
شبکههای عصبی عمیق برای کار کردن به تعداد زیادی پارامتر نیاز دارند که این ویژگی در عین کارآمد شدن باعث ایجاد بیشبرازش (Overfitting) در آنها میشود. برای مقابله با این مشکل، روش Dropout یا حذف کردن معرفی شده است که در حین آموزش واحدهایی از شبکه را به صورت تصادفی حذف میکند تا از آموزش زیاد مدل جلوگیری شود. این روش به طور قابل توجهی بیشبرازش را کاهش میدهد و در زمینههایی چون بینایی، شناسایی گفتار و کلاسبندی مستندات نتایج برتری ارائه میدهد. در این بلاگ مروری بر مقاله Dropout خواهیم داشت.
- 1. تحولی در کارایی شبکههای عصبی
- 2. روشهای آموزش شبکههای عصبی با Dropout
- 3. نتایج اعمال روش Dropout
- 4. ویژگیهای برجسته این روش
- 5. تأثیر نرخ Dropout
- 6. متد Monte-Carlo درمقابل Weight Scaling
- 7. جمعبندی
-
8.
پرسشهای متداول
- 8.1. چه زمانی استفاده از تکنیک Dropout در شبکههای عصبی توصیه میشود؟
- 8.2. آیا استفاده از Dropout میتواند بر سرعت آموزش مدل تأثیر بگذارد؟
- 8.3. در چه مواردی استفاده از Dropout توصیه نمیشود؟
- 8.4. چگونه میتوان بهترین نرخ Dropout را برای یک شبکه عصبی مشخص کرد؟
- 8.5. چگونه میتوان اثربخشی Dropout را در یک مدل شبکه عصبی ارزیابی کرد؟
- 9. یادگیری ماشین لرنینگ را از امروز شروع کنید!
تحولی در کارایی شبکههای عصبی
شبکههای عصبی عمیق قادر به یادگیری روابط پیچیده بین ورودی و خروجی هستند. اما با دادههای آموزشی کم، ممکن است به خاطر نویز در این شبکهها بیشبرازش اتفاق بیوفتد. برای جلوگیری از این مشکل، روشهای مختلفی وجود دارد.
یکی از راههای معمول برای بهبود کارایی مدل، استفاده از چندین مدل و ترکیب آنهاست. ولی در شبکههای بزرگ، این روش زمانبر و هزینهبر است. Dropout یک راه جدید است که به همزمان حل این مشکل و جلوگیری از بیشبرازش کمک میکند. Dropout به معنی حذف موقت یکی از واحدهای شبکه است. و در زمان تست، به جای استفاده از چندین مدل، فقط یک مدل استفاده میشود. در شکل زیر میتوانید اعمال روش Dropout روی یک شبکه عصبی را مشاهده کنید.
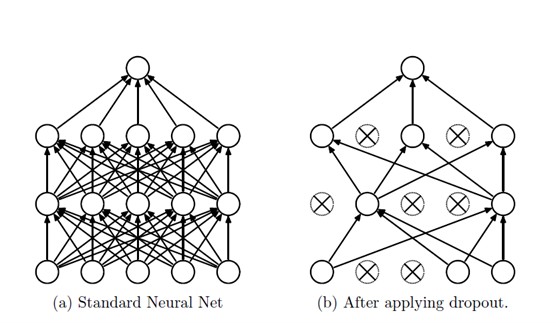
روشهای آموزش شبکههای عصبی با Dropout
Backpropagation
شبکههای عصبی با اعمال Dropout میتوانند با استفاده از کاهش گرادیان تصادفی به شیوهای مشابه شبکههای عصبی استاندارد آموزش داده شوند. تنها تفاوت این است که برای هر مورد آموزشی در یک دسته کوچک، ما برخی از واحدها را حذف (Dropout) میکنیم تا یک شبکه با ساختار نازکتر ایجاد شود. گرادیانها برای هر پارامتر بر روی موارد آموزش در هر دسته کوچک متوسط میشوند. هر مورد آموزشی که از یک پارامتر استفاده نمیکند، گرادیان صفری برای آن پارامتر ارائه میدهد. تعداد زیادی از روشها برای بهبود کاهش گرادیان تصادفی استفاده شده است. این روشها برای شبکههای عصبی با Dropout نیز مفید واقع شدهاند.
درباره عملیات انتشار رو به عقب با Backpropagation بخوانید.
پیشآموزش بدون نظارت
پیشآموزی باعث بهبود قابل ملاحظهای در عملکرد شبکهها در برخی موارد میشود. اما Dropout نیز میتواند در تنظیم مجدد شبکههای پیشآموزیشده با این روشها مفید باشد. برای استفاده از Dropout در شبکههای پیشآموزیشده، روش پیشآموزی بدون تغییر باقی میماند. وزنهای به دست آمده از پیشآموزی باید با ضریبی افزایش یابند. این کار باعث میشود که خروجی مورد انتظار از هر واحد در حالت تصادفی Dropout با خروجی در طول پیشآموزی همتراز باشد.
ممکن است نرخ یادگیری در مرحله تنظیم مجدد به نرخهای یادگیری بهتری برای شبکههای از ابتدا تصادفی نزدیک باشد، اما با انتخاب نرخهای یادگیری کوچکتر، اطلاعات موجود در وزنهای پیشآموزی حفظ میشود و امکان بهبود در دقت تعمیم نهایی را بهبود میبخشد.
نتایج اعمال روش Dropout
Dropout روی مدلها و وظایف متنوعی، ازجمله دستهبندی دوتایی، دستهبندی چندگانه، رگرسیون و دستهبندی چندبرچسبی، ارزیابی شده است. مدلهای مورداستفاده رگرسیون لجستیک، شبکههای پیشرو با چند لایه، شبکههای عصبی پیچشی و شبکههای عصبی بازگشتی را در بر گرفته است.
بیشتر آزمایشها روی دو مجموعه دادهٔ معروف MNIST و CIFAR-10 انجام شده است. در هر دو مورد استفاده از Dropout بهبود عملکرد را رقم زده است. بهبود عملکرد، بهویژه، در مواردی بوده که مدل تعداد زیادی پارامتر در مقایسه با تعداد دادههای آموزشی داشته است. در بسیاری از موارد دراپ اوت، بههمراه دیگر روشهای نرمالسازی، مانند وزندهی و پیشآموزش بدون نظارت، استفاده شده است.
ویژگی مهم این است که استفاده از Dropout به همراه سایر روشها نتایج بهتری ارائه میدهد. در مواردی مانند شبکههای پیچشی آموزش داده شده روی مجموعه داده CIFAR-10، استفاده از Dropout به تنهایی نتایج بهتری نسبت به ترکیب آن با وزندهی یا پیشآموزش بدون نظارت داشته است.
استفاده از دراپاوت در مدل شناسایی اشیا روی مجموعه داده ImageNet عملکرد مدل را بیش از ۲ درصد بهبود بخشیده است. این بهبود چشمگیر است؛ زیرا مدل از قبل نیز عملکرد خوبی داشته است. درمورد یک شبکه عصبی بازگشتی که برای پیشبینی کلمه بعدی در یک جمله آموزش داده شده استفاده از دراپ اوت عملکرد را بیش از ۳ درصد افزایش داده است. Dropout قابلیت آموزش مدلهای بزرگتر را نیز دارد؛ این امر بهاین دلیل است که این روش با ایجاد نسخههای مختلف از مجموعه آموزشافزایش مقدار دادههای آموزشی را رقم میزند؛ همچنین استفاده از آن میتواند عملکرد مدلهایی را هم که از قبل عملکرد خوبی دارند بهبود ببخشد و از بیشبرازش جلوگیری کند.
ویژگیهای برجسته این روش
آزمایشهای انجامشده در بخش قبل نشاندهنده اثربخشی Dropout در بهبود شبکههای عصبی هستند. در این بخش تأثیر این روش بر ویژگیهای تولیدشده، تأثیر آن بر فراوانی فعالیت واحدهای پنهان و نحوه تغییر مزیتهای حاصل از دراپاوت با تغییر احتمال حفظ واحدها، اندازه شبکه و اندازه مجموعهی آموزشی بررسی شده است.
تأثیر بر ویژگیها
در شبکههای عصبی سنتی هر مؤلفه بهنحوی تغییر میکند که تابع خطا درنهایت کاهش یابد. این رفتار میتواند به تعاملهای پیچیده میان واحدها بینجامد که درنهایت به بیشبرازش ختم میشود. با استفاده از دراپ اوت، بهدلیل عدم قطعیت در فعالبودن واحدهای مخفی، از این تعاملهای پیچیده جلوگیری میشود؛ بهعبارت دیگر، یک واحد مخفی نمیتواند بهطور کامل به دیگر واحدهای خاصی تکیه کند تا اشتباهاتش را جبران کند. برای مشاهدهٔ این تأثیر بهطور مستقیم ویژگیهایی که توسط شبکههای عصبی در وظایف تصویری با و بدون استفاده از Dropout آموخته شده است بررسی شدهاند. در تصویر تاثیر این روش روی مجموعه داده MNIST قابل مشاهده است.

تأثیر بر فراوانی
وقتی از دراپاوت در شبکههای عصبی استفاده میشود، برخی از واحدهای مخفی بهصورت تصادفی غیرفعال میشوند. این کار به این میانجامد که شبکه به تعداد کمتری از واحدها تکیه کند و هر واحد بهتنهایی سعی کند بهتر عمل کند. یکی از نتایج جانبی این روش این است که فقط تعداد محدودی از واحدها در هر مرحله فعال میشوند؛ بهعبارت دیگر، Dropout کمک میکند که شبکه از ویژگیهای مختلف بهتر و با تنوع بیشتری استفاده کند.
در شکل برای هر دو مدل از تابع فعالسازی ReLU استفاده شده است. در قسمت چپ، هیستوگرام میانگین فعالیتها نشان میدهد که اکثر واحدها یک میانگین فعالیت حدود ۲ دارند. هیستوگرام فعالیتها یک قله بزرگی دور از صفر نشان میدهد که بهوضوح نشاندهنده این است که یک نسبت زیادی از واحدها فعالیت بالایی دارند. در قسمت راست، هیستوگرام میانگین فعالیتها نشان میدهد که اکثر واحدها میانگین فعالیت کمتری حدود ۰.۷ دارند. هیستوگرام فعالیتها یک قله تندی در نقطه صفر نشان میدهد. تنها تعداد بسیار کمی از واحدها فعالیت بالایی دارند.

تأثیر نرخ Dropout
این روش یک هایپرپارامتر قابل تنظیم دارد که احتمال حفظ یک واحد در شبکه را نشان میدهد. در این بخش تأثیر تغییر این هایپرپارامتر بررسی شده است.
تأثیر اندازه مجموعه داده
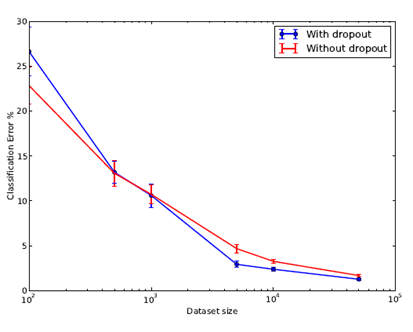
نتایج نشان میدهند که در مجموعههای داده بسیار کوچک دراپاوت بهبود چندانی ارائه نمیکند، اما با افزایش اندازه دادهها، سود حاصل از آن افزایش مییابد و سپس کاهش مییابد. این نتایج نشاندهنده وجود یک نقطه بهینه در اندازه دادهها برای استفاده بهینه از Dropout است. در شکل تأثیر اندازه مجموعه داده و میزان خطا قابل مشاهده است.
متد Monte-Carlo درمقابل Weight Scaling
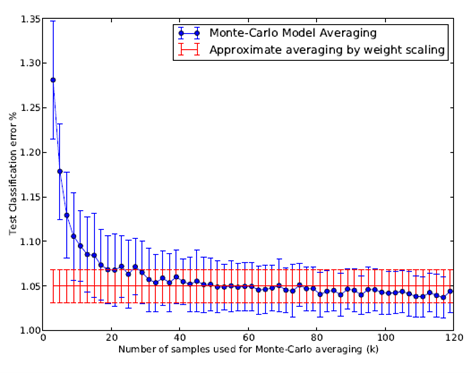
روش کارآمدی که ما پیشنهاد میکنیم این است که در زمان تست، با کاهش وزنهای شبکه عصبی آموزشدادهشده، یک ترکیب مدل تقریبی انجام دهیم. روش گرانقیمتتر و اصولیتر دیگری برای میانگینگیری از مدلها وجود دارد که با نمونهبرداری از k شبکه عصبی با استفاده از Dropout برای هر مورد آزمون و میانگینگیری پیشبینیهای آنها انجام میدهد.
با افزایش تعداد k به مقدار بینهایت این میانگین مدل مونت-کارلو به میانگین واقعی مدل نزدیک میشود. جالب است که بهصورت تجربی ببینیم که چندین نمونه k برای تطابق با عملکرد روش میانگینگیری تقریبی لازم است. با محاسبه خطا برای ارزشهای مختلف k میتوانیم ببینیم که چقدر سریع نرخ خطای میانگین نمونه مقدار نرخ خطای واقعی مدل نزدیک میشود.
ما دوباره از مجموعه داده MNIST استفاده میکنیم و با میانگینگیری از پیشبینیهای k شبکه عصبی که بهصورت تصادفی نمونهبرداری شدهاند دستهبندی را انجام میدهیم. در تصویر ۱۱ نرخ خطای آزمون برای ارزشهای مختلف k نشان داده شده است. این با نرخ خطای بهدستآمده با استفاده از روش کاهش وزن (نمایششده بهعنوان یک خط افقی) مقایسه میشود. مشاهده میشود که حدوداً در k = 50، روش مونت-کارلو بهعنوان روش تقریبی خوب عمل میکند. پس از آن، روش مونت-کارلو کمی بهتر از روش تقریبی عمل میکند، اما در حد یک انحراف معیار از آن واقع میشود و نشان میدهد که روش کاهش وزن تقریباً بهخوبی از میانگین واقعی مدل تقریب میدهد.
جمعبندی
با استفاده از Dropout در آموزش شبکههای عصبی میتوان بهبود چشمگیری در عملکرد این شبکهها در تنظیمات مختلف مشاهده کرد. این تکنیک، بهدلیل شکستن ارتباطات آسیبپذیر بین واحدهای شبکه، جلوگیری از بیشبرازش و افزایش توانایی شبکه در تعمیم به دادههای جدید را رقم میزند؛ همچنین دراپاوت بهعنوان یک تکنیک عمومی شناخته میشود که در حوزههای مختلفی ازجمله تصویربرداری اشیا، تشخیص اعداد، تشخیص گفتار، دستهبندی اسناد و تجزیهوتحلیل دادههای بیولوژی محاسباتی بهبود عملکرد شبکههای عصبی را ایجاد کرده است. از این رو، Dropout به عنوان یک تکنیک عمومی قابل توجه است که در انواع مختلفی از وظایف و دادهها به کار میرود. همچنین میتوان ایده دراپ اوت را به دیگر مدلهای گرافیکی نیز انتقال داد تا بهبودهای مشابهی در آنها ایجاد شود. با وجود این، یکی از مسائلی که در استفاده از دراپ اوت به وجود میآید، افزایش زمان آموزش است که به مدیریت دقیقتری نیاز دارد.
پرسشهای متداول
چه زمانی استفاده از تکنیک Dropout در شبکههای عصبی توصیه میشود؟
این روش بهخصوص هنگامی توصیه میشود که شبکه عصبی با مشکل بیشبرازش (Overfitting) مواجه باشد. این تکنیک با حذف تصادفی برخی از نورونها در طول فرایند آموزش به این میانجامد که مدل توانایی تعمیم به دادههای جدید را بهتر کسب کند. در پروژههایی با دادههای محدود یا پیچیده دراپاوت میتواند بهشکل چشمگیری از بیشبرازش جلوگیری کند و دقت مدل را بهبود ببخشد.
آیا استفاده از Dropout میتواند بر سرعت آموزش مدل تأثیر بگذارد؟
بله، استفاده از این روش ممکن است بر سرعت آموزش تأثیر بگذارد؛ زیرا مدل باید روی نمونههای متفاوتی از شبکههای عصبی آموزش ببیند؛ بااینحال این افزایش در زمان آموزش میتواند بهبود دقت مدل در دادههای تست و کاهش خطر بیشبرازش را رقم بزند؛ بنابراین اغلب ارزش آن را دارد.
در چه مواردی استفاده از Dropout توصیه نمیشود؟
استفاده از دراپاوت ممکن است در شبکههای عصبی با تعداد دادههای آموزشی بسیار زیاد که خطر بیشبرازش در آنها کمتر است ضروری نباشد؛ همچنین در مواردی که زمان آموزش محدود است یا مدل نیاز به پاسخگویی سریع دارد، ممکن است بهتر باشد از روشهای دیگر برای جلوگیری از بیشبرازش استفاده شود.
چگونه میتوان بهترین نرخ Dropout را برای یک شبکه عصبی مشخص کرد؟
انتخاب نرخ Dropout (معمولاً بین 0.2 تا 0.5) بستگی به ماهیت دادهها و معماری شبکه دارد. بهترین روش برای استفاده از روشهایی مانند تنظیم متقابل (cross-validation) و آزمایش با دامنههای مختلف نرخ Dropout است. به طور کلی، آزمایش و خطا بهترین روش برای یافتن نرخ Dropout مناسب برای یک مدل خاص است.
چگونه میتوان اثربخشی Dropout را در یک مدل شبکه عصبی ارزیابی کرد؟
اثربخشی Dropout میتواند از طریق مقایسه عملکرد مدل با و بدون استفاده از Dropout بر روی دادههای تست ارزیابی شود. بهبود در دقت تست و کاهش در خطای تعمیم (generalization error) نشاندهنده اثربخشی Dropout در مدل است. همچنین، رصد کردن روند آموزش و تغییرات دقت در طول زمان میتواند نشاندهنده تأثیر Dropout در کاهش بیشبرازش باشد.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید: