
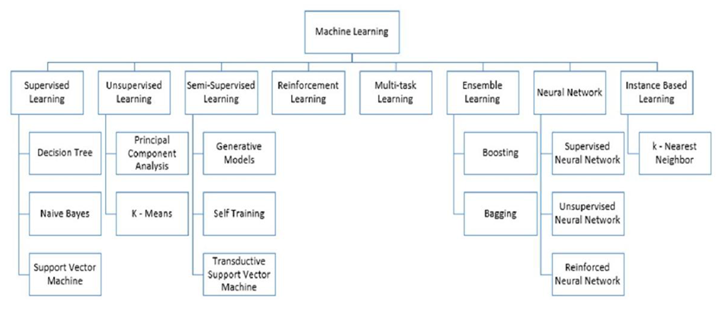
ماشین یادگیری (ML) مطالعه علمی الگوریتمها و مدلهای آماری است که سیستمهای کامپیوتری برای انجامدادن تسک خاصی بدون برنامهریزی صریح استفاده میکنند. الگوریتمهای یادگیری در بسیاری از برنامهها استفاده میشوند که ما روزانه از آنها استفاده میکنیم. هر زمان که از موتور جستوجوی وب، مانند گوگل، برای جستنوجو در اینترنت استفاده میشود، یکی از دلیلهای خوبکارکردن آن وجود یک الگوریتم یادگیری است که چگونگی رتبهبندی صفحات وب را یاد گرفته است. این الگوریتمها برای هدفهای مختلفی مانند استخراج داده، پردازش تصویر، تجزیهوتحلیل پیشبینی و غیره استفاده میشوند تا چند مورد را نام ببریم. مزیت اصلی استفاده از ماشین یادگیری این است که پس از آن که الگوریتم چگونگی کار با دادهها را یاد میگیرد میتواند کار خود را بهصورت خودکار انجام دهد. در این مطلب بهصورت مفصل الگوریتم های اصلی یادگیری ماشین را مقایسه کردهایم.
- 1. مقدمه
- 2. الگوریتم های یادگیری باناظر
- 3. الگوریتمهای یادگیری بدون ناظر
- 4. یادگیری نیمهنظارتی (Semi-supervised Learning)
- 5. یادگیری تقویتی (Reinforcement Learning)
- 6. یادگیری چند وظیفهای (Multitask Learning)
- 7. یادگیری گروهی (Ensemble Learning)
- 8. شبکههای عصبی (Neural Networks)
- 9. یادگیری مبتنی بر نمونه (Instance-Based Learning)
- 10. نتیجهگیری
-
11.
پرسشهای متداول
- 11.1. در یادگیری ماشین الگوریتمهای نظارتی و بدون نظارت چه تفاوتهای اصلی دارند؟
- 11.2. یادگیری تقویتی (Reinforcement Learning) چگونه از دیگر الگوریتمهای یادگیری متمایز میشود؟
- 11.3. چه زمانی باید از یادگیری ترکیبی (Ensemble Learning) استفاده کرد و اصلیترین مزیتهای آن چیست؟
- 11.4. در یادگیری چندوظیفهای (Multitask Learning) چگونه میتوانیم کارایی یادگیری را بهینه کنیم؟
- 11.5. در چه مواردی استفاده از شبکههای عصبی (Neural Networks) توصیه میشود و چه ویژگیهای منحصربهفردی دارند؟
- 12. یادگیری ماشین لرنینگ را از امروز شروع کنید!
مقدمه
براساس تعریف آرتور ساموئل، ماشین یادگیری بهعنوان زمینهای از مطالعه تعریف میشود که به رایانههای توانایی یادگیری بدون برنامهریزی صریح میدهد. آرتور ساموئل اعتقاد داشت که ماشین یادگیری براساس الگوریتمهای مختلف برای حل مشکلات دادهای وابسته است و دانشمندان داده معتقدند که الگوریتم منحصربهفرد برای همه مسائل وجود ندارد. نوع الگوریتم مورداستفاده وابسته به نوع مشکلی است که میخواهید حل کنید، تعداد متغیرها، نوع مدلی که با آن مناسب است و غیره. در این مقاله برخی از الگوریتمهای متداول ماشین یادگیری (ML) را مقایسه میکنیم.
الگوریتم های یادگیری باناظر
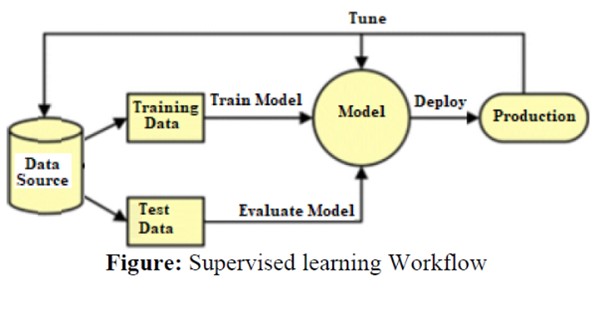
یادگیری باناظر یکی از مهمترین و رایجترین روشهای یادگیری ماشین است. در این نوع یادگیری الگوریتم با دادههایی آموزش میبیند که هر یک از آنها برچسب یا خروجی مشخصی دارند؛ بهعبارت دیگر، برای هر ورودی خروجی متناظر با آن در دسترس است و الگوریتم سعی میکند تابعی را یاد بگیرد که بتواند ورودیهای جدید را به خروجیهای متناظر تبدیل کند.
هدف اصلی در یادگیری نظارتی تعمیمپذیری است؛ بهاین معنا که ما میخواهیم مدلی را آموزش دهیم که نهتنها روی دادههای آموزشی خوب عمل کند، بتواند پیشبینیهای دقیقی را برای دادههای جدید و ناشناخته ارائه کند. در شکل زیر جریان روند انجامدادن کار در یادگیری باناظر را مشاهده میکنید؛ در ادامه نیز مهمترین الگوریتمهای یادگیری باناظر را بررسی میکنیم.
پیشنهاد میکنیم درباره یادگیری باناظر (Supervised Learning) هم مطالعه کنید.
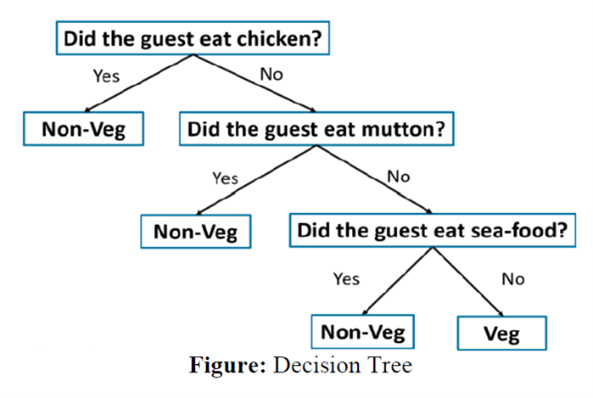
درخت تصمیم
درخت تصمیم نوعی نمودار است که بهمنظور نمایش گزینهها و نتیجههای آنها بهشکل یک درخت ارائه میشود. گرههای موجود در نمودار یک رویداد یا انتخاب را نشان میدهند و یالهای نمودار قوانین یا شرایط تصمیمگیری را نمایش میدهند. هر درخت از گرهها و شاخهها تشکیل شده است. هر گره نمایانگر ویژگیهایی در یک گروه است که قرار است دستهبندی شود و هر شاخه نمایانگر یک مقدار است که گره میتواند بپذیرد. شکل نشاندهنده ساختار درخت تصمیم است.
پیشنهاد میکنیم درباره معرفی درخت تصمیم یا Decision Tree هم مطالعه کنید.
بیز ساده
نایو بیز یا بیز ساده یک روش طبقهبندی است که براساس قانون بیز کار میکند و با فرضیه استقلال ویژگیها نسبت به یکدیگر طراحی شده است. بهطور سادهتر، این طبقهبندی فرض میکند که وجود یک ویژگی خاص در یک کلاس بههیچ وجه با دیگر ویژگیها ارتباط ندارد.
نایو بیز عمدتاً در صنعت طبقهبندی متون کاربرد دارد و برای هدفهای خوشهبندی و طبقهبندی استفاده میشود. Naïve Bayes مبتنی بر احتمال شرطی رویدادهاست.
پیشنهاد میکنیم درباره الگوریتم بیز ساده (Naïve Bayes) هم مطالعه کنید.
ماشین بردار پشتیبان
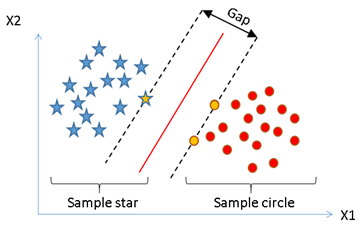
یکی دیگر از پرکاربردترین تکنیکهای ماشین یادگیری که بهطور گستردهای استفاده میشود، ماشین بردار پشتیبان (SVM) است. در ماشین یادگیری ماشینهای بردار پشتیبان مدلهای یادگیری نظارتی هستند که با الگوریتمهای یادگیری مرتبط دادهها را برای طبقهبندی و تحلیل رگرسیون بررسی میکنند.
علاوه بر انجامدادن طبقهبندی خطی، SVM میتواند بهطور کارآمد یک طبقهبندی غیرخطی با استفاده از چیزی که ترفند هسته نامیده میشود، انجام دهد و بهطور ضمنی ورودیهای خود را به فضاهای ویژگی با بعد بالا تبدیل کند. درواقع، این میان حاشیهها میان کلاسها رسم میکند. حاشیهها بهگونهای رسم میشوند که فاصله میان حاشیه و کلاسها حداکثر است و بنابراین خطای طبقهبندی را به حداقل میرساند.
پیشنهاد میکنیم درباره الگوریتم ماشین بردار پشتیبان (Support Vector Machine) هم مطالعه کنید.
الگوریتمهای یادگیری بدون ناظر
این نوع یادگیری را «بدون نظارت» مینامند؛ زیرا در مقایسه با یادگیری نظارتی که پیش از این گفتیم، پاسخهای صحیحی وجود ندارد و هیچ معلمی نیست. الگوریتمها بهتنهایی برای کشف و نمایش ساختار جالب در دادهها رها شدهاند. الگوریتمهای یادگیری بدون نظارت ویژگیهایی از دادهها را یاد میگیرند. وقتی دادههای جدید معرفی میشوند، از ویژگیهای قبلاً یادگرفتهشده برای شناسایی کلاس داده استفاده میکند. این نوع یادگیری عمدتاً برای خوشهبندی و کاهش ویژگی استفاده میشود.
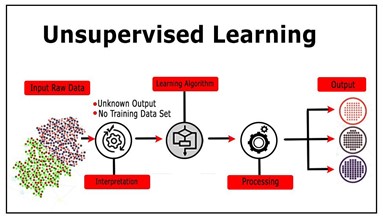
پیشنهاد میکنیم درباره یادگیری بدون ناظر (Unsupervised Learning) هم مطالعه کنید.
تحلیل مؤلفه اساسی یا PCA
الگوریتم تجزیه مؤلفههای اصلی یا PCA یکی از روشهای موجود در یادگیری ماشین برای کاهش ابعاد دادههاست. وقتی با دادههای با ابعاد بالا سروکار داریم، ممکن است با مشکلات مختلفی مانند «مشکل ابعاد بالا» مواجه شویم.
PCA به ما کمک میکند ویژگیهای اصلی دادهها را شناسایی و ابعاد غیرضروری یا تکراری را حذف کنیم. این الگوریتم ازطریق یافتن مؤلفههایی که بیشترین تغییرات (واریانس) را در دادهها نشان میدهند عمل میکند. بهاین ترتیب، PCA میتواند به ما کمک کند دادهها را با تعداد کمتری از ویژگیها نمایش دهیم، بدون آنکه اطلاعات مهمی از دست بروند.
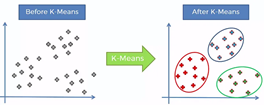
الگوریتم k-means
K-means یکی از سادهترین الگوریتمهای یادگیری بدون نظارت است که مشکل شناخته شده خوشهبندی را حل میکند. این روند بهروش ساده و آسانی دستهبندی مجموعه دادههای دادهشده را ازطریق تعداد معینی از خوشهها انجام میدهد.
ایده اصلی تعریف k مرکز است، یکی برای هر خوشه. باید این مراکز را بهطرز زیرکانهای قرار داد؛ زیرا مکانهای مختلف نتیجه متفاوتی ایجاد میکند. بنابراین بهترین انتخاب قراردادن آنهاست تا جای ممکن از یکدیگر دور باشند.
پیشنهاد میکنیم درباره معرفی الگوریتم K-means هم مطالعه کنید.
یادگیری نیمهنظارتی (Semi-supervised Learning)
یادگیری ماشین نیمهنظارتی ترکیبی از روشهای یادگیری ماشین نظارتی و بدون نظارت است. این روش در زمینههای یادگیری ماشین و کاوش دادهها میتواند مفید باشد، جایی که دادههای بدون برچسب قبلاً وجود دارد و فرایند برچسبزدن دادهها فرایندی خستهکننده است.
با روشهای متداول یادگیری ماشین نظارتی شما یک الگوریتم یادگیری ماشین را روی یک مجموعه داده برچسبدار آموزش میدهید که در آن هر رکورد شامل اطلاعات نتیجه است. برخی از الگوریتمهای یادگیری نیمهنظارتی در ادامه آنها را بررسی کردهایم.
پیشنهاد میکنیم درباره یادگیری نیمهنظارتی (Semi-supervised Learning) هم مطالعه کنید.
الگوریتم Transductive SVM
ماشینهای بردار پشتیبان ترانسداکتیو یا TSVM، یک روش در یادگیری نیمهنظارتی است. در این نوع یادگیری ما با دو نوع داده روبهرو هستیم: دادههایی که برچسب دارند و دادههایی که برچسب ندارند. هدف TSVM این است که دادههای بدون برچسب را با استفاده از اطلاعات دادههای برچسبدار برچسب بزند. این کار بهگونهای انجام میشود که فاصله یا حاشیه میان دستهها بیشینه شود.
با این ویژگی، TSVM میتواند با دقت بالا دادههای جدید را دستهبندی کند. اما باید توجه کرد که بهدلیل پیچیدگیهای محاسباتی، یافتن جواب دقیق برای TSVM گاهی میتواند چالشبرانگیز باشد.
مدلهای مولد (Generative Models)
مدلهای مولد در حوزه ماشین یادگیری نوعی از مدلها هستند که قابلیت شبیهسازی و تولید دادههای جدید را دارند؛ بهعبارت دیگر، این مدلها سعی میکنند تا ساختار و توزیع واقعی دادهها را یاد بگیرند تا بتوانند دادههای مشابه ولی تازهای تولید کنند؛ برای مثال، وقتی یک مدل مولد را با دادههای تصویری آموزش میدهیم، میتواند تصویرهای جدیدی را تولید کند که به نظر میآید واقعی هستند، اما واقعاً وجود ندارند.
یکی از ویژگیهای مهم این مدلها این است که هم ویژگیها و هم کلاسهای دادهها را مدل میکنند؛ بههمین دلیل، با داشتن توزیع احتمالP(x,y) ، میتوانیم نقاط داده جدیدی تولید کنیم. این خصوصیت به این میانجامد که مدلهای مولد در بسیاری از کاربردها، ازجمله تصویرسازی، تولید متن و بسیاری دیگر از حوزهها، استفاده شوند.
پیشنهاد میکنیم درباره مدل مولد یا Generative Model هم مطالعه کنید.
آموزش خودکار (Self-Training)
آموزش خودکار یک روش در ماشین یادگیری است که با استفاده از دادههای برچسبدار شروع میشود. در این روش ابتدا یک طبقهبندی با دادههای برچسبدار آموزش داده میشود. پس از آن، این طبقهبندی برای پیشبینی برچسبهای دادههای بدون برچسب استفاده میشود. نتایج پیشبینیشده سپس به مجموعه دادههای آموزشی اضافه میشوند و این فرایند چندین بار تکرار میشود. درواقع، ماشین با استفاده از دادههایی که پیشبینی کرده است آموزش میبیند؛ از این جهت به آن «آموزش خودکار» گفته میشود.
یادگیری تقویتی (Reinforcement Learning)
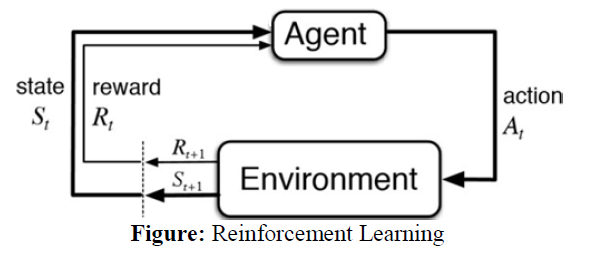
یادگیری تقویتی یکی از روشهای جذاب و مؤثر در حوزه یادگیری ماشین است که بر پایه تعامل با محیط تمرکز میکند. در این نوع یادگیری یک عامل (میتواند یک ربات، نرمافزار یا هر سیستم دیگری باشد) سعی میکند با انجامدادن اقدامات مختلف در یک محیط، پاداشهای بیشتری جمعآوری کند. هر اقدام میتواند به دریافت یک پاداش یا مجازات بینجامد؛ هدف عامل از انجامدادن هر اقدام هم بهینهسازی پاداشهای کلی است.
یکی از ویژگیهای متمایزکننده یادگیری تقویتی از دو نوع دیگر یادگیری ماشین (نظارتی و بدون نظارت) این است که در آن دادهها بهصورت برچسبدار وجود ندارد و عامل فقط ازطریق تجربه و تعامل با محیط یاد میگیرد؛ بههمین دلیل، یادگیری تقویتی در مواقعی که دسترسی به دادههای برچسبدار محدود است یا محیط به سرعت تغییر میکند بسیار مؤثر است.
برخی از کاربردهای عملی یادگیری تقویتی آموزش رباتها برای انجامدادن وظایف خاص، بهینهسازی استراتژیهای تجاری، طراحی سیستمهای توصیهگر و بازیهای کامپیوتری را شامل است. این شکل نحوه یادگیری این تقویتی را نشان میدهد:
پیشنهاد میکنیم درباره یادگیری تقویتی یا Reinforcement Learning هم مطالعه کنید.
یادگیری چند وظیفهای (Multitask Learning)
یادگیری چند وظیفهای یک زیرشاخه از یادگیری ماشین است که هدف آن حل چندین وظیفه مختلف بهطور همزمان است، با بهرهبرداری از شباهتهای موجود میان وظایف مختلف. این میتواند کارایی یادگیری را افزایش دهد و همچنین بهعنوان یک تنظیمکننده عمل کند. بهصورت رسمی، اگر n وظیفه وجود داشته باشد (رویکردهای یادگیری عمیق متداول تنها هدف دارند که ۱ وظیفه را با استفاده از ۱ مدل خاص حل کنند)، جایی که این n وظیفه یا یک زیرمجموعه از آنها به یکدیگر مرتبط اما دقیقاً مطابق نیستند، یادگیری چند وظیفهای (MTL) با استفاده از دانش موجود در همه n وظایف به بهبود یادگیری یک مدل خاص کمک خواهد کرد.
یادگیری گروهی (Ensemble Learning)
یادگیری ترکیبی فرایندی است که در آن چندین مدل، مانند کلاسبندها یا دیگر مدلهای یادگیری، بهطور استراتژیک تولید و ترکیب میشوند تا یک مسئله خاص هوش محاسباتی را حل کنند. اصلیترین استفاده از یادگیری ترکیبی بهبود عملکرد یک مدل است یا کاهش احتمال انتخاب یک مدل ضعیف. دیگر کاربردهای یادگیری ترکیبی شامل اختصاص اطمینان به تصمیم اتخاذشده توسط مدل، انتخاب ویژگیهای بهینه، ترکیب دادهها، یادگیری افزایشی، یادگیری غیرثابت و تصحیح خطاست.
پیشنهاد میکنیم درباره یادگیری گروهی در ماشین لرنینگ هم مطالعه کنید.
Boosting
واژه افزایشی یا Boosting به خانوادهای از الگوریتمها اشاره میکند که تبدیلکننده یادگیرنده ضعیف به یادگیرنده قوی است. افزایشی یک فن در یادگیری ترکیبی است که برای کاهش سوگیری و واریانس استفاده میشود. افزایشی بر پرسشی استوار است که Kearns و Valiant مطرح کردهاند: «آیا مجموعهای از یادگیرندههای ضعیف میتوانند یک یادگیرنده قوی ایجاد کنند؟»
Bagging
مجموعهسازی یا Bagging در جایی استفاده می شود که دقت و پایداری الگوریتم یادگیری ماشین به افزایش نیاز دارد. این روش در کلاسبندی و رگرسیون کاربرد دارد. همچنین مجموعهسازی واریانس را کاهش میدهد و به کنترل بیشازحد مناسب کمک میکند.
این روش، بهخصوص، در مدلهایی که حساس به نوسان دادهها هستند، مانند درخت تصمیم، بسیار مفید است.
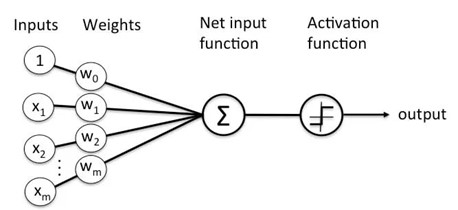
شبکههای عصبی (Neural Networks)
شبکههای عصبی، الهامگرفته از ساختار و عملکرد مغز انسان، به ما کمک میکنند تا الگوها و روابط پنهان در دادهها را کشف کنیم. این شبکهها از واحدهای پردازشی بهنام نورونها تشکیل شدهاند که میتوانند از نوع طبیعی یا مصنوعی باشند.
اصلیترین ویژگی شبکههای عصبی توانایی یادگیری و تطابق با دادههاست. بهوضوح، وقتی دادههای ورودی تغییر میکنند، شبکه، بدون نیاز به دخالت خارجی، بهروزرسانی میشود و نتایج بهتر و دقیقتری تولید میکند. این قابلیت شبکههای عصبی را ابزاری بینظیر در زمینههای مختلفی، مانند تشخیص الگو، پردازش زبان طبیعی و حتی در بازارهای مالی و سیستمهای معاملاتی، محبوب کرده است. این شکل ساختار شبکه عصبی را بهسادگی نشان میدهد:
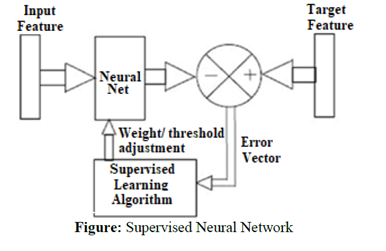
شبکههای عصبی باناظر (Supervised Neural Network)
در شبکههای عصبی نظارتی ما با دادههایی کار میکنیم که برچسبهای مشخصی دارند؛ بهعبارت دیگر، برای هر ورودی خروجی موردانتظار ما معلوم است. وقتی شبکه عصبی یک ورودی را پردازش میکند، خروجی پیشبینیشده توسط شبکه با خروجی واقعی (برچسب) مقایسه میشود. این اختلاف یا خطا سپس برای بهروزرسانی و تنظیم وزنها و پارامترهای دیگر شبکه استفاده میشود. این فرایند بهمرور زمان باعث میشود تا شبکه بهتر و دقیقتر عمل کند.
یکی از مدلهای رایج شبکه عصبی که از این نوع یادگیری استفاده میکند، شبکههای عصبی feed forward یا پیشرو است. در این مدلها اطلاعات فقط در یک جهت از ورودی به خروجی جریان دارد و هیچگونه حلقه بازگشتی وجود ندارد.
شبکه عصبی بدون نظارت (Unsupervised Neural Network)
شبکههای عصبی بدون نظارت به دستهای از مدلهای ماشین یادگیری گفته میشود که بدون داشتن اطلاعات قبلی یا برچسبهای مشخص برای ورودیها در یادگیری و کشف الگوها و ساختارهای پنهان در دادهها سعی میکند. در این نوع شبکهها هیچ سرنخ قبلی درمورد نوع خروجی وجود ندارد.
وظیفه اصلی این شبکهها دستهبندی دادهها یا خوشهبندی آنها براساس شباهتها و تفاوتهاست؛ برای مثال، ممکن است دادههایی با ویژگیهای مشابه به یک خوشه اختصاص پیدا کنند. شبکه عصبی بهطور خودکار همبستگی و روابط میان ورودیهای مختلف را بررسی میکند و بر این اساس آنها را گروهبندی میکند.
از مزیتهای استفاده از شبکههای عصبی بدون نظارت قابلیت کشف الگوها و ساختارهای پیچیده در مجموعه دادههای بزرگ و پیچیده است. این شبکهها میتوانند در مواردی که دادههای ما برچسب ندارند یا حجم بسیار زیادی از دادهها وجود دارد بسیار مفید باشند.
شبکه عصبی تقویتی (Reinforced Neural Network)
شبکههای عصبی تقویتی ترکیبی از دو مفهوم مهم در حوزه یادگیری ماشین هستند: شبکههای عصبی و یادگیری تقویتی. این شبکهها، با استفاده از قدرت محاسباتی شبکههای عصبی، مدلهای پیچیدهای را تربیت میکنند تا در محیطها و برای وظیفههای مختلف با موفقیت عمل کنند.
هدف اصلی یادگیری تقویتی استراتژیها یا سیاستهایی است که به بهحداکثررساندن پاداش کلی بینجامد. شبکه عصبی در اینجا نقش یک تابع تقریبزننده را دارد که به ما کمک میکند تا از دادهها و تجربههای گذشته یاد بگیریم.
مزیت اصلی استفاده از شبکههای عصبی در یادگیری تقویتی قابلیت پردازش اطلاعات پیچیده و دریافت نتیجههای دقیقتر در محیطهای با وضوح بالاست؛ بهعبارتی دیگر، با استفاده از شبکههای عصبی میتوانیم در محیطهایی با تعداد زیادی متغیر و پارامتر عملکرد بهتری داشته باشیم. شبکههای عصبی تقویتی در بسیاری از کاربردها، از بازیهای کامپیوتری گرفته تا خودروهای بدون راننده، بهخوبی عمل و نتیجههای بسیار قابلتوجهی ارائه کردهاند.

یادگیری مبتنی بر نمونه (Instance-Based Learning)
یادگیری مبتنی بر نمونه به خانوادهای از تکنیکها برای کلاسبندی و رگرسیون اشاره میکند که براساس شباهت پرسش به همسایههای نزدیکترین خود در مجموعه آموزش، یک برچسب یا پیشبینی کلاس تولید میکند. در مقایسه مستقیم با روشهای دیگر، مانند درختهای تصمیم و شبکههای عصبی، الگوریتمهای یادگیری مبتنی بر نمونه از نمونههای خاص خلاصهسازی نمیکنند؛ بهجای آن، آنها تمامی دادهها را ذخیره میکنند و در زمان پرسش، پاسخی را از بررسی همسایههای نزدیکترین پرسش مشتق میکنند.
k نزدیکترین همسایه
الگوریتم KNN (K-Nearest Neighbors) یک الگوریتم ساده و نظارتی ماشین یادگیری است که میتواند برای حل مسائل کلاسبندی و رگرسیون استفاده شود. اجرا و فهم آن آسان است، اما یک اشکال بزرگ دارد که با افزایش اندازه دادههای مورداستفاده، بهطور قابلتوجهی کند میشود.
پیشنهاد میکنیم درباره الگوریتم K نزدیک ترین همسایه (K-Nearest Neighbors) هم مطالعه کنید.
نتیجهگیری
ماشین یادگیری میتواند نظارتی یا بدون نظارت باشد. اگر مقدار کمتری از دادهها و دادههای برچسبدار واضح برای آموزش دارید، یادگیری نظارتی را انتخاب کنید. یادگیری بدون نظارت معمولاً عملکرد و نتیجههای بهتری برای مجموعههای بزرگ دادهها ارائه میکند. اگر مجموعه داده بزرگی بهراحتی در دسترس دارید، به تکنیکهای یادگیری عمیق مراجعه کنید.
شما همچنین یادگیری تقویتی و یادگیری تقویتی عمیق را یاد گرفتهاید. حالا میدانید شبکههای عصبی چیست و کاربردها و محدودیتهای آنها چیست. امروزه هر فردی، آگاهانه یا ناخودآگاه، از یادگیری ماشین استفاده میکند. از دریافت محصول توصیهشده در خرید آنلاین تا بهروزرسانی تصاویر در وبسایتهای اجتماعی.

پرسشهای متداول
در یادگیری ماشین الگوریتمهای نظارتی و بدون نظارت چه تفاوتهای اصلی دارند؟
الگوریتمهای نظارتی (Supervised Learning) با استفاده از دادههای برچسبدار کار میکنند و سعی در پیشبینی خروجی برای ورودیهای جدید دارند؛ درمقابل، الگوریتمهای بدون نظارت (Unsupervised Learning) برچسبهای مشخصی ندارند و روی کشف ساختارهای پنهان در دادهها تمرکز دارند، مانند خوشهبندی دادهها با استفاده از K-Means یا کاهش ابعاد با PCA.
یادگیری تقویتی (Reinforcement Learning) چگونه از دیگر الگوریتمهای یادگیری متمایز میشود؟
یادگیری تقویتی براساس تعامل با محیط و بهینهسازی پاداشها کار میکند. این روش، برخلاف یادگیری نظارتی و بدون نظارت،، دادههای برچسبدار ندارد و بیشتر بر تجربه و تعامل با محیط تمرکز میکند. یادگیری تقویتی در مواردی که مدل به تصمیمگیریهای پیچیده نیاز دارد، مانند بازیهای کامپیوتری یا سیستمهای خودران، بسیار کاربردی است.
چه زمانی باید از یادگیری ترکیبی (Ensemble Learning) استفاده کرد و اصلیترین مزیتهای آن چیست؟
یادگیری ترکیبی زمانی کاربرد دارد که به دنبال بهبود دقت و کاهش خطا در مدلهای یادگیری ماشین هستیم. این روش با ترکیب چندین مدل مختلف، به کاهش واریانس و سوگیری کمک میکند و عملکرد کلی مدل را افزایش میدهد. تکنیکهای معروف در این حوزه Bagging و Boosting هستند.
در یادگیری چندوظیفهای (Multitask Learning) چگونه میتوانیم کارایی یادگیری را بهینه کنیم؟
در یادگیری چندوظیفهای بهرهبرداری از شباهتها و تفاوتها میان وظیفهها میتواند کارایی یادگیری را افزایش دهد. مدلهایی که قابلیت اشتراک گذاری پارامترها میان وظایف مختلف را دارند، میتوانند بر یادگیری هر وظیفه بهصورت همزمان موثر باشند.
در چه مواردی استفاده از شبکههای عصبی (Neural Networks) توصیه میشود و چه ویژگیهای منحصربهفردی دارند؟
شبکههای عصبی، بهدلیل قابلیت تقریب هر تابعی، برای مسائل پیچیده و دادههای بزرگ، مانند تصویربرداری و زبان طبیعی، توصیه میشوند. ویژگیهای منحصربهفرد آنها قابلیت یادگیری عمیق از دادهها، خودسازماندهی و تطابق با تغییرات در ورودیها را شامل است. این شبکهها میتوانند روابط پیچیده و غیرخطی را در دادهها تشخیص دهند و برای حل مسائل متنوعی از تشخیص تصویر گرفته تا پردازش زبان طبیعی مفید هستند.
یادگیری ماشین لرنینگ را از امروز شروع کنید!
دنیای دادهها جذاب است و دانستن علم داده، توانایی تحلیل داده یا بازاریابی مبتنی بر داده شما را برای فرصتهای شغلی بسیاری مناسب میکند. فارغ از رشته و پیشزمینه تحصیلی و شغلیتان، میتوانید همین حالا یادگیری دیتا ساینس را شروع کنید و این دانش را از سطح مقدماتی تا پیشرفته بیاموزید. اگر دوست دارید به این حوزه وارد شوید، پیشنهاد میکنیم با کلیک روی این لینک قدم اول را همین حالا بردارید.
مشاوران کافهتدریس به شما کمک میکنند مسیر یادگیری برای ورود به این حوزه را شروع کنید:
در زمینه یادگیری تقویتی، الگوریتم Transductive SVM چگونه عمل میکند؟
ماشینهای بردار پشتیبان ترانسداکتیو یا TSVM، یک روش در یادگیری نیمهنظارتی است. در این نوع یادگیری ما با دو نوع داده روبهرو هستیم: دادههایی که برچسب دارند و دادههایی که برچسب ندارند. هدف TSVM این است که دادههای بدون برچسب را با استفاده از اطلاعات دادههای برچسبدار برچسب بزند. این کار بهگونهای انجام میشود که فاصله یا حاشیه میان دستهها بیشینه شود.
با این ویژگی، TSVM میتواند با دقت بالا دادههای جدید را دستهبندی کند. اما باید توجه کرد که بهدلیل پیچیدگیهای محاسباتی، یافتن جواب دقیق برای TSVM گاهی میتواند چالشبرانگیز باشد.
یادگیری گروهی (Ensemble Learning) چه مزایایی نسبت به استفاده از یک الگوریتم یادگیری ماشین به تنهایی دارد؟
یادگیری ترکیبی زمانی کاربرد دارد که به دنبال بهبود دقت و کاهش خطا در مدلهای یادگیری ماشین هستیم. این روش با ترکیب چندین مدل مختلف، به کاهش واریانس و سوگیری کمک میکند و عملکرد کلی مدل را افزایش میدهد.
یادگیری تقویتی چگونه از سایر روشهای یادگیری ماشین متمایز میشود؟
یادگیری تقویتی براساس تعامل با محیط و بهینهسازی پاداشها کار میکند. این روش، برخلاف یادگیری نظارتی و بدون نظارت،، دادههای برچسبدار ندارد و بیشتر بر تجربه و تعامل با محیط تمرکز میکند. یادگیری تقویتی در مواردی که مدل به تصمیمگیریهای پیچیده نیاز دارد، مانند بازیهای کامپیوتری یا سیستمهای خودران، بسیار کاربردی است.
سوال ۳:
یادگیری تقویتی براساس تعامل با محیط و بهینهسازی پاداشها کار میکند. این روش، برخلاف یادگیری نظارتی و بدون نظارت،، دادههای برچسبدار ندارد و بیشتر بر تجربه و تعامل با محیط تمرکز میکند. یادگیری تقویتی در مواردی که مدل به تصمیمگیریهای پیچیده نیاز دارد، مانند بازیهای کامپیوتری یا سیستمهای خودران، بسیار کاربردی است.
سوال۲
یادگیری ترکیبی فرایندی است که در آن چندین مدل، مانند کلاسبندها یا دیگر مدلهای یادگیری، بهطور استراتژیک تولید و ترکیب میشوند تا یک مسئله خاص هوش محاسباتی را حل کنند. اصلیترین استفاده از یادگیری ترکیبی بهبود عملکرد یک مدل است یا کاهش احتمال انتخاب یک مدل ضعیف
یادگیری ترکیبی شامل اختصاص اطمینان به تصمیم اتخاذشده توسط مدل، انتخاب ویژگیهای بهینه، ترکیب دادهها، یادگیری افزایشی، یادگیری غیرثابت و تصحیح خطاست.
سوال۱
هدف TSVM این است که دادههای بدون برچسب را با استفاده از اطلاعات دادههای برچسبدار برچسب بزند. این کار بهگونهای انجام میشود که فاصله یا حاشیه میان دستهها بیشینه شود.
با این ویژگی، TSVM میتواند با دقت بالا دادههای جدید را دستهبندی کند.
سوال اول
یادگیری تقویتی براساس تعامل با محیط و بهینهسازی پاداشها کار میکند.
سوال دوم
این روش فرایندی است که در آن چندین مدل، مانند کلاسبندها یا دیگر مدلهای یادگیری، بهطور استراتژیک تولید و ترکیب میشوند تا یک مسئله خاص هوش محاسباتی را حل کنند.
سوال سوم
یادگیری تقویتی براساس تعامل با محیط و بهینهسازی پاداشها کار میکند. این روش، برخلاف یادگیری نظارتی و بدون نظارت،، دادههای برچسبدار ندارد و بیشتر بر تجربه و تعامل با محیط تمرکز میکند. یادگیری تقویتی در مواردی که مدل به تصمیمگیریهای پیچیده نیاز دارد، مانند بازیهای کامپیوتری یا سیستمهای خودران، بسیار کاربردی است.