در حوزه وسیع یادگیری بدون نظارت (Unsupervised Learning)، الگوریتم K-means به عنوان یک تکنیک اساسی برای خوشهبندی دادهها قرار میگیرد. خواه در حوزهی تقسیمبندی مشتری، تشخیص تصویر یا تشخیص ناهنجاری کار کنید، درک K-means بسیار مهم است. در این پست وبلاگ، نحوه کارکرد الگوریتم K-means، کاربردهای آن را بررسی میکنیم و برخی از بهترین شیوهها را برای پیادهسازی آن را بررسی میکنیم.
- 1. معرفی یادگیری بدون نظارت (Unsupervised Learning)
- 2. الگوریتم K-means چیست؟
- 3. اصطلاحات کلیدی
- 4. مراحل الگوریتم K-means
- 5. مزایا و محدودیتهای الگوریتم K-means
- 6. کاربردهای دنیای واقعی الگوریتم K-means
- 7. بهترین روشها برای پیادهسازی الگوریتم K-means
- 8. الگوریتمهای پیشرفتهتر در خوشهبندی دادهها
- 9. قسمتی از جزوه کلاس برای آموزش الگوریتم k-means
- 10. k-means در پایتون
- 11. خلاصه مطالب
- 12. یادگیری ماشین لرنینگ را از امروز شروع کنید!
معرفی یادگیری بدون نظارت (Unsupervised Learning)
یادگیری بدون نظارت شاخهای مهم از یادگیری ماشین را تشکیل میدهد و به ما امکان میدهد الگوها، ساختارها و روابط را در دادههای بدون برچسب یا راهنمایی صریح کشف کنیم. برخلاف یادگیری تحت نظارت (Supervised Learning)، که در آن الگوریتم از مثالهای برچسبگذاری شده یاد میگیرد، یادگیری بدون نظارت بر روی دادههای بدون برچسب عمل میکند و بر ساختار ذاتی و شباهتهای آن تکیه میکند. الگوریتمهای یادگیری بدون نظارت برای یافتن الگوها یا ساختارهای پنهان در دادهها بدون هیچ گونه خروجی یا متغیر هدف از پیش تعیین شده طراحی شدهاند. از ویژگیها و روابط ذاتی موجود در مجموعه داده برای کشف اطلاعات معنیدار استفاده میکنند. با استخراج دانش از دادههای بدون برچسب، یادگیری بدون نظارت به ما امکان میدهد با چالشهایی که در مواردی که نمونههای برچسبگذاری شده کمیاب هستند یا به سادگی در دسترس نیستند، مقابله کنیم.
پیشنهاد میکنیم درباره یادگیری بدون ناظر هم مطالعه کنید.
الگوریتم K-means چیست؟
الگوریتم K-means قصد دارد یک مجموعه داده را به K خوشه مجزا تقسیم کند. هر خوشه نشاندهنده گروهی از نقاط دادهای است که شباهتهای مشترکی دارند و امکان بینش معنادار و کشف الگو را فراهم میکنند. برای درک کامل K-means، اجازه دهید به اجزای اساسی آن بپردازیم.
اصطلاحات کلیدی
قبل از ادامه، ضروری است که چند اصطلاح کلیدی را تعریف کنیم:
- Centroids: نقاط نماینده هر خوشه هستند و به عنوان مرکز ثقل برای نقاط دادهای که نشان میدهند عمل میکنند.
- خوشهها: گروههایی از نقاط داده هستند که ویژگیهای مشابهی دارند یا نزدیکی به یک مرکز خاص دارند.
- متریکهای فاصله: متداولترین معیار استفاده شده، فاصله اقلیدسی است که فاصله هندسی بین نقاط داده را اندازهگیری میکند.
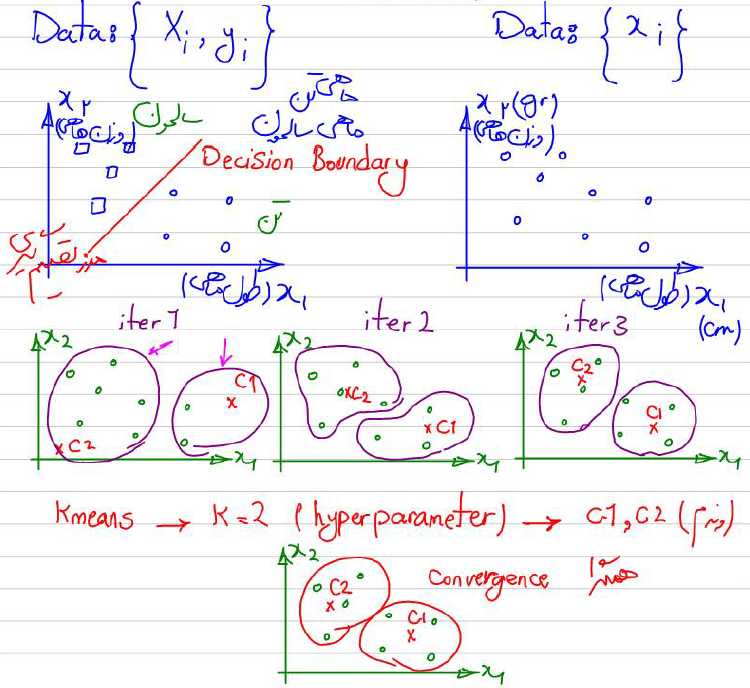
مراحل الگوریتم K-means
الگوریتم K-means یک فرآیند ساده را دنبال میکند که شامل چندین مرحله تکراری است:
مقداردهی اولیه
به طور تصادفی K مرکز خوشه اولیه را از مجموعه داده انتخاب میکند.
این مرکزها به عنوان نقطه شروع برای فرآیند خوشهبندی عمل خواهند کرد.
مرحله تخصیص
برای هر نقطه داده فاصله آن تا هر مرکز را محاسبه میکند.
هر نقطه داده را بر اساس متریک فاصله انتخابی به نزدیکترین مرکز اختصاص میدهد.
مرحله به روزرسانی
پس از تخصیص اولیه، موقعیت مرکزها را دوباره محاسبه میکند.
میانگین تمام نقاط داده اختصاص داده شده به هر مرکز را محاسبه میکند.
مرکزها را به موقعیتهای جدید منتقل میکند.
همگرایی
تخصیص را تکرار میکند و مراحل را به طور مکرر تا زمان همگرایی به روز میکند. همگرایی زمانی اتفاق میافتد که تخصیص نقاط داده تثبیت شود و مرکزها دیگر حرکت قابل توجهی نداشته باشند.
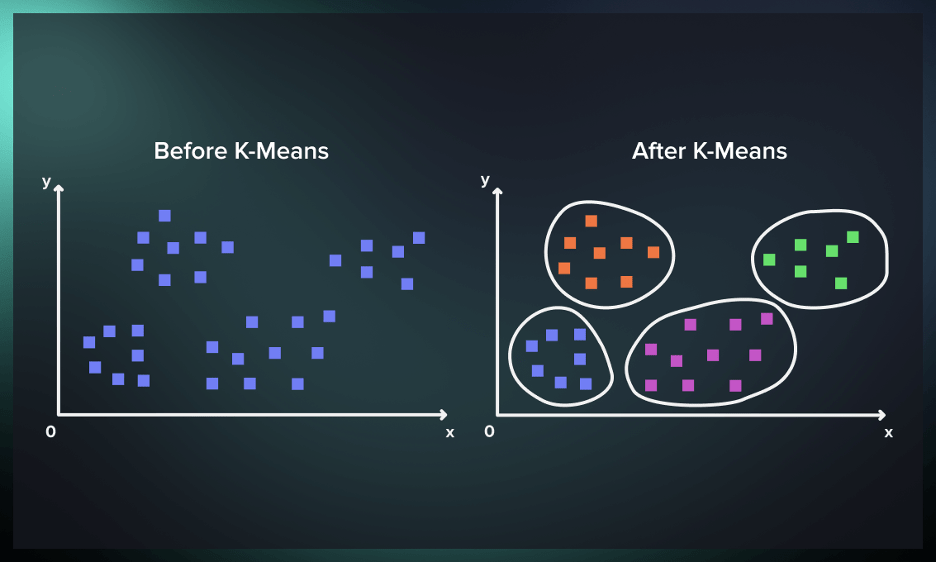
مزایا و محدودیتهای الگوریتم K-means
K-means چندین مزیت از جمله سادگی، کارایی و توانایی مدیریت مجموعه دادههای بزرگ را ارائه میدهد. با این حال، محدودیتهای خاصی نیز دارد:
- حساسیت به مقداردهی اولیه: مقداردهی اولیه مختلف ممکن است منجر به نتایج خوشهبندی متفاوتی شود که بر نیاز به استراتژیهای دقیق مقداردهی اولیه تاکید دارد.
- تعداد خوشهها (K): این الگوریتم نیاز به تعداد خوشهها دارد که از قبل تعریف شده باشد، که وقتی مقدار بهینه ناشناخته باشد میتواند چالشبرانگیز باشد.
حساسیت به نقاط پرت: نقاط پرت میتوانند به طور قابل توجهی بر قرارگیری مرکز و در نتیجه بر نتایج خوشهبندی تأثیر بگذارند.
کاربردهای دنیای واقعی الگوریتم K-means
means کاربردهایی را در حوزههای مختلف دارد. در این بخش چند نمونه قابل توجه آن را معرفی میکنیم.
بخشبندی تصویر (Image Segmentation)
K-means را میتوان برای خوشهبندی پیکسلها در یک تصویر بر اساس مقادیر رنگ یا شدت آنها استفاده کرد.
این تکنیک بخشبندی تصویر را امکانپذیر میکند، که در وظایف بینایی کامپیوتری مانند تشخیص اشیا و فشردهسازی تصویر مفید است.
تقسیمبندی مشتریان
کسبوکارها از K-means برای تقسیمبندی پایگاه مشتریان خود با گروهبندی افراد با الگوهای خرید مشابه یا ویژگیهای جمعیتی استفاده میکنند. این کار امکان ایجاد استراتژیهای بازاریابی هدفمند و تجربیات شخصی مشتری را فراهم میکند.
تشخیص ناهنجاری (Anomaly Detection) K-means میتواند به شناسایی ناهنجاریها یا نقاط پرت در یک مجموعه داده کمک کند. این کار در تشخیص تقلب، تشخیص نفوذ شبکه یا شناسایی الگوهای غیر معمول در دادههای حسگر ارزشمند است.
بهترین روشها برای پیادهسازی الگوریتم K-means
برای اطمینان از اجرای موفقیتآمیز الگوریتم K-means، بهتر است شیوههای زیر را در نظر بگیرید:
انتخاب بهینه K
برای تعیین تعداد مناسب خوشهها برای مجموعه داده خاص خود، از تکنیکهایی مانند Elbow Methodیا تجزیه و تحلیل silhouette استفاده کنید.
پیشپردازش دادهها
دادهها را با مقیاسبندی یا نرمالسازی آنها برای حذف سوگیریهای ایجاد شده توسط محدودهها یا واحدهای دادههای مختلف، از قبل پردازش کنید.
استراتژیهای مقداردهی اولیه
روشهای مختلف مقداردهی اولیه مانند مقداردهی اولیه تصادفی، ++k-means، یا استفاده از دانش قبلی در مورد مجموعه داده را برای بهبود نتایج خوشهبندی آزمایش کنید.
ارزیابی و تفسیر
کیفیت نتایج خوشهبندی را با استفاده از معیارهایی مانند silhouett score یا مجموع مربعهای درون خوشهای ارزیابی کنید. خوشههای تشکیل شده را با تجزیه و تحلیل ویژگیهای نقاط داده در هر خوشه تفسیر کنید.
الگوریتمهای پیشرفتهتر در خوشهبندی دادهها
K-medoids
معرفی: الگوریتم K-medoids یکی از روشهای خوشهبندی است که شباهتهای زیادی به K-means دارد، اما با این تفاوت که به جای میانگین، یک نقطه واقعی در دادهها به عنوان مرکز خوشه انتخاب میشود. این ویژگی باعث میشود K-medoids در مقابل دادههای پرت (outlier) مقاومتر باشد.
کاربرد: K-medoids اغلب در مواردی کاربرد دارد که دادهها دارای پرتهای زیادی هستند یا زمانی که تعریف فاصله بین نمونهها با میانگین، معنادار نیست.
مکانیزم: در K-medoids، هر خوشه توسط یکی از دادههای واقعی خود (که مدوید نامیده میشود) نمایندگی میشود. این انتخاب باعث کاهش تأثیر دادههای پرت و افزایش استحکام الگوریتم در برابر نویز میشود.
فازی C-means
معرفی: فازی C-means یک رویکرد خوشهبندی است که به هر نقطه داده اجازه میدهد به طور همزمان به چندین خوشه تعلق داشته باشد، با درجات عضویت متفاوت.
کاربرد: این الگوریتم بیشتر در مواردی مورد استفاده قرار میگیرد که تقسیمبندی دادهها به خوشههای کاملاً مجزا واقعبینانه نیست و نیاز به انعطافپذیری بیشتری در تعریف خوشهها است.
مکانیزم: در فازی C-means، هر نقطه داده به هر خوشه با یک درجه عضویت خاص تعلق دارد که نشاندهنده میزان شباهت آن نقطه به مرکز خوشه است. این درجه عضویت میتواند بین 0 (عدم تعلق) تا 1 (تعلق کامل) باشد.
این دو الگوریتم، گامهایی فراتر از K-means سنتی هستند و در موقعیتهایی که دادهها پیچیدگیهای خاصی دارند، میتوانند کارایی بهتری از خود نشان دهند. انتخاب میان این الگوریتمها بستگی به ماهیت دادهها و نیازهای خاص تحلیل دارد.
قسمتی از جزوه کلاس برای آموزش الگوریتم k-means
دوره جامع دیتا ساینس و ماشین لرنینگ
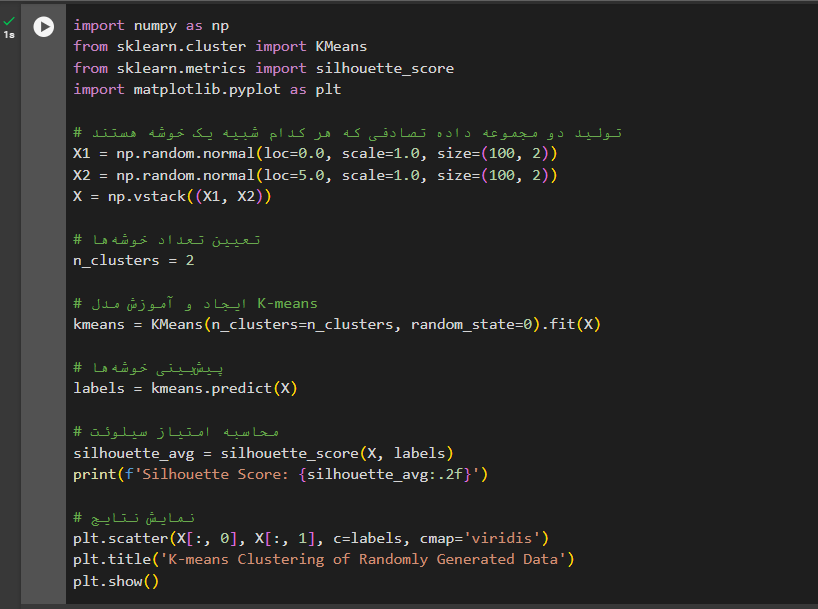
k-means در پایتون
کد زیر نمونهای از پیادهسازی الگوریتم K-means با استفاده از کتابخانه scikit-learn است. ما ابتدا دو مجموعه داده تصادفی ایجاد میکنیم که هر یک شبیه یک خوشه هستند. سپس، این دادهها را با استفاده از الگوریتم K-means به دو خوشه تقسیم میکنیم. برای ارزیابی کیفیت خوشهبندی ما از امتیاز silhouette استفاده میکنیم، که یک معیار عددی بین -1 تا +1 است و نشان میدهد که چقدر دادههای یک خوشه به هم نزدیک هستند و از خوشههای دیگر دورند. امتیاز بالاتر نشاندهنده خوشهبندی بهتر است.
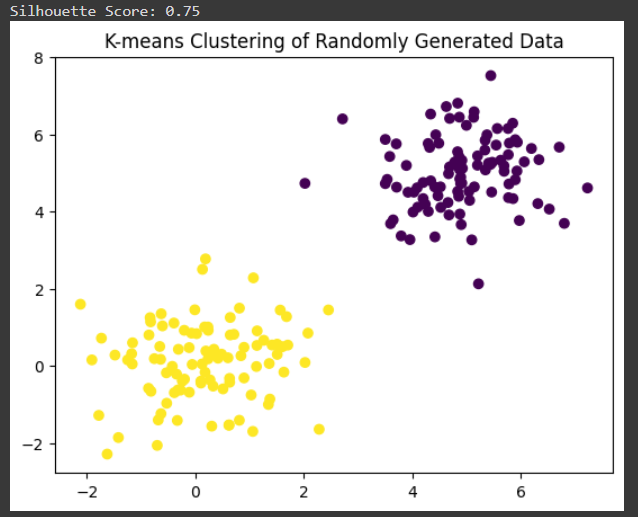
خلاصه مطالب
الگوریتم K-means یک تکنیک قدرتمند و پرکاربرد برای خوشهبندی دادهها است. چه یک دانشمند داده، یک تحلیلگر کسبوکار یا یک یادگیرنده کنجکاو باشید، الگوریتم K-means درهایی را به روی کاوش دادهها و کشف الگوها برایتان باز میکند. به یاد داشته باشید، تمرین و آزمایش برای درک واقعی پتانسیل K-means کلیدی است.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده و یادگیری ماشین شما را برای فرصتهای شغلی بسیاری مناسب میکند. شما، فارغ از رشته و پیشزمینه، میتوانید یادگیری این دانش را همین امروز شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
1-جزو یادگیری بدون نظارت است .
۲-برای خوشه بندی و جدا سازی کاربران استفاده میشود برای سیستم های توصیه دهنده مثلا در ویدئو ها سایت های فروش توصیه فروش محصول به کاربران
۳- مزایا سرعت بالا در اجرا ،بهترین موقیعیت،
معایب ،نیاز داشتن به تعیین تعداد خوشه ها
الگوریتم K-means در چه نوع یادگیریای قرار میگیرد و این نوع یادگیری به چه معناست؟
الگوریتم K-means به عنوان یک تکنیک اساسی برای خوشهبندی دادهها قرار میگیرد. خواه در حوزهی تقسیمبندی مشتری، تشخیص تصویر یا تشخیص ناهنجاری کار کنید
دو مزیت و یک محدودیت الگوریتم K-means را نام ببرید.
K-means چندین مزیت از جمله سادگی، کارایی و توانایی
محدودیت حساسیت به مقداردهی اولیه.
کاربردی از الگوریتم K-means در دنیای واقعی را توضیح دهید.
تقسیمبندی مشتریان
کسبوکارها از K-means برای تقسیمبندی پایگاه مشتریان خود با گروهبندی افراد با الگوهای خرید مشابه یا ویژگیهای جمعیتی استفاده میکنند. این کار امکان ایجاد استراتژیهای بازاریابی هدفمند و تجربیات شخصی مشتری را فراهم میکند
سوال ۳:
تقسیمبندی مشتریان
کسبوکارها از K-means برای تقسیمبندی پایگاه مشتریان خود با گروهبندی افراد با الگوهای خرید مشابه یا ویژگیهای جمعیتی استفاده میکنند. این کار امکان ایجاد استراتژیهای بازاریابی هدفمند و تجربیات شخصی مشتری را فراهم میکند
سوال ۲:
تعداد خوشهها (K):
مزیت: سادگی، کارایی
توانایی مدیریت مجموعه دادههای بزرگ
محدودیت:
الگوریتم نیاز به تعداد خوشهها دارد که از قبل تعریف شده باشد، که وقتی مقدار بهینه ناشناخته باشد میتواند چالشبرانگیز باشد.
سوال ۱:
یادگیری بدون نظارت
یادگیری بدون نظارت بر روی دادههای بدون برچسب عمل میکند و بر ساختار ذاتی و شباهتهای آن تکیه میکند. الگوریتمهای یادگیری بدون نظارت برای یافتن الگوها یا ساختارهای پنهان در دادهها بدون هیچ گونه خروجی یا متغیر هدف از پیش تعیین شده طراحی شدهاند. از ویژگیها و روابط ذاتی موجود در مجموعه داده برای کشف اطلاعات معنیدار استفاده میکنند.
الگوریتم kmeans به صورت غیر نظارت شده هست.این نوع یادگیری به معنای خوشه بندی داده ها و تعیین مراکز آن دسته بندی برای آنکه داده های نزدیک به مراکز پیدا کنیم و داده سازی شبکه عصبی را انجام دهیم.
مزیت ها:سازگاری بیشتری با داده ها دارد. و پیچیدگی هایی که ممکنه برای داده ها باشد مشخص می شود.
محدودیت:حساسیت به داده های پرت و انتخاب تعداد خوشه بندی ها
کاربرد در دنیای واقعی:
برای تشخیص تصویر و پیکسل های موجود تشخیص تصویر میدهد.