
با پیشرفت هر روزه یادگیری ماشین و نقش مهمی که در زندگی ما بر عهده گرفته است الگوریتمهای مختلف هم در این دانش نقش مهمتری بر عهده میگیرند. الگوریتم های یادگیری گروهی (Ensemble Learning) رویکردی قدرتمند و انعطافپذیر در ماشین لرنینگ است. این الگوریتمها، با ترکیب چندین مدل یادگیری منفرد، عملکرد پیشبینی را بهمیزان قابل توجهی بهبود میبخشد. این روش با بهرهگیری از خرد جمعی و ترکیب دیدگاههای مختلف قادر به غلبه بر نقاط ضعف مدلهای انفرادی و دستیابی به نتایج بهمراتب دقیقتر و قابل اعتمادتری است. یادگیری گروهی اغلب در زمینههای یادگیری نظارتشده به کار برده میشوند، جایی که مدلها با استفاده از دادههای دارای برچسب آموزش میبینند. استفاده از یادگیری گروهی در یادگیری بدون نظارت نیز امکانپذیر است، اما کمتر متداول است. برای آشنایی با الگوریتم های یادگیری گروهی در ماشین لرنینگ تا انتها با ما همراه باشید.
- 1. اهمیت و مزایای استفاده از روشهای یادگیری گروهی
- 2. انواع مختلف الگوریتم های یادگیری گروهی در ماشین لرنینگ
- 3. Bagging، روشی قدرتمند در یادگیری گروهی
- 4. Boosting: روشی کارآمد برای بهبود دقت پیشبینی در یادگیری ماشین
- 5. Stacking: ترکیب مدلها برای پیشبینی دقیقتر
- 6. قسمتی از جزوه کلاس برای مبحث یادگیری گروهی
- 7. اجرای الگوریتم LightGBM از یادگیری گروهی در پایتون
- 8. جمعبندی الگوریتمهای یادگیری گروهی
-
9.
پرسشهای متداول
- 9.1. چرا یادگیری گروهی (Ensemble Learning) در یادگیری ماشین اهمیت دارد؟
- 9.2. روشهای یادگیری گروهی مختلفی مانند Bagging، Boosting، و Stacking چگونه عمل میکنند؟
- 9.3. مزیتهای اصلی استفاده از یادگیری گروهی چیست و چه محدودیتهایی دارد؟
- 9.4. انواع مختلف یادگیری گروهی (همگن و ناهمگن) چه تفاوتهایی دارند؟
- 9.5. الگوریتمهای محبوبی مانند AdaBoost ،Gradient Boosting و XGBoost چگونه به بهبود یادگیری گروهی کمک میکنند؟
- 10. یادگیری ماشین لرنینگ را از امروز شروع کنید!
اهمیت و مزایای استفاده از روشهای یادگیری گروهی
روشهای یادگیری گروهی، در مقایسه با استفاده از مدلهای انفرادی، مزایای فراوانی را ارائه میکنند. این مزیتها آنها را به ابزار ارزشمندی در جعبه ابزار یادگیری ماشین تبدیل میکند. در ادامه به برخی از مهمترین مزیتهای استفاده از روشهای یادگیری گروهی اشاره کردهایم:
دقت پیشبینی بالاتر
یادگیری گروهی، با ترکیب پیشبینیهای چندین مدل، خطاهای فردی مدلها را کاهش میدهد و پیشبینیهای دقیقتر و قابل اطمینانتری را رقم میزند. این امر، بهویژه، در مواردی که دادههای آموزشی محدود یا ناقص است اهمیت پیدا میکند.
کاهش ریسک بیشبرازش (Overfitting)
یکی از چالشهای اصلی در یادگیری ماشین پدیده بیشبرازش است. در این حالت مدل بیشازحد با دادههای آموزشی متناسب میشود و در هنگام برخورد با دادههای جدید عملکرد ضعیفی دارد. یادگیری گروهی با استفاده از مدلهای متنوع و کاهش وابستگی بیشازحد به هر زیرمجموعه خاص از دادهها، ریسک بیشبرازش را بهمیزان قابلتوجهی کاهش میدهد.
پیشنهاد میکنیم بیش برازش (Overfitting) هم مطالعه کنید.
بهبود تعمیمپذیری (Generalization)
تعمیمپذیری یا توانایی مدل برای پیشبینی دقیق روی دادههای جدید که قبلاً دیده نشدهاند یکی از جنبههای مهم در یادگیری ماشین است. الگوریتم های یادگیری گروهی در ماشین لرنینگ با استفاده از مدلهای متنوع و کاهش وابستگی به ویژگیهای خاص توانایی مدل را برای تعمیم به دادههای جدید افزایش میدهد.
کاهش وابستگی به ویژگیها (Feature Dependency)
وابستگی بیشازحد به ویژگیهای خاص میتواند به ایجاد مدلهایی بینجامد که دربرابر نویز و تغییرات در ویژگیها حساس هستند. یادگیری گروهی با استفاده از مدلهای متنوع و کاهش وابستگی بیشازحد به هر ویژگی خاص این وابستگی را کاهش میدهد و مدلهای مقاومتری در برابر تغییرات در دادهها ایجاد میکند.
قابلیت استفاده از مدلهای مختلف
یادگیری گروهی امکان استفاده از انواع مختلف مدلهای یادگیری را فراهم میکند، ازجمله مدلهای خطی، غیرخطی، درختهای تصمیم، شبکههای عصبی و روشهای مبتنی بر نمونه (Instance-Based Methods). این انعطافپذیری به این میانجامد که یادگیری گروهی برای طیف گستردهای از مسائل یادگیری ماشین کاربردی باشد.
انواع مختلف الگوریتم های یادگیری گروهی در ماشین لرنینگ
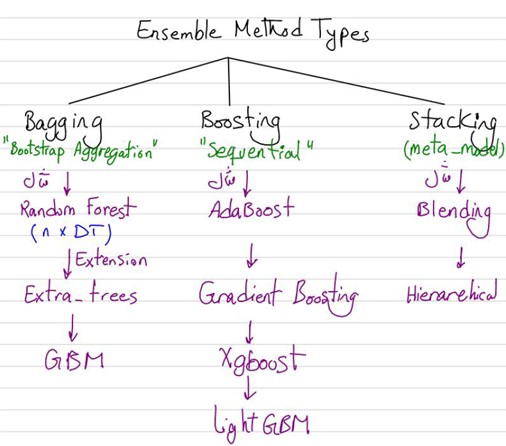
یادگیری گروهی بهطور کلی به دو دسته اصلی یادگیری گروهی همگن (Homogeneous Ensemble Learning) و یادگیری گروهی ناهمگن (Heterogeneous Ensemble Learning) تقسیم میشود. در یادگیری گروهی همگن مدلهای پایه (Base Models) از نوع یکسانی هستند، درحالیکه در یادگیری گروهی ناهمگن مدلهای پایه از انواع مختلفی تشکیل شدهاند. در ادامه، چهار روش رایج در یادگیری گروهی را معرفی کردهایم:
Bagging
Bagging یا Bootstrap Aggregation یکی از سادهترین و درعینحال مؤثرترین روشهای یادگیری گروهی است. در این روش چندین مدل پایه مشابه از زیرمجموعههای مختلف دادههای آموزشی ایجاد میشوند. این زیرمجموعهها با استفاده از روش نمونهگیری با جایگذاری (Bootstrap Sampling) ایجاد میشوند، بهاین معنی که هر نمونه داده ممکن است چندین بار در زیرمجموعههای مختلف ظاهر شود. پیشبینی نهایی با ترکیب پیشبینیهای مدلهای پایه معمولاً با میانگین یا میانه انجام میشود. مجموعهسازی با ایجاد تنوع میان مدلهای پایه ریسک بیشبرازش را کاهش میدهد و به بهبود دقت پیشبینی کمک میکند
Boosting
Boosting روشی مبتنی بر توالی (Sequential) است که در آن مدلهای پایه بهصورت متوالی ساخته میشوند. در هر مرحله مدل جدید براساس اشتباهات مدل قبلی ساخته میشود، بهاین معنی که مدل جدید سعی میکند اشتباههای مدل قبلی را اصلاح کند. این رویکرد بهطور خاص برای روشهایی مانند درخت تصمیم مفید است؛ زیرا درختان تصمیم تمایل به بیشبرازش دارند. تقویت، با تمرکز بیشتر بر نقاط ضعف مدلهای قبلی، دقت پیشبینی را بهبود میبخشد.
Stacking
Stacking روشی مبتنی بر متا مدل (Meta Model) است که در آن چندین مدل پایه برای پیشبینی یک هدف مشخص ساخته میشوند و سپس از یک مدل متا برای ترکیب پیشبینیها استفاده میشود. مدل متا، با یادگیری از خروجی مدلهای اولیه، پیشبینیهای نهایی را انجام میدهد. استکینگ با استفاده از اطلاعات اضافی از پیشبینیهای مدلهای پایه، میتواند دقت پیشبینی را بیشتر بهبود بخشد.
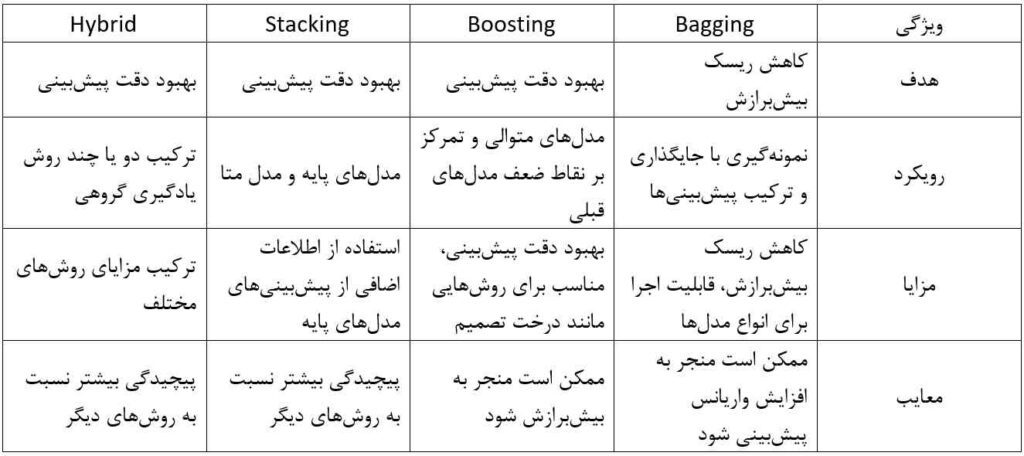
ترکیبی (Hybrid)
Hybrid روشی ترکیبی است که از ترکیب دو یا چند روش یادگیری گروهی، مانند Bagging ،Boosting و Stacking، استفاده میکند. این روش میتواند با ترکیب مزیتهای روشهای مختلف عملکرد پیشبینی را حتی بیشتر بهبود بخشد؛ برای مثال، میتوان از مجموعهسازی برای ایجاد چندین مدل تقویتشده استفاده کرد.
انتخاب روش یادگیری گروهی مناسب به عوامل مختلفی مانند نوع مسئله یادگیری ماشین، ویژگیهای دادهها و پیچیدگی مدنظر بستگی دارد. با درک درست از مزیتها و عیبهای هر روش، میتوان بهترین روش را برای حل مسئله خاص انتخاب کرد.
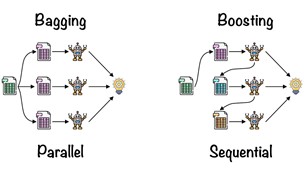
Bagging، روشی قدرتمند در یادگیری گروهی
Bagging یکی از روشهای قدرتمند یادگیری گروهی در ماشین لرنینگ است. در ادامه این روش را بررسی کردهایم:
مراحل Bagging
روش مجموعهسازی این مرحلهها را دربرمیگیرد:
- ایجاد زیرمجموعه های داده: چندین زیرمجموعه از داده های آموزشی با استفاده از روش نمونهگیری با جاگذاری (Bootstrap Sampling) ایجاد می شود. در نمونهگیری با جاگذاری هر نمونه داده ممکن است چندین بار در زیرمجموعه های مختلف ظاهر شود.
- ایجاد مدل های پایه: برای هر زیرمجموعه داده یک مدل پایه مشابه ایجاد می شود. مدلهای پایه معمولاً از نوع درخت تصمیم، شبکه عصبی یا روشهای دیگر هستند.
- ترکیب پیشبینیها: پیشبینیهای مدلهای پایه با هم ترکیب میشوند. این ترکیب معمولاً با میانگین یا میانه پیشبینیها انجام می شود.
Bagging بهطور خاص برای روشهایی مانند درخت تصمیم و جنگل تصادفی مفید است؛ زیرا تمایل به بیشبرازش دارند.
مزیتهای اصلی Bagging
مزیتهای اصلی روش مجموعهسازی از این قرار است:
- دقت بالا: مجموعهسازی، با ترکیب پیشبینیهای چندین مدل، دقت کلی پیش بینی را بهبود میبخشد.
- کاهش ریسک بیشبرازش: مجموعهسازی، با ایجاد تنوع میان مدلهای پایه، ریسک بیشآموزی را کاهش میدهد.
- قابلیت اجرا برای انواع مدلها: مجموعهسازی را میتوان با انواع مختلفی از مدلهای پایه، ازجمله درخت تصمیم، شبکه عصبی و روشهای دیگر، استفاده کرد.
این موارد صرفاً سه مزیت اصلی استفاده از روش Bagging بود.
محدودیتها و چالشهای Bagging
محدودیتها و چالشهای روش مجموعهسازی از این قرار است:
- افزایش واریانس پیشبینی: مجموعهسازی ممکن است به افزایش واریانس پیشبینی بینجامد، بهاین معنی که پیشبینیهای مدل ممکن است با هم متفاوت باشند.
- پیچیدگی محاسباتی: مجموعهسازی میتواند از نظر محاسباتی فشرده باشد، بهخصوص هنگام استفاده از مدلهای پایه پیچیده، مانند شبکههای عصبی.
- نیاز به تنظیم پارامتر: مجموعهسازی به تعدیل دقیق پارامترهایی مانند تعداد مدلهای پایه و روش ترکیب پیشبینیها نیاز دارد.
روش مجموعهسازی میتواند با چالشها و محدودیتهای دیگری هم مواجه باشد.
Boosting: روشی کارآمد برای بهبود دقت پیشبینی در یادگیری ماشین
تقویت یکی از روشهای کارآمد برای یادگیری گروهی در ماشین لرنینگ است. با این روش آشنا شوید:
مراحل Boosting
- ایجاد مدل اولیه: یک مدل اولیه ساده روی مجموعه دادههای آموزشی کامل ساخته میشود.
- محاسبه وزن نمونهها: وزنهایی به هر نمونه داده براساس اشتباههای مدل اولیه اختصاص داده می شود. نمونههایی که مدل اولیه در پیشبینی آنها اشتباه کرده است وزن بیشتری دریافت میکنند.
- ایجاد مدل دوم: یک مدل دوم روی مجموعه دادههای وزندار ساخته میشود. این مدل دوم بهطور خاص روی نمونههایی تمرکز میکند که مدل اولیه در پیشبینی آنها اشتباه کرده است.
- ترکیب پیشبینیها: پیشبینیهای مدل اولیه و مدل دوم با هم ترکیب میشوند تا یک پیشبینی نهایی ایجاد شود.
- تکرار مراحل: مراحل ۲ تا ۴ تا زمانی که دقت پیشبینی به حد قابل قبولی برسد تکرار میشوند.
مرحلههای Boosting کمک میکنند که با یادگیری گروهی در ماشین لرنینگ عملکرد بهتری داشته باشید.
الگوریتمهای محبوب Boosting
الگوریتمهای محبوب تقویت از این قرار است:
- AdaBoost (Adaptive Boosting) :AdaBoost یکی از اولین الگوریتم های تقویت بود و هنوز هم یکی از محبوبترینهاست. AdaBoost بهطور انعطافپذیر وزن نمونهها را بهروز می کند تا تمرکز بیشتری بر نمونههای دشوار داشته باشد.
- Gradient Boosting :Gradient Boosting از رویکرد شیب نزولی برای بهروزرسانی وزن نمونهها استفاده میکند. این رویکرد به Gradient Boosting اجازه میدهد تا بهطور مؤثرتر بر اشتباههای مدلهای قبلی تمرکز کند.
- XGBoost (Extreme Gradient Boosting) :XGBoost یک الگوریتم تقویت پیشرفته است که از تکنیکهای مختلفی برای بهبود کارایی و دقت استفاده میکند. XGBoost بهدلیل عملکرد بالای خود در طیف گستردهای از مسائل یادگیری ماشین شناختهشده است.
Stacking: ترکیب مدلها برای پیشبینی دقیقتر
در دنیای یادگیری ماشین Stacking یک روش یادگیری گروهی است که برای بهبود دقت پیشبینی با ترکیب پیشبینیهای چندین مدل یادگیری متفاوت استفاده میشود. این روش براساس مفهوم استفاده از یک مدل متا (Meta Model) برای ترکیب پیشبینیهای مدلهای پایه (Base Models) استوار است.
مراحل Stacking
بهصورت کلی، مرحلههای Stacking از این قرار است:
- ایجاد مدلهای پایه: چندین مدل پایه، مانند درخت تصمیم، شبکه عصبی و دیگر روشها، روی دادههای آموزشی ساخته میشوند.
- پیشبینیهای مدلهای پایه: هر مدل پایه روی دادههای جدید پیشبینیهایی انجام میدهد.
- ایجاد مدل متا: یک مدل متا روی پیشبینیهای مدلهای پایه ساخته میشود. مدل متا وظیفه یادگیری رابطه میان پیشبینیهای مدلهای پایه و خروجی واقعی را دارد.
- پیشبینی نهایی: مدل متا از پیشبینیهای مدلهای پایه برای ایجاد پیشبینی نهایی استفاده میکند.
انجامدادن این مرحلهها میتواند دقت پیشبینی را با ترکیب پیشبینیهای چندین مدل یادگیری متفاوت بهبود دهد.
الگوریتمهای کلیدی Stacking
Blending یکی از الگوریتمهای Stacking است که از میانگین پیشبینیهای مدلهای پایه برای ایجاد پیشبینی نهایی استفاده میکند. Blending یک روش ساده و مؤثر است که بهطور گسترده استفاده میشود.
قسمتی از جزوه کلاس برای مبحث یادگیری گروهی
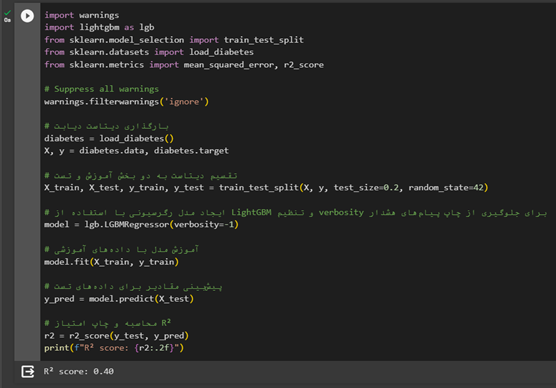
اجرای الگوریتم LightGBM از یادگیری گروهی در پایتون
جمعبندی الگوریتمهای یادگیری گروهی

پرسشهای متداول
چرا یادگیری گروهی (Ensemble Learning) در یادگیری ماشین اهمیت دارد؟
یادگیری گروهی، با ترکیب پیشبینیهای چندین مدل منفرد، خطاهای فردی مدلها را کاهش میدهد و به پیشبینیهای دقیقتر و قابل اطمینانتر میانجامد. این روش، بهویژه، در مواردی که دادههای آموزشی محدود یا ناقص هستند اهمیت پیدا میکند و به کاهش ریسک بیشبرازش (Overfitting) کمک شایانی میکند.
روشهای یادگیری گروهی مختلفی مانند Bagging، Boosting، و Stacking چگونه عمل میکنند؟
Bagging (Bootstrap Aggregation): چندین مدل پایه مشابه از زیرمجموعههای مختلف دادههای آموزشی ایجاد میشوند و پیشبینی نهایی با ترکیب پیشبینیهای مدلهای پایه انجام میشود.
Boosting: مدلهای پایه بهصورت متوالی ساخته میشوند و هر مدل جدید براساس اشتباههای مدل قبلی ساخته میشود تا دقت پیشبینی بهبود یابد.
Stacking: چندین مدل پایه برای پیشبینی یک هدف مشخص ساخته میشوند و سپس یک مدل متا برای ترکیب پیشبینیها استفاده میشود.
مزیتهای اصلی استفاده از یادگیری گروهی چیست و چه محدودیتهایی دارد؟
مزیتهای این مدل دقت پیشبینی بالاتر، کاهش ریسک بیشبرازش و بهبود تعمیمپذیری را شامل است. محدودیتها افزایش واریانس پیشبینی در برخی موارد، پیچیدگی محاسباتی بیشتر و نیاز به تنظیم دقیق پارامترها را دربرمیگیرد.
انواع مختلف یادگیری گروهی (همگن و ناهمگن) چه تفاوتهایی دارند؟
در یادگیری گروهی همگن مدلهای پایه از نوع یکسانی هستند، درحالیکه در یادگیری گروهی ناهمگن، مدلهای پایه از انواع مختلفی تشکیل شدهاند. این تفاوت در انتخاب مدلهای پایه و تنوع ایجادشده برجسته میشود و همچنین در استراتژیهای انتخاب مدل برای مسئلههای مختلف یادگیری ماشین تأثیر دارد.
الگوریتمهای محبوبی مانند AdaBoost ،Gradient Boosting و XGBoost چگونه به بهبود یادگیری گروهی کمک میکنند؟
AdaBoost (Adaptive Boosting): وزن نمونهها را بهروز میکند تا تمرکز بیشتری بر نمونههای دشوار داشته باشد.
Gradient Boosting: از رویکرد شیب نزولی برای بهروزرسانی وزن نمونهها و تمرکز بر اشتباههای مدلهای قبلی استفاده میکند.
XGBoost (Extreme Gradient Boosting): از تکنیکهای مختلفی برای بهبود کارایی و دقت استفاده میکند و در طیف گستردهای از مسئلههای یادگیری ماشین عملکرد بالایی دارد.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه تحصیلی و کاری، میتوانید حالا شروع کنید و از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
یادگیری گروهی چه مزایایی دارد؟
دقت پیشبینی بالاتر
کاهش ریسک بیشبرازش (Overfitting)
بهبود تعمیمپذیری (Generalization)
کاهش وابستگی به ویژگیها (Feature Dependency)
مزیتها و چالشهای روش Bagging چیست؟
دقت بالا: مجموعهسازی، با ترکیب پیشبینیهای چندین مدل، دقت کلی پیش بینی را بهبود میبخشد.
کاهش ریسک بیشبرازش: مجموعهسازی، با ایجاد تنوع میان مدلهای پایه، ریسک بیشآموزی را کاهش میدهد.
قابلیت اجرا برای انواع مدلها: مجموعهسازی را میتوان با انواع مختلفی از مدلهای پایه، ازجمله درخت تصمیم، شبکه عصبی و روشهای دیگر، استفاده کرد.
چالشهای روش مجموعهسازی از این قرار است: افزایش واریانس پیشبینی – پیچیدگی محاسباتی – نیاز به تنظیم پارامتر
روشهای Boosting و Stacking چه تفاوتهایی دارند؟
در یادگیری گروهی همگن مدلهای پایه از نوع یکسانی هستند، درحالیکه در یادگیری گروهی ناهمگن، مدلهای پایه از انواع مختلفی تشکیل شدهاند.
سوال ۳:
boosting:
مبتنی بر توالی: مدلهای پایه بهصورت متوالی ساخته میشوند. در هر مرحله مدل جدید براساس اشتباهات مدل قبلی ساخته میشود،
stacking:
مبتنی بر متا مدل: در آن چندین مدل پایه برای پیشبینی یک هدف مشخص ساخته میشوند و سپس از یک مدل متا برای ترکیب پیشبینیها استفاده میشود
سوال ۲:
مزیت:
دقت بالا: مجموعهسازی، با ترکیب پیشبینیهای چندین مدل، دقت کلی پیش بینی را بهبود میبخشد.
کاهش ریسک بیشبرازش: مجموعهسازی، با ایجاد تنوع میان مدلهای پایه، ریسک بیشآموزی را کاهش میدهد.
قابلیت اجرا برای انواع مدلها: مجموعهسازی را میتوان با انواع مختلفی از مدلهای پایه، ازجمله درخت تصمیم، شبکه عصبی و روشهای دیگر، استفاده کرد.
چالش:
افزایش واریانس پیشبینی: مجموعهسازی ممکن است به افزایش واریانس پیشبینی بینجامد، بهاین معنی که پیشبینیهای مدل ممکن است با هم متفاوت باشند.
پیچیدگی محاسباتی: مجموعهسازی میتواند از نظر محاسباتی فشرده باشد، بهخصوص هنگام استفاده از مدلهای پایه پیچیده، مانند شبکههای عصبی.
نیاز به تنظیم پارامتر: مجموعهسازی به تعدیل دقیق پارامترهایی مانند تعداد مدلهای پایه و روش ترکیب پیشبینیها نیاز دارد.
سوال۱:
دقت پیش بینی بالاتر
کاهش ریسک بیشبرازش
بهبود تعمیم پذیری
کاهش وابستگی به ویژگیها