بهروزرسانی وزنها بهکمک بهینهسازی تابع هزینه را در هر یک از این روشها برای رسیدن به بهترین خط رگرسیون بیان میکنند:
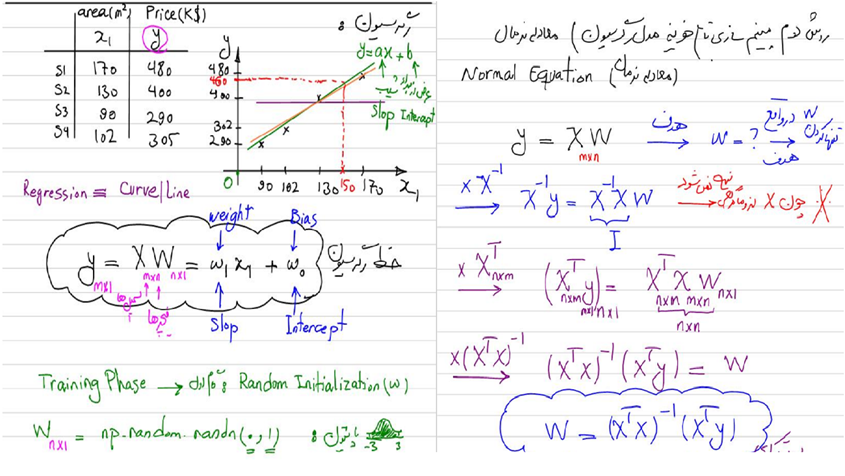
بعد از تدریس این مفاهیم، نوبت به استفاده از آنها در پروژههای واقعی میرسد. رضا شکرزاد پروژههای متعددی را در طول دوره با استفاده از مدلهای رگرسیون پیادهسازی میکند.
یکی از ابتداییترین آنها پروژه پیشبینی قیمت خانه در مجموعه داده بوستون است. برای استفاده از مدلهای رگرسیون چندجملهای نیز از یک مجموعه داده برای پیشبینی حقوق کارمندان باتوجه به تجربه کاریشان استفاده میشود.
در تمامی این پروژهها نحوه صحیح پیشپردازش و رسم نمودارهای مختلف برای تحلیل اکتشافی دادهها (EDA) آموش داده میشود؛ بهاین ترتیب، از همان جلسات ابتدایی دوره، شما قادر خواهید بود با یک دید کامل از تئوری و کاربرد، پروژههای مختلفی در این حوزه اجرا کنید.
طبقهبندی
در این دوره برای تدریس مبحث طبقهبندی یا همان کلسیفیکیشن، ابتدا مثال ساده طبقهبندی دوکلاسی بههمراه تابع سیگموید و نحوه مدلسازی آن تدریس میشود و ضمن بیان دلیل استفاده از تابع هزینه کراس انتروپی برای این مسئله، نحوه بهینهسازی آن هم بررسی میشود:
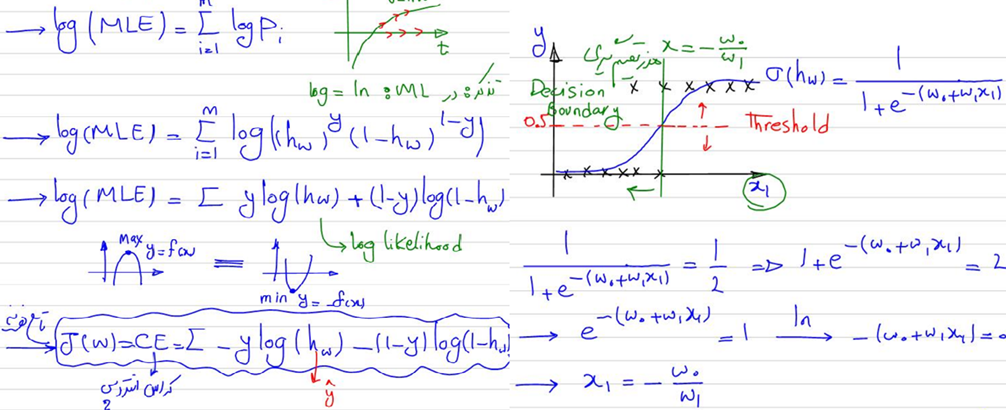
دیگر الگوریتمهای طبقهبندی نیز بههمین ترتیب و با جزئیات کامل در این دوره تدریس میشود؛ برای مثال، در مبحث KNN، الگوریتم این مدل و توابع محاسبه فاصله مختلف برای دانشجویان توضیح داده میشود:

جزئیات مربوط به تدریس دیگر الگوریتمهای کلسیفیکیشن و نیز معیارهای ارزیابی آن در این دوره، بهطور خلاصه، در جدول بالا آمده است.
برای بهکاربستن آنچه در مبحث طبقهبندی تدریس شده است، رضا شکرزاد پروژههای مختلفی را اعم از پیشبینی احتمال ابتلا به سرطان سینه، تشخیص ارقام دستنوشت مجموعهداده هدی و MNIST، پیشبینی زندهماندن مسافران کشتی تایتانیک، تشخیص اسپمبودن یا نبودن یک ایمیل و چندین پروژه دیگر در کلاس پیادهسازی میکنند.
علاوه بر این پروژها، در بسیاری از مباحث، سعی شده است الگوریتمهای گفتهشده از ابتدا (From Scratch) پیادهسازی شود تا درک بهتر و عمیقتری از آنچه پشت جعبهسیاه (Black Box) الگوریتمهای ماشین لرنینگ اتفاق میافتد پیدا کنید.
خوشهبندی
یکی دیگر از مهمترین مباحث ماشین لرنینگ الگوریتمهای بدون نظارت هستند. رضا شکرزاد در دپارتمان دیتا ساینس کافه تدریس این مباحث را نیز با جزئیات تدریس میکنند؛ برای مثال در تدریس الگوریتم K-means، علاوه بر تدریس شیوه کارکرد الگوریتم، درباره مرتبه زمانی و نیز تابع هدف آن بحث میشود:
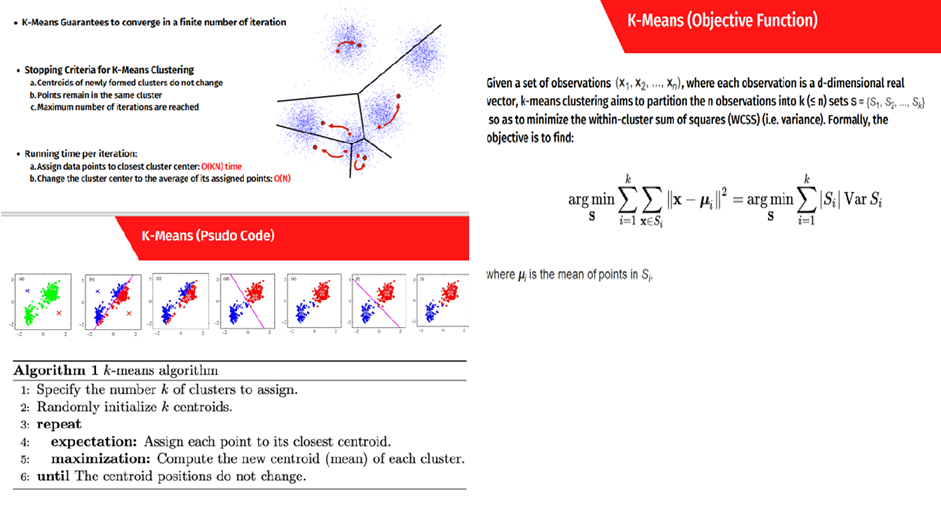
مانند مباحث قبلی، در بخش خوشهبندی نیز رضا شکرزاد پروژههای متعددی را در کلاس اجرا میکند که یکی از آنها، خوشهبندی مشتریان یک مرکز خرید است که با تمامی مدلهای گفتهشده پیادهسازی و نتایج آنها مقایسه میشود.
یادگیری عمیق
یکی از مهمترین بخشهای کلاس علم داده رضا شکرزاد تدریس مباحث مربوط به شبکههای عصبی است. در این دوره ضمن تدریس مبانی ریاضیاتی مانند مشتق زنجیرهای، عملیات پسانتشار و گرادیان کاهشی، تمامی نکات مربوط به بهروزرسانی وزن نودها در شبکههای عصبی بررسی و توضیح داده میشود؛ همچنین برای درک بهتر این فرایند، با ارائه یک مثال، بهطور دقیق چگونگی بهروزرسانی وزن نودهای یک شبکه MLP فرضی با عملیات مشتقگیری از تابع هزینه و پسانتشار تدریس میشود:

در جلسههای ورکشاپ این مبحث، هر دو روش ساخت شبکه عصبی Functional و Sequential آموزش داده و نحوه ساخت مدل برای هر دو تسک رگرسیون و کلسیفیکیشن بهصورت عملی تدریس میشود.
شبکههای عصبی کانولوشنی
یکی دیگر از قسمتهای متفاوت کلاس رضا شکرزاد، در مقایسه با دیگر دورههای علم داده، مربوط به شبکههای عصبی کانولوشنی است. برای تدریس این مبحث چگونگی اعمال فیلترهای مختلف کانولوشنی روی عکسهای ورودی با جزئیات کامل بیان میشود؛ همچنین نحوه شمارش تعداد هایپرپارامترهای شبکه باتوجه به ابعاد فیلتر و تعداد کانالهای آن آموزش داده میشود:
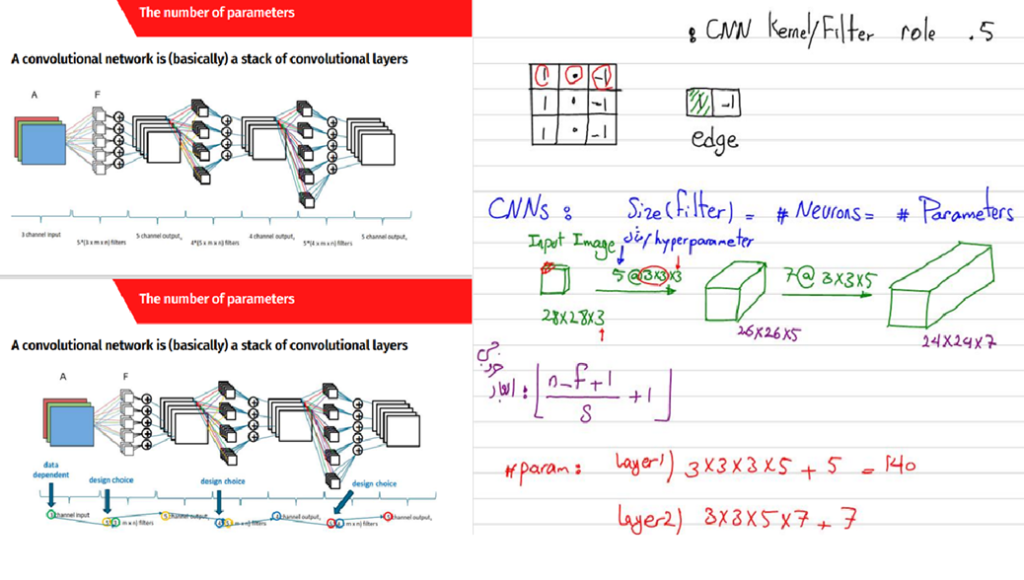
در ورکشاپ شبکههای عصبی کانولوشنی رضا شکرزاد، ضمن آموزش نحوه ساخت یک شبکه مناسب برای طبقهبندی مجموعهداده ImageNet، یک نوتبوک تمرینی برای امتحانکردن تأثیر تغییر هر یک از این لایهها در اختیار دانشجویان قرار داده است و از آنها میخواهد با تجربهکردن حالتهای مختلف ساخت شبکه عصبی، بهترین خروجی ممکن را از نظر دقت طبقهبندی بهدست آورند.
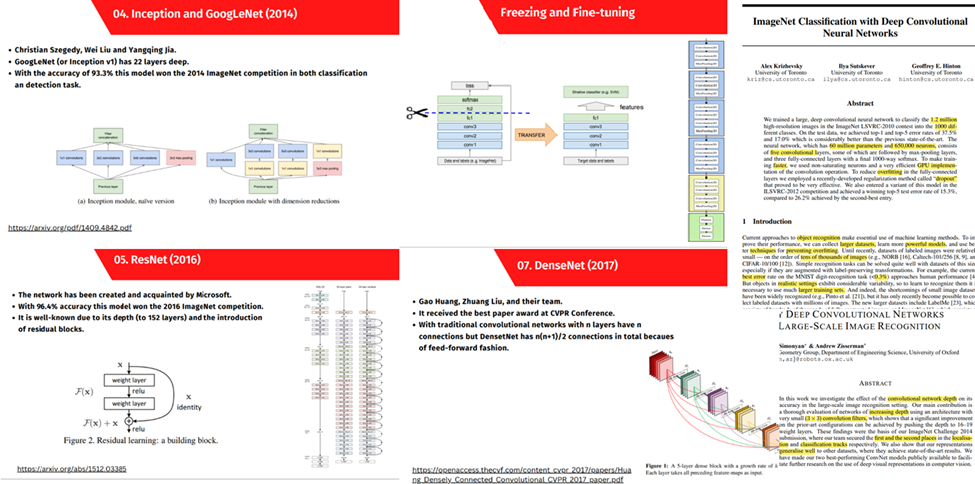
شبکههای عصبی معروف و یادگیری انتقالی
در این دوره، ضمن تدریس معماری تمامی شبکههای عصبی معروف، نحوه تنظیمکردن آنها برای استفاده در پروژهای دیگر و نیز ایدههای مهم هر یک که میتوان در شبکههای دیگر استفاده کرد بیان میشود.
یکی از ویژگیهای منحصربهفرد دوره علم داده رضا شکرزاد بررسی دقیق و مفهومی مقالات علمی هر یک از این مدلها است که ضمن انتقال نحوه تفکر درست درمورد حل مسائل مختلف این حوزه، به دانشجویان شیوه صحیح خواندن مقالات آکادمیک را نیز یاد میدهد:
شبکههای عصبی بازگشتی
یکی از مهمترین بخشهای دوره علم داده رضا شکرزاد شبکههای عصبی بازگشتی (RNNs) است. این شبکهها، بهدلیل قابلیت حفظ اطلاعات و استفاده از آنها در پردازش دادههای ترتیبی، کاربردهای فراوانی دارند.
در این دوره، ابتدا مفاهیم پایهای RNNها و ساختار سلولهای ساده آن (Vanilla) تدریس میشود. سپس مفاهیم پیشرفتهتری نظیر شبکههای عصبی بازگشتی عمیق (Deep RNN) و شبکههای عصبی بازگشتی دوطرفه (Bidirectional RNN) آموزش داده میشود.
در این جلسات از کلاس، روشهای پسانتشار از طریق زمان (BPTT) و برش گرادیان (Gradient Clipping) برای جلوگیری از ناپایداری گرادیانها (Gradient vanishing) حین فرایند آموزش (Training) نیز مطرح میشود. این روشها به دانشجویان کمک میکند تا مدلهای خود را بهبهترین نحو ممکن بهینهسازی کنند:
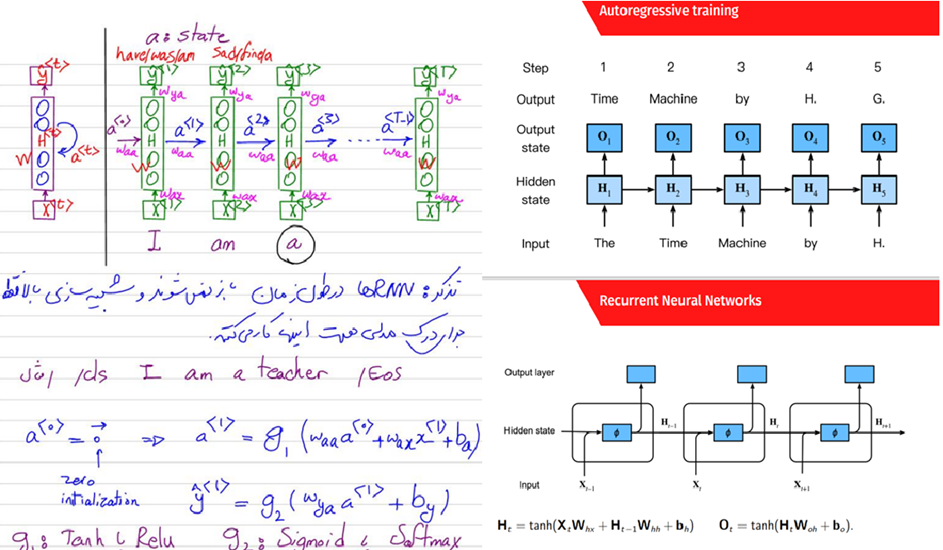
در کنار آموزش تئوریهای لازم پروژههای عملی تولید متن با استفاده از LSTMها نیز در کلاس پیادهسازی میشود. در این پروژه، دانشجویان با استفاده از شبکههای عصبی LSTM یاد میگیرند که چگونه یک مدل تولید متن بسازند. این مدلها قادرند با یادگیری الگوهای موجود در دادههای متنی، متون جدید و معناداری تولید کنند.
ترنسفورمرها
بهعنوان یکی از دانشجویان رضا شکرزاد در دپارتمان دیتا ساینس کافه تدریس میتوانم بگویم ترنسفورمرها یکی از شگفتانگیزترین قسمتها این دوره است. در یک بخش چنان با دقت و جزئیات با ایدهها و نحوه کار این مدل آشنا میشوید که مطمئنام با شرکت در هیچ دوره دیگری قادر به درک درست این سازوکار نخواهید بود. در جلسه مربوط به تدریس تئوری ترنسفورمرها، علاوه بر بررسی مقاله معروف Attention is all you need، از پایه مفاهیم و ریاضیات لازم برای درک این مدل به شما آموزش داده خواهد شد و دقیقا متوجه خواهید شد که در پس همه این مدلهای بزرگ زبانی (LLM) چه میگذرد.
از معماری انکدر و دیکدر یک ترنسفورمر گرفته تا مفهوم Positional Embedding و همچنین Multi head attention و ماتریسهای Key, Query, Value همگی در این جلسه به شما انتقال داده خواهد شد:
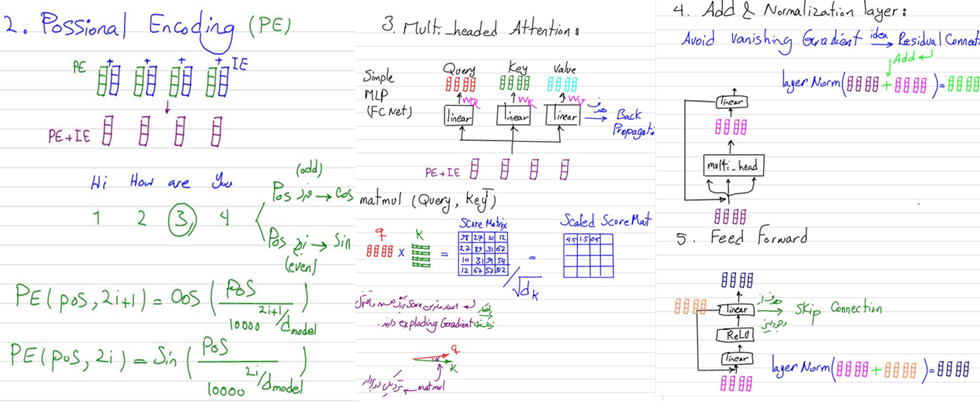
در جلسات ورکشاپ مربوط به ترنسفورمرها نیز پروژههای مختلفی در کلاس پیادهسازی شده است. یکی از این پروژهها پیادهسازی مدلهای ترجمه ماشینی با کمک ترنسفورمرهاست. در همین جلسهها شما نحوه کار با فریم ورک Hugging Face و نحوه استفاده از مدلهای مختلف آن را یاد میگیرید.
تشخیص اشیا
در جلسههای مربوط به تدریس مبحث تشخیص اشیا که یکی از مهمترین بخشهای بینایی کامپیوتر (Computer vision) است، رضا شکرزاد از پایهایترین مدلها که R-CNN باشد، تا پیچیدهترین آنها را که YOLO است تدریس میکند. تفاوت میان بخشبندی تصویر و انواع آن (مانند Semantic و Instance segmentation)، تشخیص اشیا و طبقهبندی تصاویر نیز در این جلسات بهطور کامل تبیین میشود.
همچنین تمامی الگوریتمهای بهکاررفته در این مدلها از جمله جستوجوی انتخابی (Selective Search)، مفهوم RoP، RoI pooling، شبکه پیشنهادی ناحیه (Region of Proposal Network یا RPN) و نحوه پیادهسازی آنها تدریس میشود. رضا شکرزاد در این بخش همه معیارهایی که میزان دقت این مدلها را ارزیابی خواهند کرد، مانند Intersection over Union، تدریس میکند و توابع هزینه هر یک بهخصوص مدل YOLO را بهتفضیل و با جزئیات توضیح میدهد:
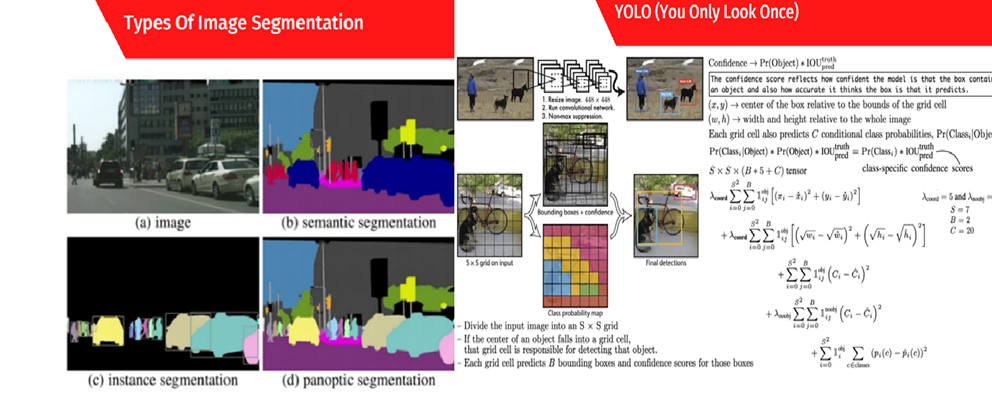
مانند مباحث قبلی، در این بخش از دوره علاوه بر آموزش تئوری، پروژههای عملی نیز اجرا میشود. یکی از پروژههای اصلی، پیادهسازی مدل YOLO برای تشخیص اشیا در مجموعهدادههای مختلف است که در آن دانشجویان یاد میگیرند چگونه با استفاده از فریمورکهای مختلف، مدلهای YOLO را پیادهسازی و بهینهسازی کنند.
بخشبندی تصویر
مبحث بخشبندی تصویر (Image Segmentation) نیز در دوره علم داده بهطور کامل پوشش داده شده و رضا شکرزاد در این قسمت، ضمن بررسی مقاله اصلی، با جزئیات معماری معروف U-Net را بههمراه مفاهیمی چون Skip connection و ConvTranspose تدریس میکنند:
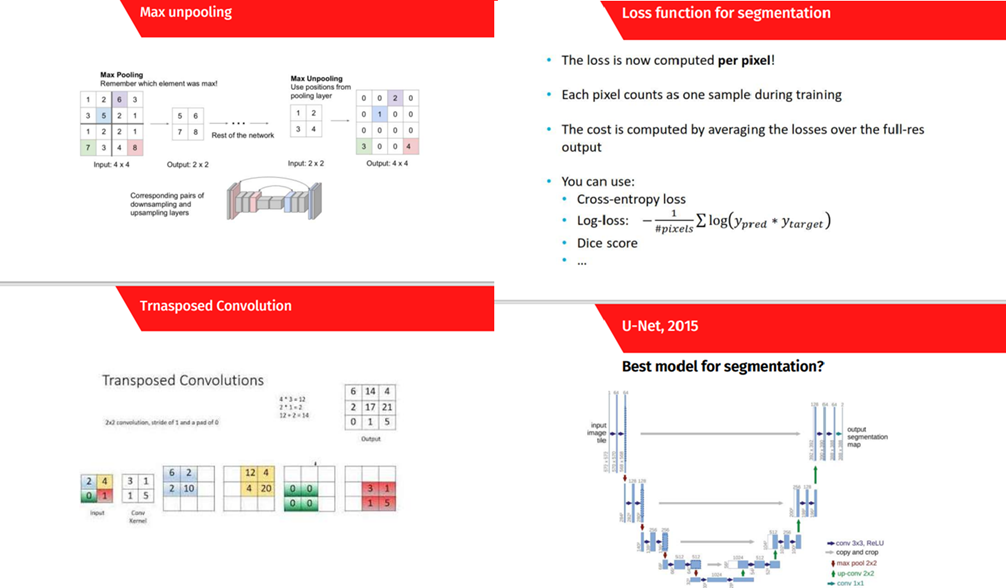
برای جلسههای ورکشاپ، در این دوره یک پروژه بخشبندی تصویر با معماری یونت اجرا شده و راههای افزایش دقت مدل برای آزمایش بیشتر به دانشجویان گفته شده است تا در صورت تمایل، خودشان کد فراهم شده را بهبود ببخشند.
اتوانکدرهای متغیر (VAEs)
اتوانکدرهای متغیر یا Variational Auto Encoders یکی دیگر از بخشهای پیشرفته این دوره علم داده محسوب میشود. این شبکهها بهدلیل تواناییشان در تولید دادههای جدید و مدلسازی توزیعهای پیچیده، کاربردهای فراوانی دارند. در این دوره، مفاهیم پایه تا پیشرفته VAEs آموزش داده میشود و مقاله betha VAEs و کاربردهای آن در کلاس بررسی میشود:
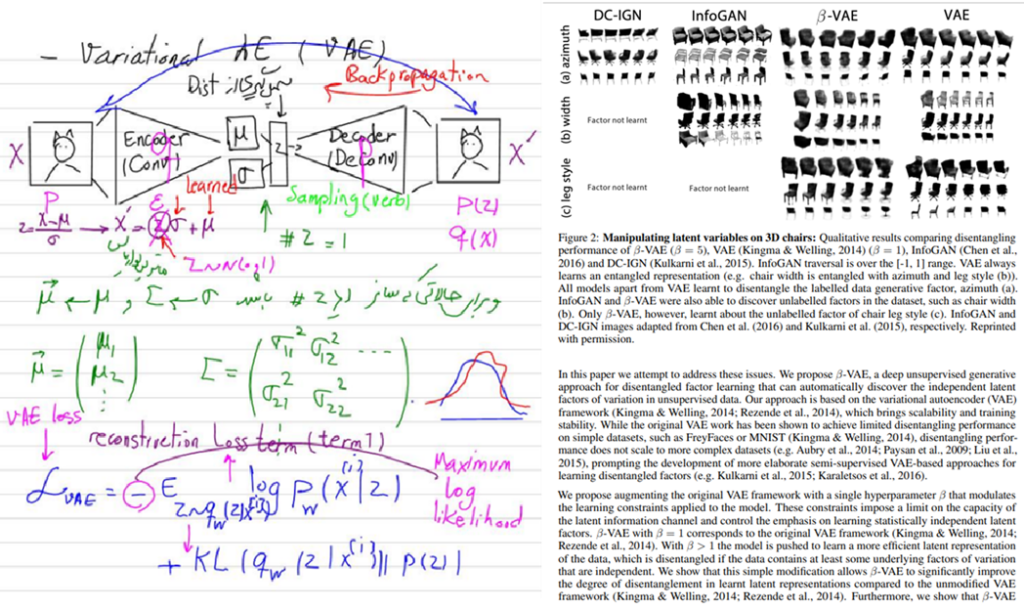
در جلسه ورکشاپ مربوط بهVAE ها، یک آموزش جامع برای درک و پیادهسازی این مدل با استفاده از مثالهای عملی ارائه میشود. در این جلسه مفاهیم کلیدی مانند فضای پنهان، معماری انکودر-دیکودر و نقش تابع هزینه KL در تنظیم توزیع یادگرفتهشده، مرور میشود و سپس، فرایند ساخت و آموزش یک مدل VAE با کمک PyTorch آموزش داده میشود.
پردازش متن
یکی دیگر از حوزههایی که با شرکت در این دوره در آن مهارت کسب میکنید، حوزه جذاب و کاربردی پردازش متن است. بخشهای مختلف کلاس که تدریس این مبحث در آنها مطرح میشود در ادامه آمده است:
تعبیه کلمات
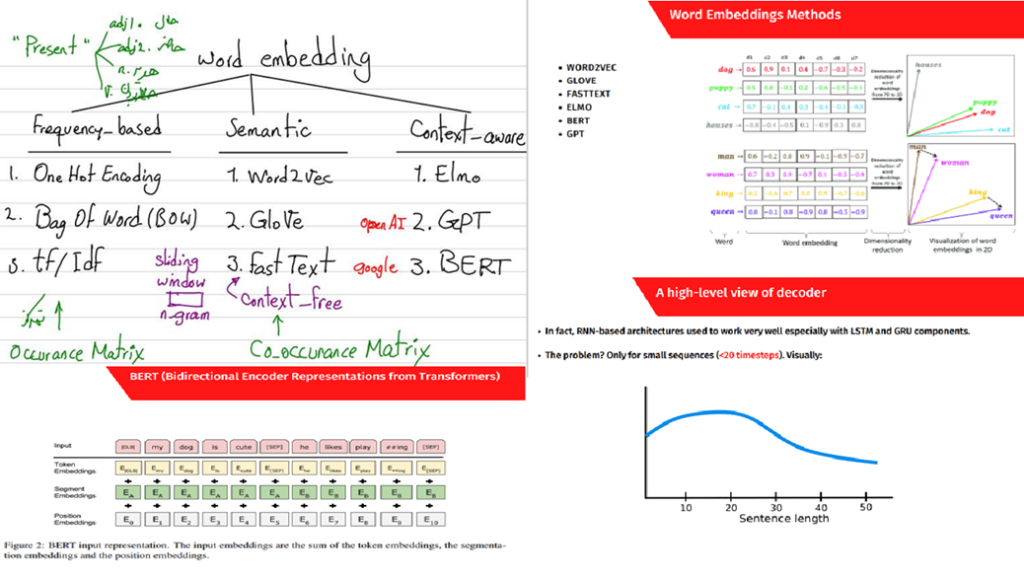
یکی از مباحث کلیدی در حوزه پردازش زبان طبیعی (NLP) که در دوره علم داده رضا شکرزاد تدریس میشود، تعبیه برداری کلمات (Word Embeddings) و انواع آن است. این روشها برای تبدیل کلمات به بردارهای عددی که بعضا روابط معنایی بین آنها را حفظ میکنند استفاده میشوند.
در این دوره روشهای مختلف تعبیه برداری لغات بهصورت تئوری و عملی آموزش داده میشود. در بخش تئوری، مفاهیم پایهای و مدلهای مختلف تعبیه برداری واژگان بحث میشوند.
Word2Vec
در کلاسها نحوه کار مدل Word2Vec تدریس میشود که یک مدل پیشبینی است که بهکمک یک شبکه عصبی، کلمات را به بردارهایی تبدیل میکند که کلمات با معانی مشابه در فضای برداری به یکدیگر نزدیک باشند. این مدل دو رویکرد اصلی دارد: Cbow و Skip-gram.
در روش CBOW (Continuous Bag of Words)، هدف پیشبینی کلمه هدف با توجه به کلمات زمینه است. در روش Skip-gram، هدف پیشبینی کلمات زمینه با توجه به کلمه هدف است. در کلاس نحوه کار هر دو این شبکهها به زبانی ساده و فهمیدنی برای دانشجویان توضیح داده میشود.
GloVe
یکی دیگر از مدلهایی که در کلاسهای علم داده رضا شکرزاد تدریس میشود، مدل GloVe است که بهکمک یک ماتریس هموقوعی، بردارهای کلمات را یاد میگیرد.
FastText
یکی دیگر از مدلهای تدریسشده در این دوره مدل FastText است که کلمهها را با پیشبینی کلمه بعدی در یک جمله یاد میگیرد. این مدل توانایی مدیریت کلمات خارج از واژگان (OOV) را با تجزیه آنها به زیرکلمات و سپس میانگینگیری تعبیههای آنها دارد.
مدلهای بزرگ زبانی
مدلهای BERT و GPT که از اصلیترین مدلهای بزرگ و معروف زبانی هستند در این دوره توسط رضا شکرزاد بهدقت و با جزئیات به دانشجویان دوره معرفی میشود. آموزش این مدلها به دانشجویان کمک میکنند تا درک عمیقی از چگونگی تعبیه برداری لغات و کاربرد آنها در مسئلههای مختلف پردازش زبان طبیعی پیدا کنند.
در این دوره با بررسی دقیق و مفهومی این مدلها و نحوه عملکرد آنها، دانشجویان برای پیادهسازی و استفاده عملی از این تکنیکها آماده میشوند:
مانند دیگر مباحث، پروژههای مرتبط با پردازش متن زیادی ازجمله Image Captioning، طبقهبندی متن و تحلیل احساس در جلسات ورکشاپ این قسمتها پیادهسازی میشود.
تشخیص گفتار خودکار
یکی از مباحث مهم و کاربردی در دوره علم داده رضا شکرزاد شناسایی گفتار خودکار (ASR) است. ASR تکنیکی است که گفتار انسان را به متن تبدیل میکند و کاربردهای فراوانی در تکنولوژیهای روزمره و صنعت دارد. در این دوره، مفاهیم پایهای ASR ازجمله تبدیل سیگنال گفتار به ویژگیها، نرخ نمونهبرداری (Sample Rate) تبدیل فوریه و … بهصورت جامع آموزش داده میشود:
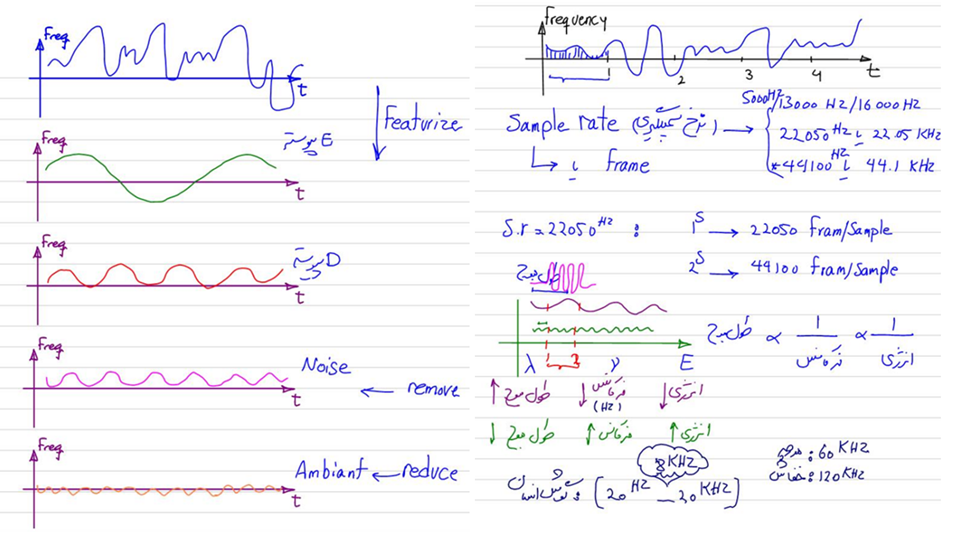
در جلسههای ورکشاپ مبحث صوت و تشخیص گفتار، پروژههای مختلفی ازجمله شناسایی جنسیت و استفاده از ترنسفورمرها در ASR پیادهسازی میشود. این پروژههای عملی به دانشجویان کمک میکند تا مفاهیم نظری را بهصورت عملی نیز تجربه و درک عمیقتری از نحوه کاربرد ASR در مسائل واقعی پیدا کنند.
کلام آخر
هدف مجموعه کافه تدریس همواره برقراری عدالت آموزشی و کمک به جوانان سراسر کشور برای دستیابی به امکانات کافی در مسیر رسیدن به آرزوهای تحصیلی و شغلیشان بوده است. دپارتمان دیتا ساینس کافه تدریس نیز از این قاعده مستثنا نیست و با همین رویکرد کار خود را آغاز کرده و تا امروز ادامه داده است.
کافه تدریس، با ارائه دورههای جامع و منابع آموزشی متنوع، به علاقهمندان به حوزه دیتا ساینس کمک میکند تا با درک عمیق و کاربردی از مفاهیم، به موفقیتهای علمی و حرفهای دست یابند. اگر به دنبال یادگیری دقیق و اصولی دیتا ساینس و ماشین لرنینگ هستید، از شما دعوت میکنیم به جامعه پویا و پرتلاش ما بپیوندید و با شرکت در دوره علم داده جامع کافه تدریس بهراحتی مسیر پرهیجان خود را در حوزه موردعلاقهتان دنبال کنید.

پرسشهای متداول
دوره دیتا ساینس کافه تدریس برای چه کسانی مناسب است؟
دوره دیتا ساینس کافه تدریس برای تمامی علاقهمندان به حوزه علم داده، اعم از دانشجویان و دانشآموختگان همه رشتهها طراحی شده است. این دورهها مفاهیم مقدماتی و پیشرفته را در بر میگیرند و برای افرادی مناسب است که به دنبال ارتقای مهارتهای خود در زمینه دیتا ساینس و ماشین لرنینگ هستند.
آیا نیاز به پیشزمینه خاصی برای شرکت در دورههای کافه تدریس وجود دارد؟
برای شرکت در دورههای مقدماتی دپارتمان دیتا ساینس کافه تدریس به پیشزمینه خاصی نیاز ندارید و این دورهها بهگونهای طراحی شدهاند که از مبانی پایه شروع میشوند.
بااینحال داشتن اطلاعات اولیه در زمینه ریاضیات و برنامهنویسی میتواند به درک بهتر مفاهیم کمک کند که برای این موضوع، حدود ۴۰ ساعت پیشنیاز برای این دوره در اختیار شرکتکنندگان قرار داده میشود.
در یکی از مهمترین بخشهای این پیشنیازها، مبانی زبان برنامهنویسی پایتون تدریس شده است که زبان اصلی امروز دنیای هوش مصنوعی به شمار میرود؛ همچنین در راستای تقویت مهارت برنامهنویسی دانشجویان، رضا شکرزاد یک گروه جداگانه تشکیل داده که مدیریت آن با خانم مهدیه مرتضوی است و در این جمع شما بهطور هفتگی تعدادی از مسئلههای وبسایت LeetCode را حل میکند که خود استاد مشخص میکند. در پایان هفته در یک دورهمی آنلاین نکتههای مربوط به این تمرینها بررسی میشود. شایان ذکر است که بعد از تهیه دوره، میتوانید در این جمع نیز حضور پیدا کنید و به پرداخت هزینه جداگانهای نیاز نیست.
چگونه میتوانم در دورههای آنلاین کافه تدریس شرکت کنم؟
برای شرکت در دورههای آنلاین کافه تدریس کافی است به صفحه علم داده وبسایت کافه تدریس مراجعه و دوره مورد نظر خود را انتخاب کنید. پس از ثبتنام و پرداخت هزینه ازطریق داشبورد خود به محتوای دوره و جلسات آنلاین دسترسی خواهید داشت.
بعد از شرکت در دوره چطور میتوانم مطمئن شوم بهخوبی مطالب را یاد بگیرم و میتوانم آنها را بهکار ببندم؟
ما در دپارتمان دیتا ساینس کافه تدریس یک گروه فعال برای شرکت در مسابقات ماهانه کگل داریم که با نظارت مستقیم رضا شکرزاد انجام میشود. شما میتوانید بعد از گذراندن دورهها، با عضویت در این جمع، بهطور گروهی در این مسابقات شرکت کنید و مهارتهای خود را در زمینه ماشین لرنینگ ارتقا دهید.
نحوه عضویت در این جمع و برنامه شرکت در مسابقات کگل، بهطور ماهانه در کانال تلگرامی مربوط به دوره اعلام میشوند و میتوانید با اطلاع از زمان و موضوع مسابقات، خود را برای شرکت در آنها آماده کنید؛ علاوهبراین، جلسههای آنلاین و گروهی نیز برای راهنمایی و پیگیری عملکرد شما طول پروژهها برگزار میشود.
آیا پس از اتمام دوره، مدرک معتبری دریافت میکنم؟
بله، شما پس از اتمام موفقیتآمیز دوره و انجام تکالیف مربوطه، مدرک معتبری از کافه تدریس دریافت خواهید کرد. این مدرک میتواند در رزومه شما درج شود و در پیداکردن شغل به شما کمک کند.
یادگیری تحلیل داده را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده، یا بازاریابی مبتنی بر داده، شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: