

کم برازش (Underfitting) چیست؟ چه زمانی اتفاق میافتد و راههای جلوگیری از آن کدام است؟ بهزبان ساده، کمبرازش هنگامی اتفاق میافتد که مدل یادگیری ماشین بهاندازهی کافی پیچیده نباشد که بتواند روابط میان ویژگیهای یک مجموعه داده و متغیر هدف را بهدرستی تشخیص دهد.
مدلی که به مشکل کمبرازش دچار است به نتایج اشتباه در دادههای جدید را که روی آنها آموزش داده نشده است رقم خواهد زد و اغلب حتی درمورد دادههای آموزشی نیز عملکرد ضعیفی دارد. زمانی که مدل دچار مشکل کم برازش (Underfitting) است بسیاری از ویژگیهای دادههای آموزشی را را نادیده میگیرد و نمیتواند رابطهی میان ورودی و خروجی را یاد بگیرد.
در این مطلب بهصورت کامل این مفاهیم و وضعیتها را توضیح دادهایم و راههای جلوگیری از آن را برشمردهایم.

مقدمه
میتوان گفت یادگیری ماشین (Machine Learning)، بهعنوان یک علم، بههمان اندازه که مهم و چشمگیر است، پیچیده نیز است؛ درواقع اساس آن از مسائل فنی و ریاضی تشکیل شده است. اگر نتوانیم این مسائل فنی را درک کنیم، نمیتوانیم بگوییم یادگیری ماشین را یاد گرفتهایم؛ برای مثال، اگر بهعنوان یک محقق داده (Data Scientist) به مصاحبهی کاری برویم، بهطور حتم از ما سؤال میشود که «آیا میتوانید دربارهی مشکل کمبرازش (Underfitting) و بیشبرازش (Overfitting) در یادگیری ماشین توضیح دهید؟». البته آنان به دنبال این نیستند که تمامی جزئیات این مسائل را با نمودار برایشان شرح دهید، اما میخواهند بدانند شما این مفهوم را درک کردهاید یا نه.
اگر میخواهید به دنیای علم داده یا دیتا ساینس وارد شوید، حتماً باید بدانید کمبرازش در یادگیری ماشین چیست. در این مطلب مشکل کمبرازش را معرفی و راههای جلوگیری از ایجاد آن را بررسی کنیم.
اگر علاقهمند به مطالعه درباره یادگیری ماشین هستید، به این لینک سر بزنید:
یادگیری ماشین (Machine Learning) چیست و چگونه کار میکند؟


کم برازش (Underfitting) چیست؟
کم برازش (Underfitting) سناریویی در علم داده یا دیتا ساینس (Data Science) است که در آن یک مدل قادر نیست رابطهی میان متغیرهای ورودی و خروجی را به طور دقیق ثبت کند. این خطا ایجاد خطای بالایی در هر دو مجموعهی آموزشی و مجموعهی دادههای دیدهنشده (تست) را رقم میزند.
این امر زمانی رخ میدهد که مدل بیشازحد ساده باشد؛ بهاین معنا که مدل به زمان آموزش بیشتر، ویژگیهای ورودی بیشتر یا تنظیم (Regularization) کمتر نیاز دارد.
مدل در کمبرازش نمیتواند الگوی غالب را در دادهها را تشخیص دهد؛ درنتیجه، این امر افزایش خطا و عملکرد ضعیف مدل را به همراه دارد.
اگر مدلی نتواند بهخوبی به دادههای جدید تعمیم داده شود، نمیتوان از آن برای طبقهبندی یا پیشبینی استفاده کرد. تعمیم یک مدل به دادههای جدید درنهایت همان چیزی است که به ما امکان میدهد هر روز از الگوریتمهای یادگیری ماشین برای پیشبینی و طبقهبندی دادهها استفاده کنیم.
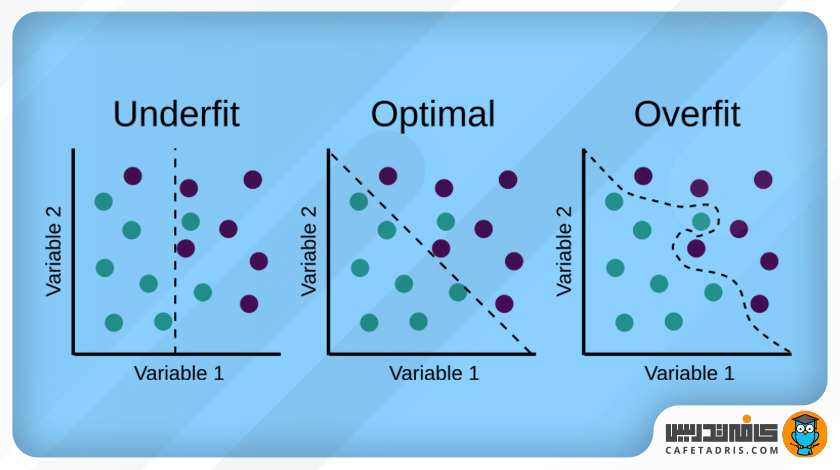
شاخصهای تشخیص کم برازش (Underfitting)
بایاس بالا (High Bias) و واریانس پایین (Low Variance) شاخصهای خوبی برای تشخیص کمبرازش هستند. از آنجا که این رفتار در هنگام استفاده از مجموعهی دادههای آموزشی دیده میشود، معمولاً شناسایی مدلهای دچار کمبرازش راحتتر از مدلهایی است که دچار بیشبرازش (Overfitting) هستند.
همانطور که اشاره کردیم، یکی دیگر از مشکلاتی که ممکن است در حین آموزش مدل با آن روبهرو شویم مشکل بیشبرازش (Overfitting) است. برای مطالعه بیشتر در این باره به این لینک سر بزنید:
بیش برازش (Overfitting) چیست و برای جلوگیری آن چه باید کرد؟
چطور از بروز مشکل کمبرازش جلوگیری کنیم؟
از آنجا که مشکل کمبرازش میتواند مشکلات زیادی را برای مدل ایجاد کند و درنهایت نتایج نامطلوبی رقم بزند، لازم است به دنبال راههایی برای جلوگیری از بروز آن باشیم. در ادامه به چند روش معمول برای این کار اشاره خواهیم کرد.
۱. کاهش تنظیم (Decreasing Regularization)
چندین روش مختلف مانند تنظیم L1، دراپاوت (Drop out) و غیره وجود دارد که به کاهش نویز (Noise) در مدل کمک میکند؛ بااینحال اگر ویژگیهای داده بیشازحد یکنواخت شوند، مدل قادر به شناسایی روند غالب دادهها نیست و این موضوع به کم برازش (Underfitting) میانجامد. با کاهش میزان تنظیم (Regularization) پیچیدگی و تنوع مدل بیشتر میشود و امکان آموزش موفقیتآمیز مدل فراهم میآید.
۲. افزایش مدتزمان آموزش مدل
توقف زودهنگام آموزش نیز میتواند به مدل کمبرازش (Underfitted Model) بینجامد؛ بنابراین با افزایش مدتزمان آموزش میتوان از بروز این مشکل جلوگیری کرد. لازم است در نظر بگیریم که آموزش بیشازحد مدل نیز میتواند به مشکل بیش برازش (Overfitting) بینجامد و تعادل کم برازش (Underfitting) را بر هم بزند؛ پس باید تعادلی میان این دو ایجاد کنیم.
۳. انتخاب ویژگی (Feature Selection)
در هر مدلی از ویژگیهای خاصی برای تعیین نتیجهی مشخص استفاده میشود. اگر ویژگیهای کافی وجود نداشته باشد، باید ویژگیهای بیشتر یا ویژگیهایی با اهمیت بیشتر به مدل اضافه شوند؛ برای مثال، در یک شبکهی عصبی (ANN) ممکن است نودهای پنهان بیشتر یا در یک جنگل تصادفی (Random Forest) درختان بیشتری اضافه کنیم. این فرایند پیچیدگی بیشتری را به مدل تزریق و بهاین شکل نتایج بهتری را ارائه میکند.
برای آشنایی بیشتر با یادگیری ماشین روی این لینک کلیک کنید:
پرسشهای متداول یادگیری ماشین که باید پاسخشان را بدانید!
جمعبندی مطالب دربارهی کمبرازش (Overfitting)
در این مقاله مشکل کم برازش (Overfitting) پرداختیم و با راههای مقابله با آن آشنا شدیم. حل مشکل کمبرازش اهمیت بالایی دارد و استفاده از یک مدل که دچار کمبرازش است مشکلات زیادی را به همراه دارد.
برای مثال، اگر از یک مدل با مشکل کمبرازش برای تصمیمگیریهای تجاری استفاده کنیم، ممکن است مدل به ما پیشنهاد کند که با صرف هزینهی بیشتر در بازاریابی، به سود بیشتری دست پیدا میکنیم، درحالیکه تأثیر اشباع (Saturation) را در نظر نگرفته است.
مشکل اشباع زمانی به وجود میآید که از یک بازهای بهبعد هر قدر هزینه کنیم، سودی به دست نمیآوریم؛ بنابراین زمانی که تجارت ما کاملاً بر پایهی پیشبینی مدل است، با نتایج اشتباه مدل، ضررهای جبرانناپذیری خواهیم داشت و این نشاندهنده لازمه حل مشکل کم برازش (Underfitting) در مدل است.

یادگیری علم داده و یادگیری ماشین در کلاسهای آنلاین آموزش علم داده کافهتدریس
اگر دوست دارید علم داده را یاد بگیرید و به دنیای ماشین لرنینگ وارد شوید، پیشنهاد ما شرکت در کلاسهای آنلاین آموزش علم داده کافهتدریس است.
کلاسهای آنلاین آموزش علم داده کافهتدریس بهصورت کاملاً تعاملی و در قالب دو دورهی مقدماتی و پیشرفته برگزار میشود. شکل کار این کلاسها بهصورت کارگاهی و مبتنی بر کار روی پروژههای واقعی دیتا ساینس است.
شما با شرکت در کلاسهای آنلاین آموزش علم داده کافهتدریس در هر نقطهی جغرافیایی به جامعترین و بهروزترین آموزش علم داده دسترسی دارید.
برای آشنایی بیشتر با کلاسهای آنلاین علم داده کافهتدریس و مشاورهی رایگان برای شروع یادگیری و مسیر شغلی دیتا ساینس روی این لینک کلیک کنید: